







本集群搭建于以下软件:
VMware Workstation12 Pro
SecureCRT 7.3
Xftp 5
CentOS-7-x86_64-Everything-1611.iso
hadoop-2.8.0.tar.gz
jdk-8u121-linux-x64.tar.gz这里的集群是
192.168.195.132 Master、Namenode、SecondNameNode、DataNode
192.168.195.133 Slaver1 DataNode
192.168.195.134Slaver2 DataNode
一、虚拟机的安装
VMware Workstation Pro的安装步骤不再赘述,next、next就行,只做Centos的安装步骤详解
1.VMware Workstation12 Pro选择新建虚拟机

2.选择典型
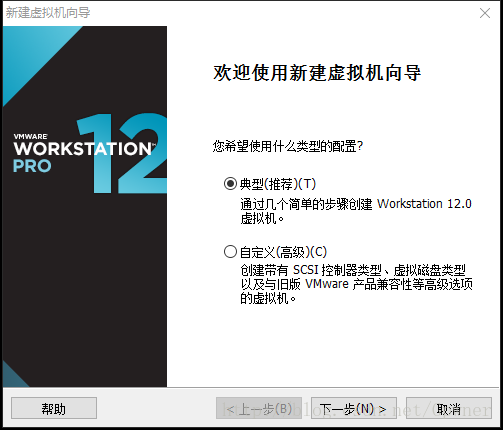
3.安装程序光盘映像文件,选择你的CentosISO文件,下一步
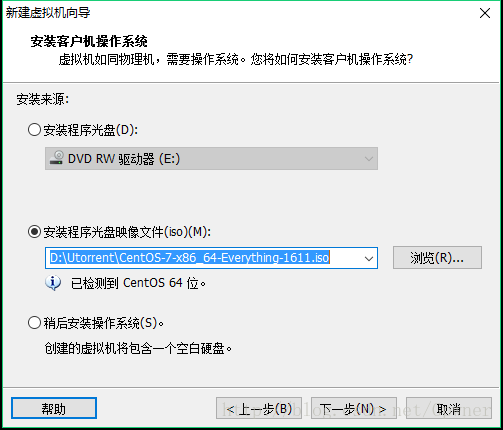
4.输入新建的虚拟机名:Master|Slaver1|Slaver2
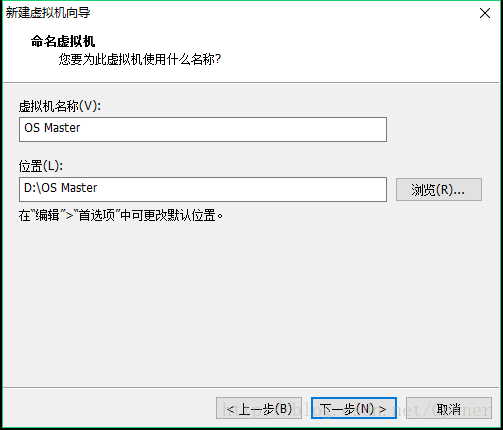
5.分配磁盘大小,指定文件拆分类型,下一步
6.网络选择桥接模式、复制主机物理地址,内存和磁盘根据自己的条件选择就好了,关闭
备注:选择桥接模式能虚拟出一台和真是主机没有多大区别的虚拟机
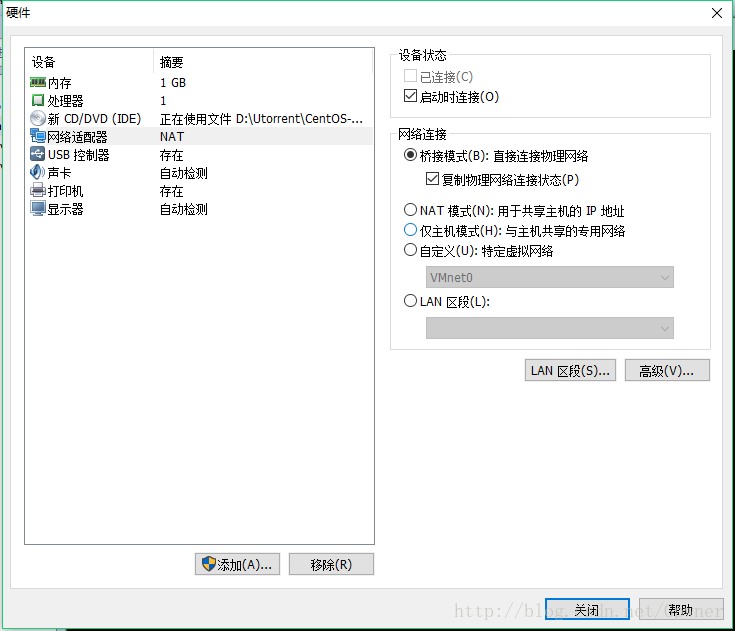
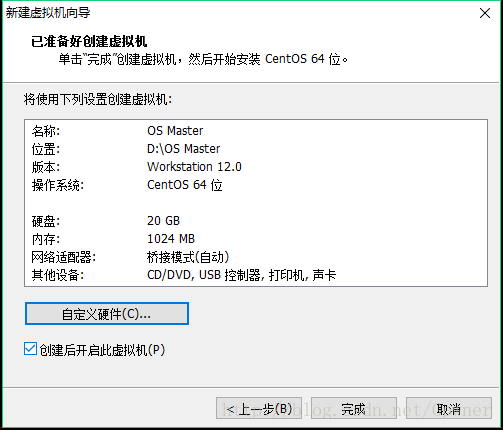
7.创建后开启此虚拟机
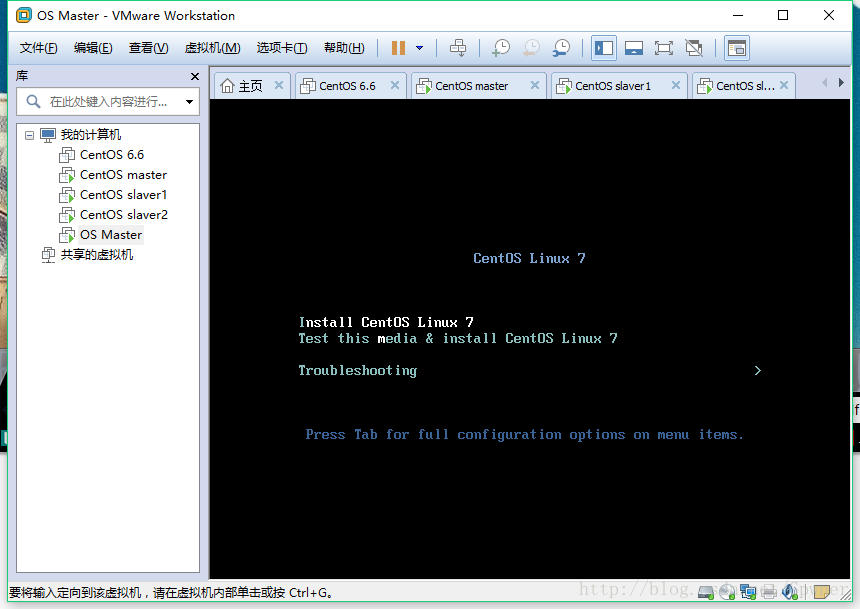
8.选择Install Centos 7
9.Next、Next、Next我选择的是最小化安装,在安装的过程中设置自己的root密码,直到下面这一步
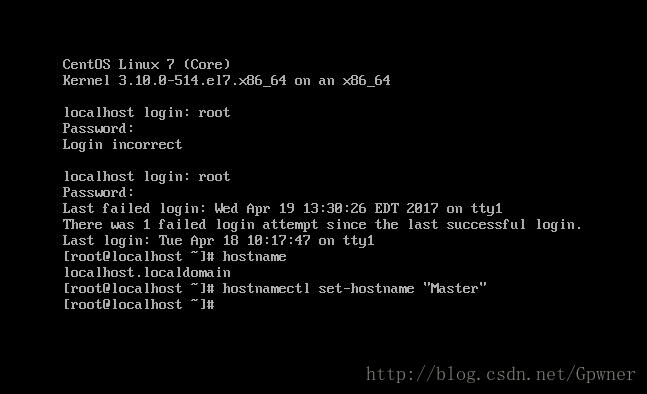
10.Login,修改主机名
hostnamectl --static set-hostname <host-name> 之后注销重新登录,就可以看到主机名已经成功地被修改了
11.修改网卡
vi /etc/sysconfig/network-scripts/ifcfg-ens33 把Onboot修改为Yes

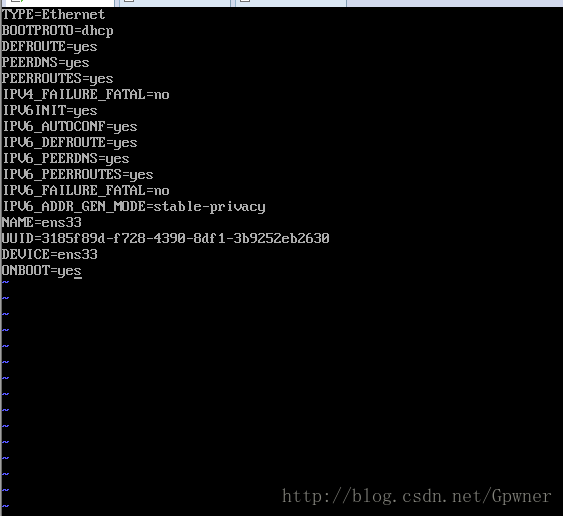
:wq保存,然后service network restart

12.查看IP地址:ifconfig
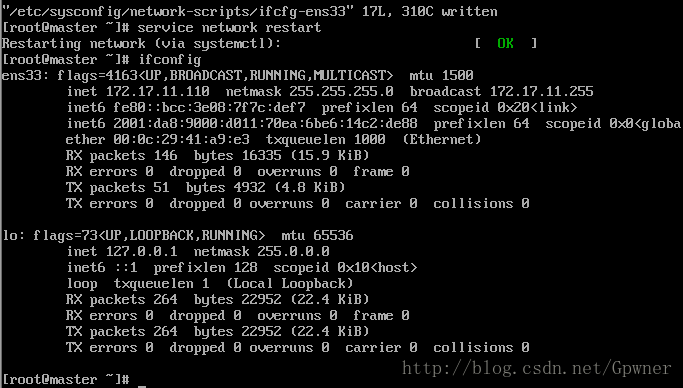
从图中得到IP地址:172.17.11.110,子网掩码:255.255.255.0
13.查看DNS:
nmcli dev show|grep DNS
14.查看网关:
route -n
15.修改网卡
vi /etc/sysconfig/network-scripts/ifcfg-ens33 修改静态IP地址,添加IP地址、子网掩码、网关、DNS
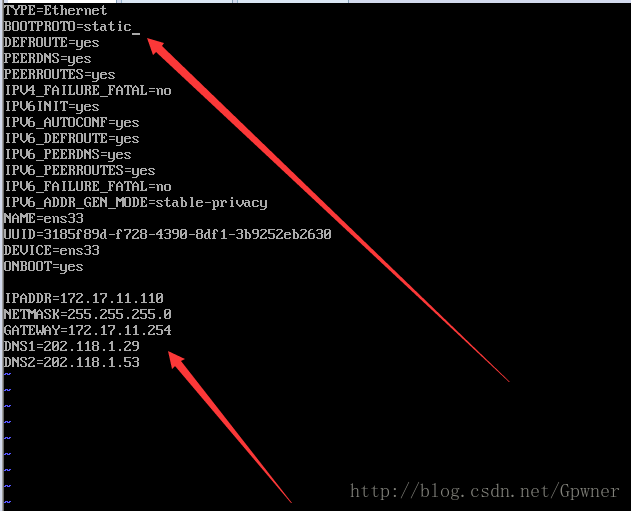
保存,
16.重启网关
service network restart

17.查看防火墙状态
systemctl status firewalld我这里显示防火墙没有关闭
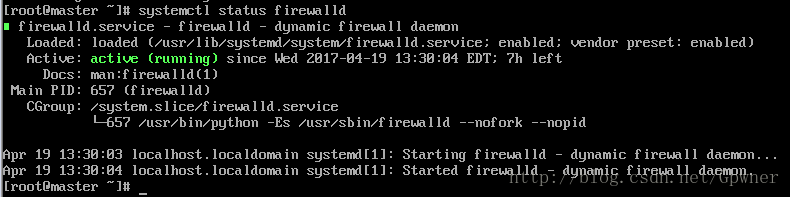
18.关闭防火墙
systemctl stop firewalld禁止防火墙
systemctl disable firewalld
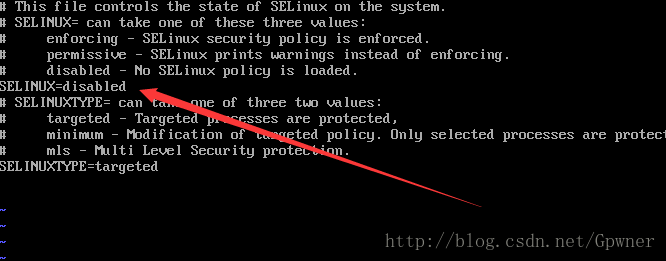
19.进制Selinux
vi /etc/sysconfig/selinux
其他的机器按照一样的步骤来,虚拟机安装准备到此结束
二、免密码登录
分别在每一台机器上执行
ssh-keygen -t rsa一路回车,然后到/root/.ssh文件夹下
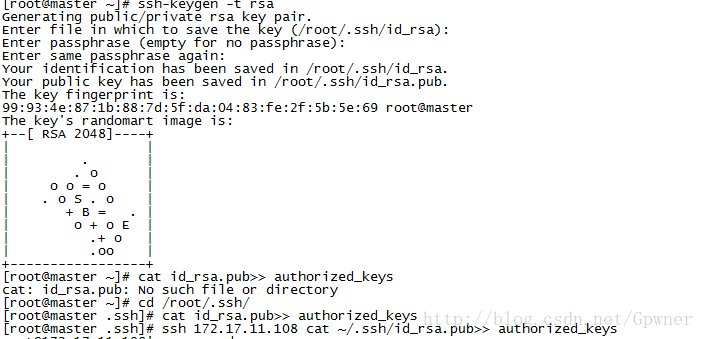
在Master上将id_rsa.pub重定向到authorized_keys
cat id_rsa.pub>>authorized_keys将Slaver1/Slaver2的id_rsa.pub追加到authorized_keys
ssh slaver1的IP地址 cat /root/.ssh/id_rsa.pub>>authorized_keys查看id_rsa.pub中的内容:

将authorized_keys分发到Slaver1、Slaver2的/root/.ssh目录下
scp authorized_keys slaver1/slaver2的IP地址 /root/.ssh/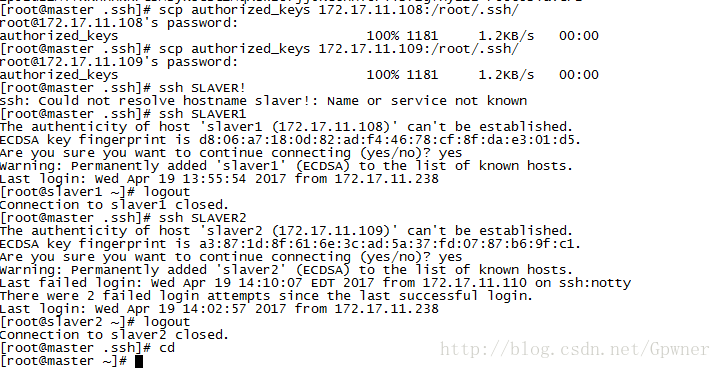
可以试一下ssh slaver1/slaver2

可以看到现在Master上登录在Slaver1、Slaver2并不需要手动输入密码了
如果不能直接ssh slavername,需要先手动配置一下master 上的/etc/hosts文件
然后再通过scp命令分发到每台从节点的对应位置

三、JDK的安装
通过xftp链接虚拟机,新建链接
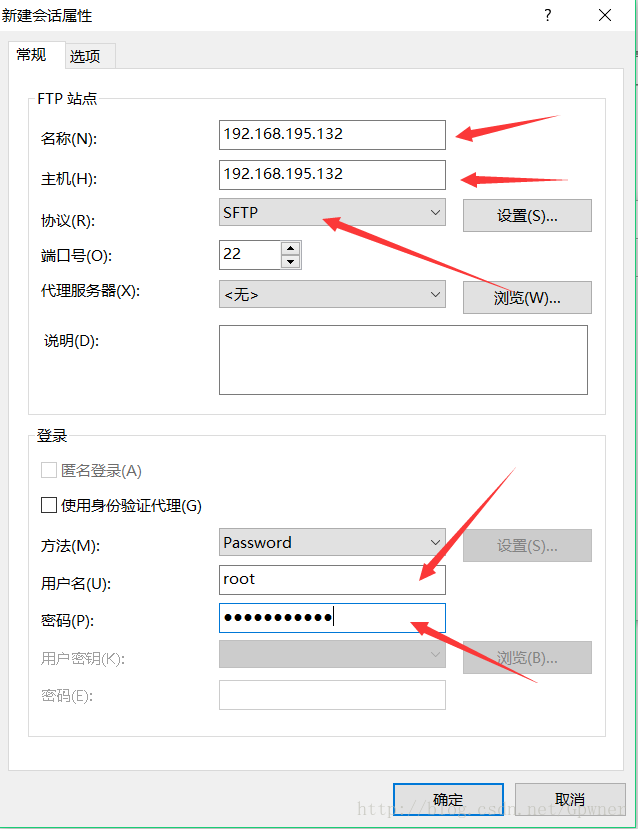
在Windows中找到JDK文件,然后双击传输到Centos中/usr/local路径下
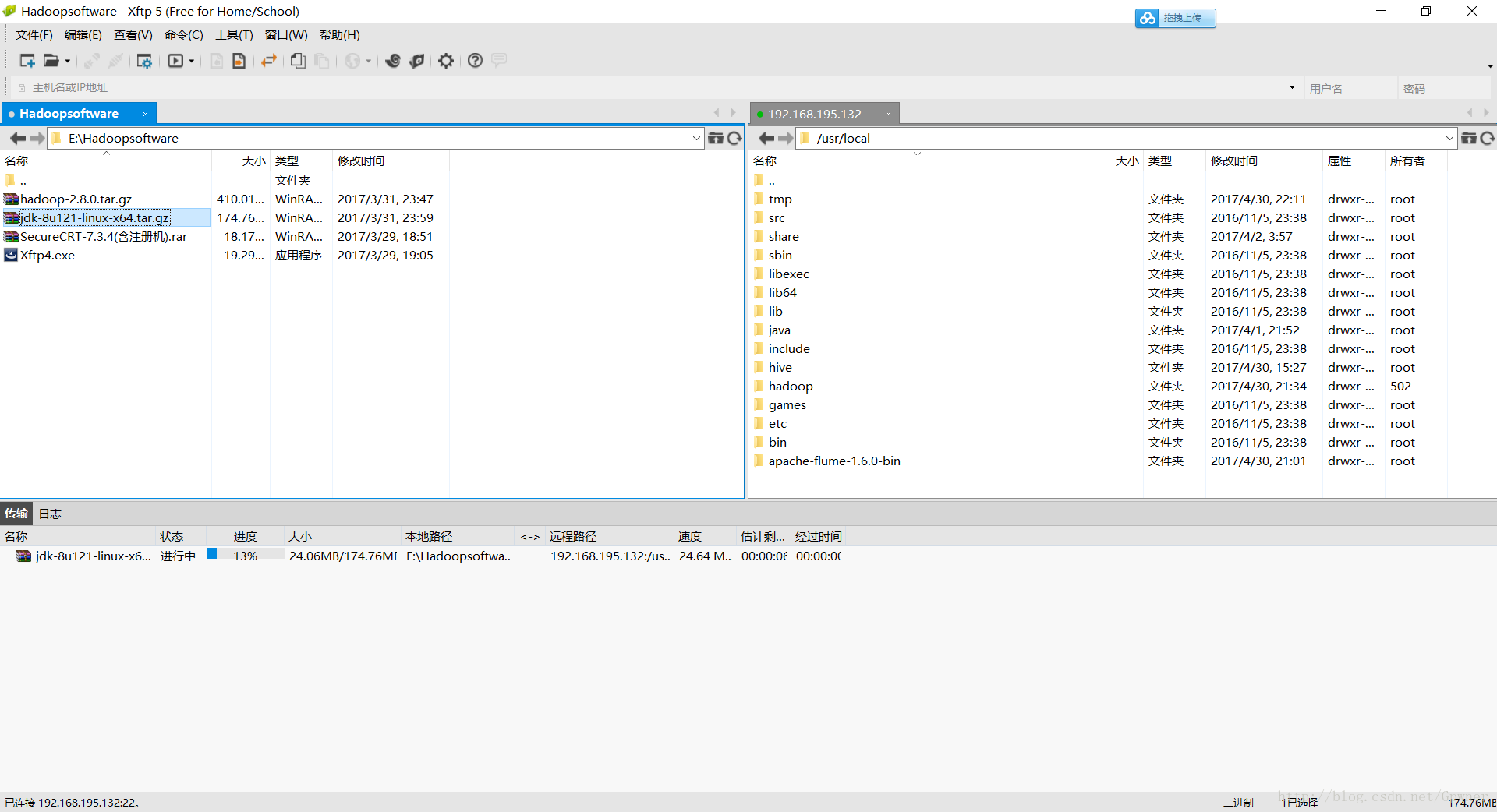
在终端中解压:
tar -xvf jdk-8u121-linux-x64.tar.gz

然后将解压后的文件夹重命名为java
配置环境变量:
vi /etc/profile
在profile文件末尾追加:
export JAVA_HOME=/usr/local/java/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar保存,
source /etc/profile在终端输入:java -version,出现以下内容说明JDK安装成功
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)最后通过scp命令将整个文件夹分发到从节点Slaver1、Slaver2上
四、Hadoop的安装
1.通过xftp将Hadoop传到master:/usr/local路径下:
然后解压,将解压后的文件重命名为hadoop,配置环境变量:
vi /etc/profile,在文件末尾追加:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_HOME=$HADOOP_HOME/etc/hadoop/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHsource /etc/profile
使配置文件生效
2.修改配置文件
- vi /usr/local/hadoop/etc/hadoop-env.sh文件添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_121- vi /usr/local/hadoop/etc/yarn-env.sh文件添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_121- 配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.195.132:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>- 配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.195.132:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.195.132:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.195.132:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.195.132:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.195.132:8088</value>
</property>
</configuration>- 修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.195.132:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>- 修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>- 修改slaves文件
192.168.195.133
192.168.195.134
192.168.195.132都配置完毕之后,将master上的Hadoop文件夹发送到Slaver1、Slaver2上,然后配置对应机器上的环境变量vi /etc/profile
五、格式化Hadoop
/usr/local/hadoop/bin/hadoop namenode -format六、启动Hadoop集群
start-all.shMaster:
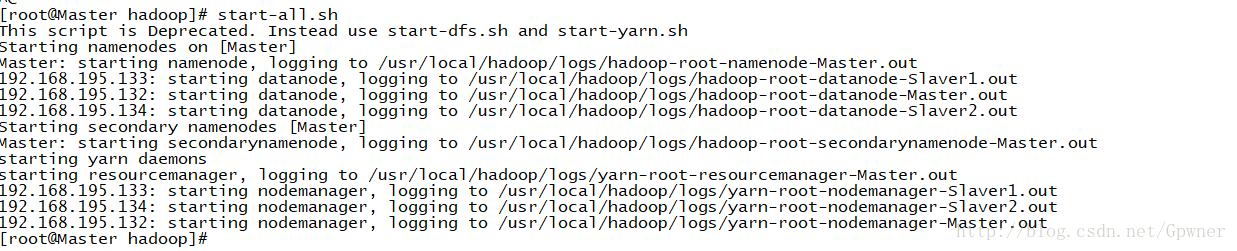

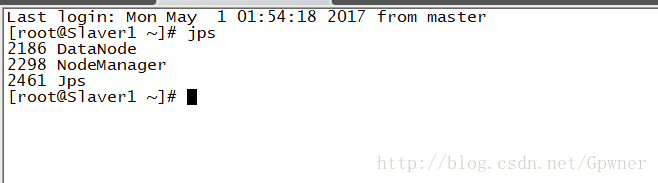
Slaver1:
Slaver2:
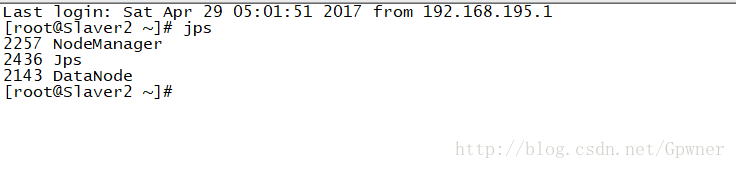
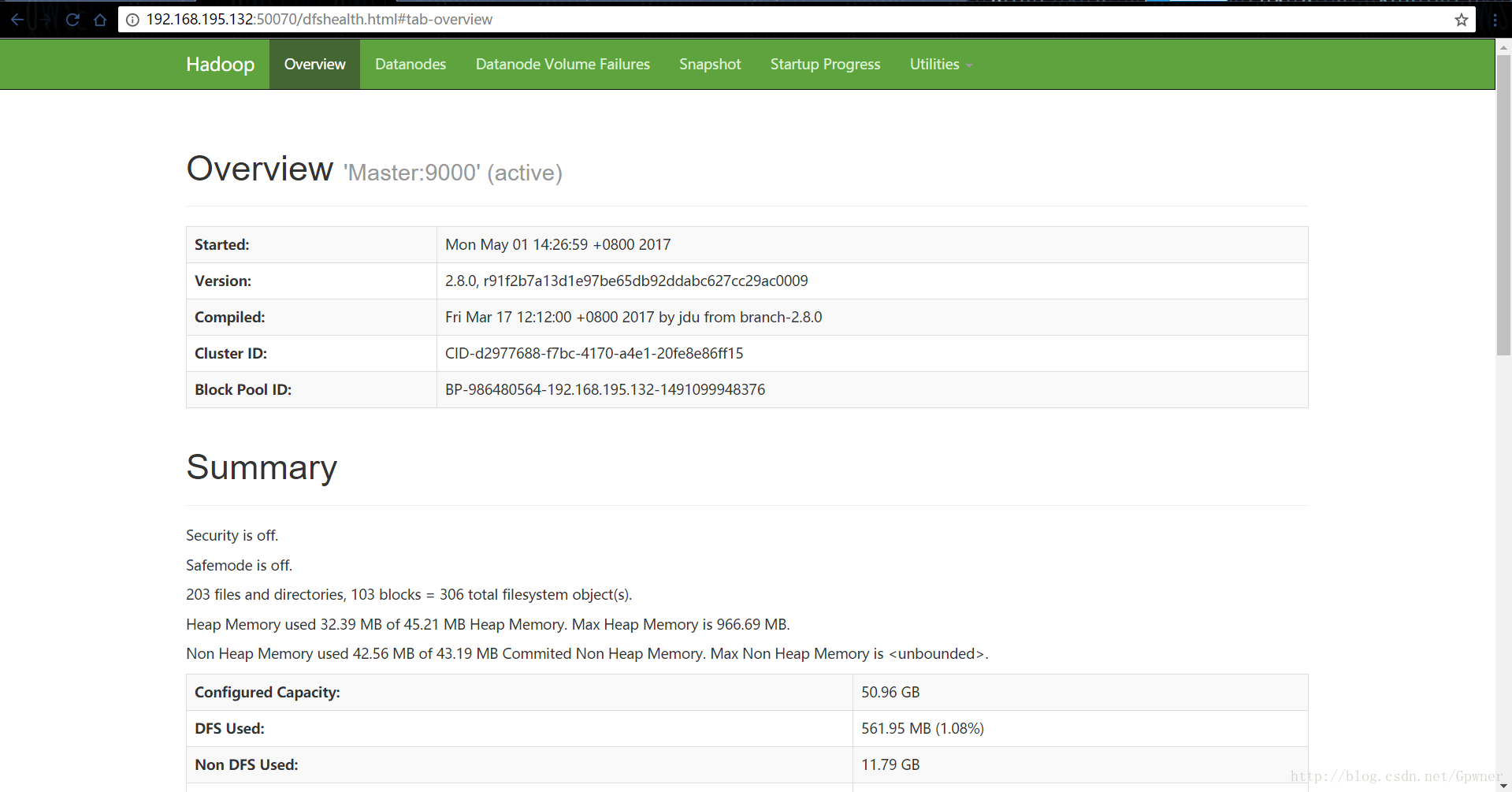
在任意能联网的浏览器输入Master的IP地址+50070
Master+8088
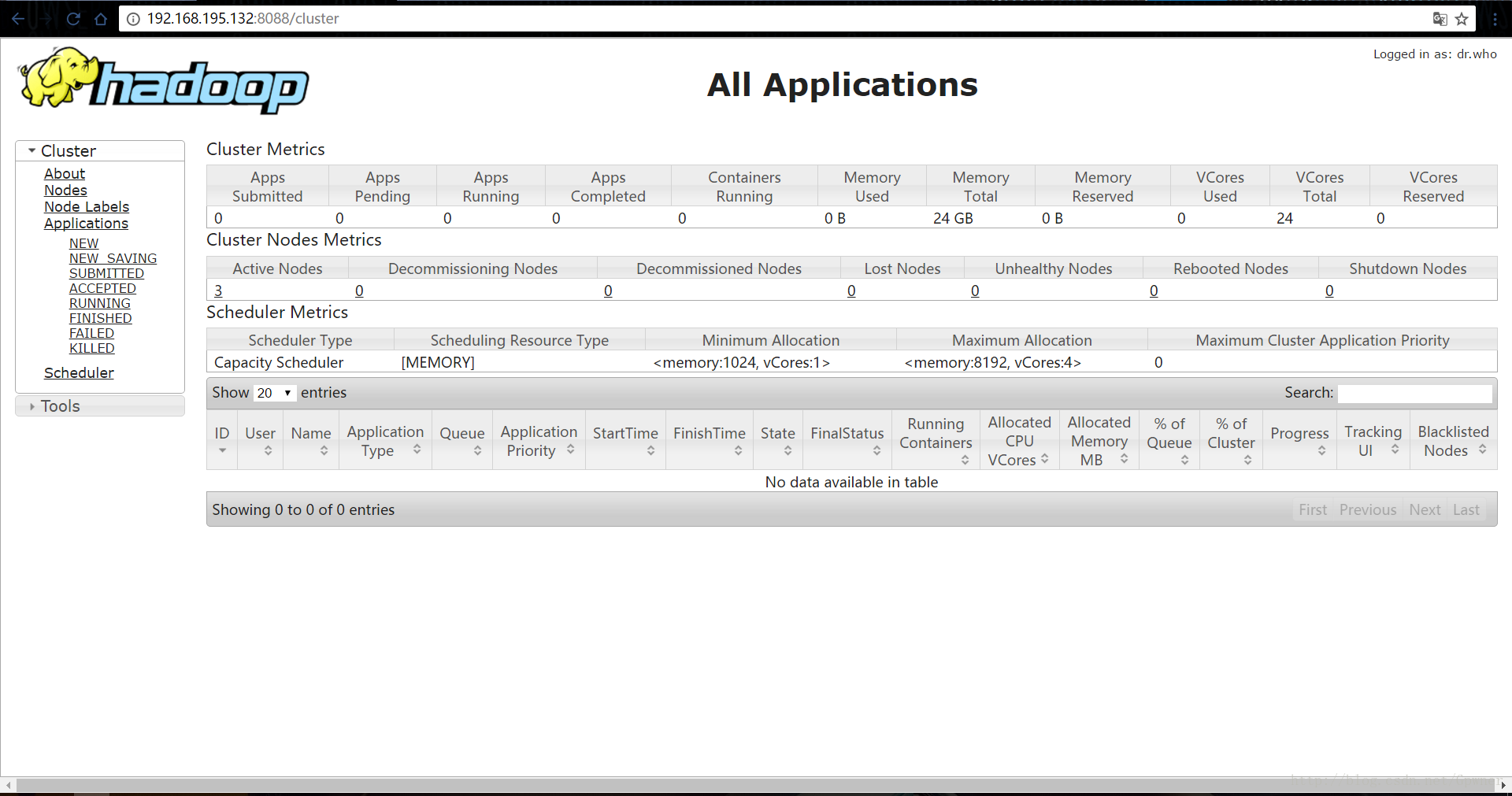
在任意一台机器上创建两个文件夹:file1.txt和file2.txt
vi file.txt
Hello Hadoopvi file2.txt
Welcome to Hadoop然后通过dfs命令上传到HDFS上的/input目录下:
hadoop -put file*.txt /input
运行Hadoop命令:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /input/file*.txt /output/wordcount0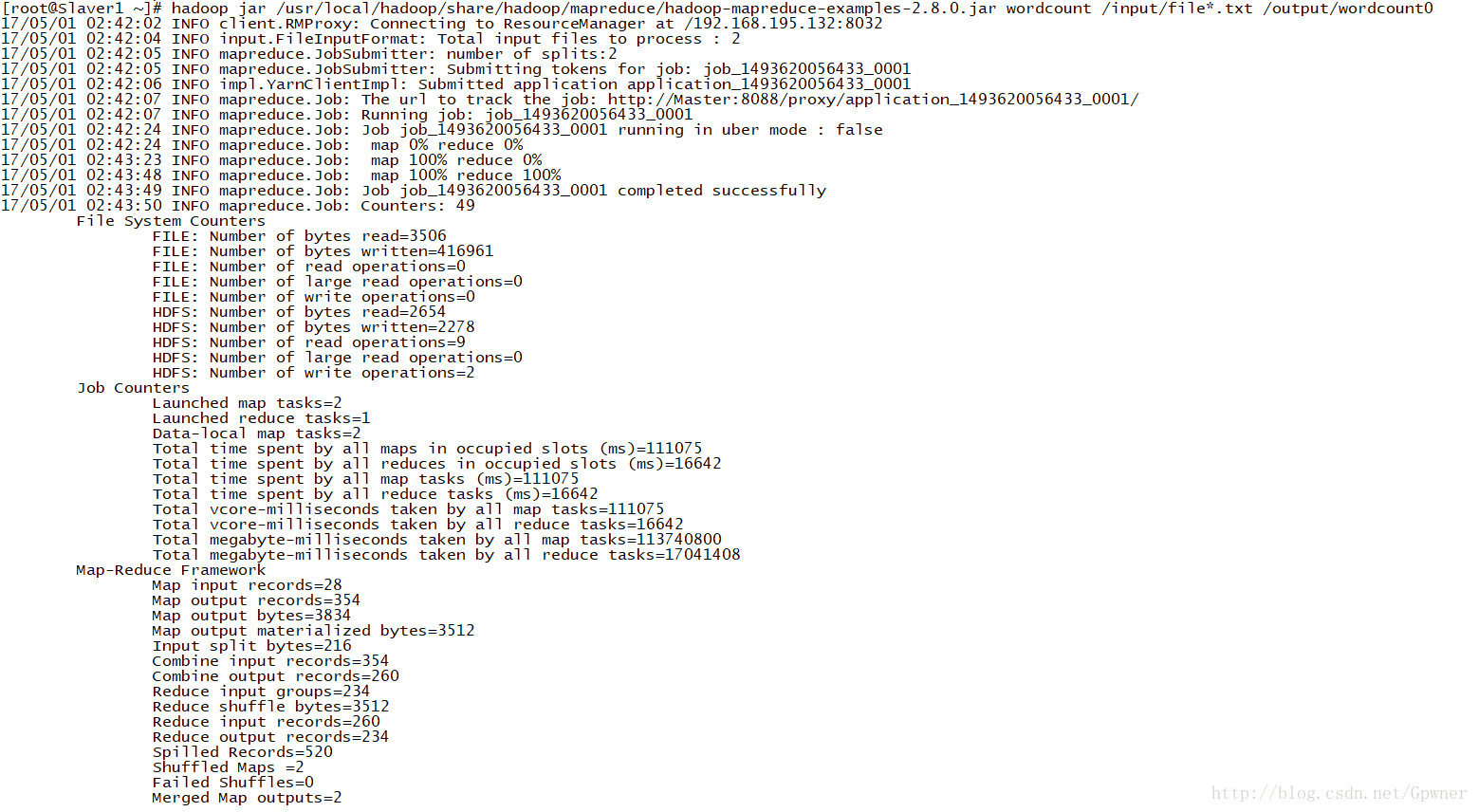
查看运行结果
[root@Slaver1 ~]# hadoop fs -ls -r /output/wordcount0
Found 2 items
-rw-r--r-- 3 root supergroup 2278 2017-05-01 02:43 /output/wordcount0/part-r-00000
-rw-r--r-- 3 root supergroup 0 2017-05-01 02:43 /output/wordcount0/_SUCCESS
[root@Slaver1 ~]# hadoop fs -cat /output/wordcount/part-r-00000到这里集群已经搭建完毕,备忘!















 2847
2847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









