






注:最近打算将UFLDL教程重新看一遍,其实里面有很多关于神经网络以及深度学习的知识点很有用,但是只是学习深度学习的话有一些内容就有点多余,所以想整理一个笔记,记录下神经网络到深度学习的一些知识点。整个教材已经非常好,网上有原版的英文版,也有翻译的中文版,这个只是自己的学习笔记,对原来教程中的内容进行了梳理,有些图也是引用的原来的教程,若内容上有任何错误,希望与我联系,若内容有侵权,同样也希望告知,我会尽快删除。
这个笔记主要分为以下几个部分:
- 神经网络
- 自编码器与稀疏性
- Softmax回归
- 自我学习
- 深度网络
- 其他,如PCA
五、深度网络
1、深度网络的概述
前面的网络形式最多是三层的网络结构,即输入层,一个隐含层和一个输出层,这是一个“浅”层的网络结构。
网络结构中的“浅”值的是隐藏层的个数,即特征生成的网络层数。
我们知道,每一个隐藏层可以对上一层的输出进行非线性变换,这样,每增加一个隐藏层就可以计算出更加复杂的特征表示,那么,使用“深”层的神经网络将会比使用“浅”具有更好的表达能力。
使用深度网络最主要的优势在于:它能以更加紧凑的方式来表达比浅层网络大得多的函数集合。这样,对于图像,就能够学习到“部分-整体”的分解关系。深度网络是一种层次的网络结构模型。
但是简单的增加网络中隐含层的数量对于训练整个网络模型具有一定的难度,主要表现在:
- 带标签样本数据的获取。对于带标签的样本是非常稀缺的。
- 局部极值的问题。对于深度网络,其误差函数是一个高度非凸的函数,具有很多的局部极值。
- 梯度弥散的问题。利用梯度法求解最优解时,在误差的反向传播的过程中,梯度会变得急剧减小。这就造成了整体的损失函数相对最初的几层的权重的导数非常小。这样,最初几层的权重变化非常缓慢。
通常对于深度网络,可采用逐层贪婪的训练方法,即每次训练一个只包含一个隐层的网络,训练完成后再训练下一个隐层,依次类推下去。在每一层的训练过程中,可以使用有监督的训练方法,也可以使用无监督的训练方法。最终将逐层训练得到的参数用来初始化整个网络的权重,最后对整个网络进行“微调”。
对于逐层训练的方法,主要有两方面的好处:
- 可以使用无监督的训练方法,相比较有监督的训练方法,数据较为容易获取。
- 可以获得更好的局部极值,因为在初始化的过程中,生成的权重已经在较好的位置上,微调可以较容易的获得较好的局部极值。
2、栈式自编码神经网络
2.1、栈式自编码神经网络的结构
自编码器的结构如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rtPEDcfj-1650777583595)(http://i.imgur.com/mTUikeF.jpg)]
栈式自编码神经网络是由多层稀疏自编码器组成的神经网络模型,即前一个自编码器的输出作为后一个自编码器的输入。假设有一个 n n n层栈式自编码神经网络,假定 W ( k , 1 ) , W ( k , 2 ) , b ( k , 1 ) , b ( k , 2 ) \mathbf{W}^{(k,1)},\mathbf{W}^{(k,2)},\mathbf{b}^{(k,1)},\mathbf{b}^{(k,2)} W(k,1),W(k,2),b(k,1),b(k,2)表示的是第 k k k个自编码器对应的权重和偏置,对于栈式自编码神经网络主要可以分为两个过程:
- 编码阶段。即信息从前向后传播:
a ( l ) = f ( z ( l ) ) z ( l + 1 ) = W ( l , 1 ) a ( l ) + b ( l , 1 ) \begin{matrix} \mathbf{a}^{(l)}=f\left ( \mathbf{z}^{(l)} \right )\\ \mathbf{z}^{(l+1)}=\mathbf{W}^{(l,1)}\mathbf{a}^{(l)}+\mathbf{b}^{(l,1)} \end{matrix} a(l)=f(z(l))z(l+1)=W(l,1)a(l)+b(l,1)
- 解码阶段。即信息从后向前传播
a ( n + l ) = f ( z ( n + l ) ) z ( n + l + 1 ) = W ( n − l , 2 ) a ( n + l ) + b ( n − l , 2 ) \begin{matrix} \mathbf{a}^{(n+l)}=f\left ( \mathbf{z}^{(n+l)} \right )\\ \mathbf{z}^{(n+l+1)}=\mathbf{W}^{(n-l,2)}\mathbf{a}^{(n+l)}+\mathbf{b}^{(n-l,2)} \end{matrix} a(n+l)=f(z(n+l))z(n+l+1)=W(n−l,2)a(n+l)+b(n−l,2)
这样, a ( n ) \mathbf{a}^{(n)} a(n)便是最深的隐藏单元的激活值,该值表示对特征的更高的抽象,可以将该值作为分类器的特征,将栈式自编码神经网络应用于分类中。
2.2、栈式自编码神经网络的训练过程
对于深度网络可以采用逐层贪婪的训练方式,则对于栈式自编码神经网络的训练同样可以选择采用逐层贪婪的训练方式,即先利用输入的特征训练栈式自编码神经网络的第一层,即第一个自编码器,得到权重和偏置 W ( 1 , 1 ) , W ( 1 , 2 ) , b ( 1 , 1 ) , b ( 1 , 2 ) \mathbf{W}^{(1,1)},\mathbf{W}^{(1,2)},\mathbf{b}^{(1,1)},\mathbf{b}^{(1,2)} W(1,1),W(1,2),b(1,1),b(1,2),然后将第一层的隐含层的激活值,即第一个自编码器的隐含层的输出,记为$\Lambda 作 为 第 二 层 , 即 第 二 个 自 编 码 器 的 输 入 , 训 练 出 第 二 个 自 编 码 器 的 权 重 和 偏 置 作为第二层,即第二个自编码器的输入,训练出第二个自编码器的权重和偏置 作为第二层,即第二个自编码器的输入,训练出第二个自编码器的权重和偏置\mathbf{W}{(2,1)},\mathbf{W}{(2,2)},\mathbf{b}{(2,1)},\mathbf{b}{(2,2)}$,依次下去,便可以训练出栈式自编码神经网络中的参数。在整个过程中,训练下一层的时候回保持上一层的参数不变,最后,在完成了网络中参数的初始化后,需要对参数进行“微调”。
下面以分类为例,对整个训练过程进行描述,首先将原始的输入 x ( k ) \mathbf{x}^{(k)} x(k)作为输入训练第一个自编码神经网络,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1xYlMmPF-1650777583596)(http://i.imgur.com/9SPsauM.jpg)]
此时,对于每一个训练样本 x ( k ) \mathbf{x}^{(k)} x(k)便能得到其隐含层的输出 h ( 1 ) ( k ) \mathbf{h}^{(1)(k)} h(1)(k),将这个隐含层的输出作为第二个自编码器的输入,继续训练第二个自编码器,可以由下图表示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZpBKTPAT-1650777583596)(http://i.imgur.com/Jo1xmNg.jpg)]
此时,可以得到第二个自编码器的隐含层的输出 h ( 2 ) ( k ) \mathbf{h}^{(2)(k)} h(2)(k),称第一个自编码器的隐含层的输出 h ( 1 ) ( k ) \mathbf{h}^{(1)(k)} h(1)(k)为一阶特征,称第二个自编码器的隐含层的输出 h ( 2 ) ( k ) \mathbf{h}^{(2)(k)} h(2)(k)为二阶特征。为了进行分类,此时可以将二阶特征 h ( 2 ) ( k ) \mathbf{h}^{(2)(k)} h(2)(k)作为Softmax回归的输入进行训练,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZnE2m2qs-1650777583597)(http://i.imgur.com/9sbVIp0.jpg)]
将整个过程连接在一起便可以由下图表示出来:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kSSea4jm-1650777583598)(http://i.imgur.com/bePjLTJ.jpg)]
栈式自编码神经网络具有强大的表达能力,这主要得益于其层次的特征表示。通过一层一层的特征学习,可以学习到特征之间的层次结构。在上述的自编码神经网络的分类中,可以丢弃第二个自编码器的“解码”过程,直接将隐含层的输出作为Softmax回归的输入。
2.3、栈式自编码器的微调过程
微调是深度学习的一种策略,可以提高栈式自编码神经网络的性能。在微调的过程中,将整个栈式自编码神经网络的所有层都看成一个模型,统一对模型中的参数进行修正的过程。
进行全局微调的通用的方式是对误差进行反向传播,利用前面在神经网络中的推导:
- 对于输出层 n l n_l nl上的神经元 i i i,其残差为:
δ i ( n l ) = ∂ ∂ z i n l J ( W , b ; x , y ) = ∂ ∂ z i n l 1 2 ∥ y − h W , b ( x ) ∥ 2 = ∂ ∂ z i n l 1 2 ∑ i = 1 s n l ∥ y i − a i n l ∥ 2 = ( y i − a i n l ) ⋅ ( − 1 ) ⋅ ∂ ∂ z i n l a i n l = − ( y i − a i n l ) ⋅ f ′ ( z i n l ) \begin{matrix} \delta _i^{(n_l)}=\frac{\partial }{\partial z_i^{n_l}}J\left ( \mathbf{W},\mathbf{b};\mathbf{x},y \right )\\ =\frac{\partial }{\partial z_i^{n_l}}\frac{1}{2}\left \| y-h_{\mathbf{W},\mathbf{b}}\left ( \mathbf{x} \right ) \right \|^2\\ =\frac{\partial }{\partial z_i^{n_l}}\frac{1}{2}\sum_{i=1}^{s_{n_l}}\left \| y_i-a_i^{n_l} \right \|^2\\ =\left ( y_i-a_i^{n_l} \right )\cdot \left ( -1 \right )\cdot \frac{\partial}{\partial z_i^{n_l}}a_i^{n_l}\\ =-\left ( y_i-a_i^{n_l} \right )\cdot {f}'\left ( z_i^{n_l} \right ) \end{matrix} δi(nl)=∂zinl∂J(W,b;x,y)=∂zinl∂21∥y−hW,b(x)∥2=∂zinl∂21∑i=1snl∥yi−ainl∥2=(yi−ainl)⋅(−1)⋅∂zinl∂ainl=−(yi−ainl)⋅f′(zinl)
-对于非输出层,即对于 l = n l − 1 , n l − 2 , ⋯ , 2 l=n_{l-1},n_{l-2},\cdots ,2 l=nl−1,nl−2,⋯,2各层,第 l l l层的残差的计算方法如下(以第 n l − 1 n_{l-1} nl−1层为例):
δ i ( n l − 1 ) = ∂ ∂ z i n l − 1 J ( W , b ; x , y ) = ∂ ∂ z i n l − 1 1 2 ∥ y − h W , b ( x ) ∥ 2 = ∂ ∂ z i n l − 1 1 2 ∑ j = 1 s n l ∥ y j − a j n l ∥ 2 = 1 2 ∑ j = 1 s n l ∂ ∂ z i n l − 1 ∥ y j − a j n l ∥ 2 = 1 2 ∑ j = 1 s n l ∂ ∂ z j n l ∥ y j − a j n l ∥ 2 ⋅ ∂ ∂ z i n l − 1 z j n l = ∑ j = 1 s n l δ j ( n l ) ⋅ ∂ ∂ z i n l − 1 z j n l = ∑ j = 1 s n l ( δ j ( n l ) ⋅ ∂ ∂ z i n l − 1 ∑ k = 1 s n l − 1 f ( z k n l − 1 ) ⋅ W j k n l − 1 ) = ∑ j = 1 s n l ( δ j ( n l ) ⋅ W j i n l − 1 ⋅ f ′ ( z k n l − 1 ) ) = ( ∑ j = 1 s n l δ j ( n l ) ⋅ W j i n l − 1 ) ⋅ f ′ ( z k n l − 1 ) \begin{matrix} \delta _i^{(n_{l-1})}=\frac{\partial }{\partial z_i^{n_{l-1}}}J\left ( \mathbf{W},\mathbf{b};\mathbf{x},y \right )\\ =\frac{\partial }{\partial z_i^{n_{l-1}}}\frac{1}{2}\left \| y-h_{\mathbf{W},\mathbf{b}}\left ( \mathbf{x} \right ) \right \|^2\\ =\frac{\partial }{\partial z_i^{n_{l-1}}}\frac{1}{2}\sum_{j=1}^{s_{n_l}}\left \| y_j-a_j^{n_l} \right \|^2\\ =\frac{1}{2}\sum_{j=1}^{s_{n_l}}\frac{\partial }{\partial z_i^{n_{l-1}}}\left \| y_j-a_j^{n_l} \right \|^2\\ =\frac{1}{2}\sum_{j=1}^{s_{n_l}}\frac{\partial }{\partial z_j^{n_{l}}}\left \| y_j-a_j^{n_l} \right \|^2\cdot \frac{\partial }{\partial z_i^{n_{l-1}}}z_j^{n_{l}}\\ =\sum_{j=1}^{s_{n_l}}\delta _j^{(n_l)}\cdot \frac{\partial }{\partial z_i^{n_{l-1}}}z_j^{n_{l}}\\ =\sum_{j=1}^{s_{n_l}}\left ( \delta _j^{(n_l)}\cdot \frac{\partial }{\partial z_i^{n_{l-1}}}\sum_{k=1}^{s_{n_{l-1}}}f\left ( z_k^{n_{l-1}} \right )\cdot W_{jk}^{n_{l-1}} \right )\\ =\sum_{j=1}^{s_{n_l}}\left ( \delta _j^{(n_l)}\cdot W_{ji}^{n_{l-1}}\cdot {f}'\left ( z_k^{n_{l-1}} \right )\right )\\ =\left (\sum_{j=1}^{s_{n_l}} \delta _j^{(n_l)}\cdot W_{ji}^{n_{l-1}}\right )\cdot {f}'\left ( z_k^{n_{l-1}} \right ) \end{matrix} δi(nl−1)=∂zinl−1∂J(W,b;x,y)=∂zinl−1∂21∥y−hW,b(x)∥2=∂zinl−1∂21∑j=1snl∥∥yj−ajnl∥∥2=21∑j=1snl∂zinl−1∂∥∥yj−ajnl∥∥2=21∑j=1snl∂zjnl∂∥∥yj−ajnl∥∥2⋅∂zinl−1∂zjnl=∑j=1snlδj(nl)⋅∂zinl−1∂zjnl=∑j=1snl(δj(nl)⋅∂zinl−1∂∑k=1snl−1f(zknl−1)⋅Wjknl−1)=∑j=1snl(δj(nl)⋅Wjinl−1⋅f′(zknl−1))=(∑j=1snlδj(nl)⋅Wjinl−1)⋅f′(zknl−1)
因此有:
δ i ( l ) = ( ∑ j = 1 s l + 1 δ j ( l + 1 ) ⋅ W j i ( l ) ) ⋅ f ′ ( z i ( l ) ) \delta _i^{(l)}=\left (\sum_{j=1}^{s_{l+1}} \delta _j^{(l+1)}\cdot W_{ji}^{(l)}\right )\cdot {f}'\left ( z_i^{(l)} \right ) δi(l)=(j=1∑sl+1δj(l+1)⋅Wji(l))⋅f′(zi(l))
对于栈式自编码神经网络中的权重和偏置的更新公式为:
∂ ∂ W i j ( l ) J ( W , b ; x , y ) = a j ( l ) δ i ( l + 1 ) \frac{\partial }{\partial W_{ij}^{(l)}}J\left ( \mathbf{W},\mathbf{b};\mathbf{x},y \right )=a_j^{(l)}\delta _i^{(l+1)} ∂Wij(l)∂J(W,b;x,y)=aj(l)δi(l+1)
∂ ∂ b i ( l ) J ( W , b ; x , y ) = δ i ( l + 1 ) \frac{\partial }{\partial b_{i}^{(l)}}J\left ( \mathbf{W},\mathbf{b};\mathbf{x},y \right )=\delta _i^{(l+1)} ∂bi(l)∂J(W,b;x,y)=δi(l+1)
3、线性解码器
对于稀疏自编码器,通常包含 3 3 3层,即输入层,隐含层和输出层,然而对于输出层,其计算公式为:
z ( 3 ) = W ( 2 ) a ( 2 ) + b ( 2 ) a ( 3 ) = f ( z ( 3 ) ) \begin{matrix} \mathbf{z}^{(3)}=\mathbf{W}^{(2)}\mathbf{a}^{(2)}+\mathbf{b}^{(2)}\\ \mathbf{a}^{(3)}=f\left ( \mathbf{z}^{(3)} \right ) \end{matrix} z(3)=W(2)a(2)+b(2)a(3)=f(z(3))
其中, a ( 3 ) \mathbf{a}^{(3)} a(3)是输出, f f f称为激活函数,在稀疏自编码器中,隐含层和输出层使用的是相同的激活函数,如Sigmoid函数或者tanh函数,我们的目标是使得输出 a ( 3 ) \mathbf{a}^{(3)} a(3)尽可能接近 a ( 1 ) = x \mathbf{a}^{(1)}=\mathbf{x} a(1)=x。
若在输出层使用Sigmoid函数作为其激活函数,这样,输出值 a ( 3 ) \mathbf{a}^{(3)} a(3)的范围被限制在 [ 0 , 1 ] \left [ 0,1 \right ] [0,1],这样便限制了稀疏自编码器的输入也必须在 [ 0 , 1 ] \left [ 0,1 \right ] [0,1]。为了解决这样的问题,可以在输出层使用线性激活函数。
在输出层使用如下的恒等式:
f ( z ) = z f\left ( \mathbf{z} \right )=\mathbf{z} f(z)=z
于是有:
a ( 3 ) = f ( z ( 3 ) ) = z ( 3 ) a^{(3)}=f\left ( \mathbf{z}^{(3)} \right )=\mathbf{z}^{(3)} a(3)=f(z(3))=z(3)
称这样的激活函数为线性激活函数。
在隐含层使用Sigmoid函数或者tanh函数,而在输出层使用线性激活函数,这样的自编码器称为线性解码器。
使用线性函数作为输出层的激活函数,这样就能解决输入值是实值的问题,而不需要规定输入数据的所属范围。
对于自编码器的输出层的残差公式为:
δ i ( 3 ) = ∂ ∂ z i 1 2 ∥ y − a ( 3 ) ∥ 2 = − ( y i − a i ( 3 ) ) ⋅ f ′ ( z i ( 3 ) ) \delta _i^{(3)}=\frac{\partial }{\partial z_i}\frac{1}{2}\left \| y-\mathbf{a}^{(3)} \right \|^2=-(y_i-a_i^{(3)})\cdot {f}'\left ( z_i^{(3)} \right ) δi(3)=∂zi∂21∥∥∥y−a(3)∥∥∥2=−(yi−ai(3))⋅f′(zi(3))
若使用的是线性的激活函数,此时 f ′ ( z i ( 3 ) ) = 1 {f}'\left ( z_i^{(3)} \right )=1 f′(zi(3))=1,则输出层的残差公式为:
δ i ( 3 ) = ∂ ∂ z i 1 2 ∥ y − a ( 3 ) ∥ 2 = − ( y i − a i ( 3 ) ) \delta _i^{(3)}=\frac{\partial }{\partial z_i}\frac{1}{2}\left \| y-\mathbf{a}^{(3)} \right \|^2=-(y_i-a_i^{(3)}) δi(3)=∂zi∂21∥∥∥y−a(3)∥∥∥2=−(yi−ai(3))
而对于隐含层,其残差公式为:
δ i ( 2 ) = ( ∑ j = 1 s 3 δ j ( 3 ) ⋅ W j i ( 2 ) ) ⋅ f ′ ( z i ( 2 ) ) \delta _i^{(2)}=\left ( \sum_{j=1}^{s_3}\delta _j^{(3)}\cdot W_{ji}^{(2)} \right )\cdot {f}'\left ( z_i^{(2)} \right ) δi(2)=(j=1∑s3δj(3)⋅Wji(2))⋅f′(zi(2))
这里的 f f f依然是Sigmoid函数或者tanh函数。
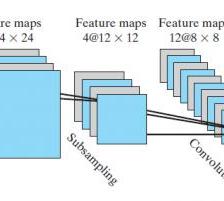
4、卷积神经网络
前面介绍的神经网络模型都是全连接的网络,全连接是指当前层的每一个节点与前一层的所有节点之间都存在着相连的边。对于输入节点而言,若输入节点的个数较少,那么利用全连接的方式影响并不是太大,若是输入节点的个数变得很多,此时利用全连接的方式,需要学习的参数会变得特别多,举个简单的例子,如上面的自编码器,输入层是 6 6 6个输入节点和一个偏置节点,隐含层是 4 4 4个隐层节点,此时需要训练的参数个数是 4 ∗ 6 + 4 = 28 4*6+4=28 4∗6+4=28个参数,若此时增加到12个输入节点,隐含层的节点个数不变,此时需要训练的参数个数为 4 ∗ 12 + 4 = 52 4*12+4=52 4∗12+4=52个参数,需要训练的个数急剧扩大。
为了解决这样的问题,可以对隐含单元和输入单元之间加上限制条件:每个隐含单元仅仅只和一部分的输入单元相连接。
以上的思想称为部分连接,也称为稀疏连接,部分连接的思想受启发于生物学里面的视觉系统结构。视觉皮层的神经元是局部接受信息的。
4.1、卷积神经网络的卷积操作
自然图像有一个性质:一部分的统计特性与其他部分是一样的。
利用这样的性质,可以将一部分学习的特征应用在另一部分上。为了获得卷积特征,需要对一部分的数据进行卷积运算,具体过程如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-du3D49VN-1650777583598)(http://i.imgur.com/fvTB426.gif)]
在上图中,原本的image是 5 × 5 5\times 5 5×5,每次选取 3 × 3 3\times 3 3×3大小的小块区域进行卷积计算。得到右边的卷积特征。
假设对于图像 X X X,其大小为 r × c r\times c r×c,定义小块区域的大小,如 a × b a\times b a×b,对小的区域做卷积,得到 k k k个特征,其中卷积为:
f = σ ( W x + b ) f=\sigma \left ( \mathbf{W}\mathbf{x}+\mathbf{b} \right ) f=σ(Wx+b)
其中,这里的激活函数可以是线性激活函数也可以是 S S S型激活函数。这样,经过卷积之后,得到的特征的个数是 k × ( r − a + 1 ) × ( c − b + 1 ) k\times \left ( r-a+1 \right )\times \left ( c-b+1 \right ) k×(r−a+1)×(c−b+1)。
4.2、卷积神经网络的池化
在通过卷积操作得到的特征后,其特征的维数很大,很容易出现“过拟合”的情况,通常可以对特征进行聚合统计,聚合统计的方法主要有求平均值或者最大值,这个过程也被称为池化(Pooling)。下面的过程解释了池化的具体过程。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9vXkBEMi-1650777583599)(http://i.imgur.com/P7YpzkO.gif)]
通过卷积操作和池化的操作,我们便得到了特征,将特征应用在各种分类器中,如Softmax回归中,便能对样本进行分类。
这里只是简单介绍了卷积和池化的过程,更多的卷积神经网络的知识可以见以后的专题。
若需要PDF版本,请关注我的新浪博客@赵_志_勇,私信你的邮箱地址给我。
参考文献
1、英文版:UFLDL Tutorial
2、中文版:UFLDL教程















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









