







scrapy的请求是并发进行的,但是我今天有一个需求是要顺序爬网站上的信息,爬的是搜狗热搜榜的电影、电视剧、动漫、综艺的热搜排行榜,每一个爬前三页。顺序爬取下来然后存到数据库中。
我的解决办法是在setting文件中将scrapy的并发数设置为1,当并发数为1的时候不就是同步了嘛
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 1这个参数的默认值是16
以下是我的代码:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
class Topsougou_Spider(scrapy.Spider):
name = 'top_sougou_spider'
def start_requests(self):
reqs = []
# 综艺
for i in range(1, 4):
url = 'http://top.sogou.com/tvshow/all_' + str(i) + '.html'
req = scrapy.Request(url=url, headers=headers)
reqs.append(req)
# 电影
for i in range(1, 4):
url = 'http://top.sogou.com/movie/all_' + str(i) + '.html'
req = scrapy.Request(url=url, headers=headers)
reqs.append(req)
# 电视剧
for i in range(1, 4):
url = 'http://top.sogou.com/tvplay/all_' + str(i) + '.html'
req = scrapy.Request(url=url, headers=headers)
reqs.append(req)
# 动漫
for i in range(1, 4):
url = 'http://top.sogou.com/animation/all_' + str(i) + '.html'
req = scrapy.Request(url=url, headers=headers)
reqs.append(req)
return reqs
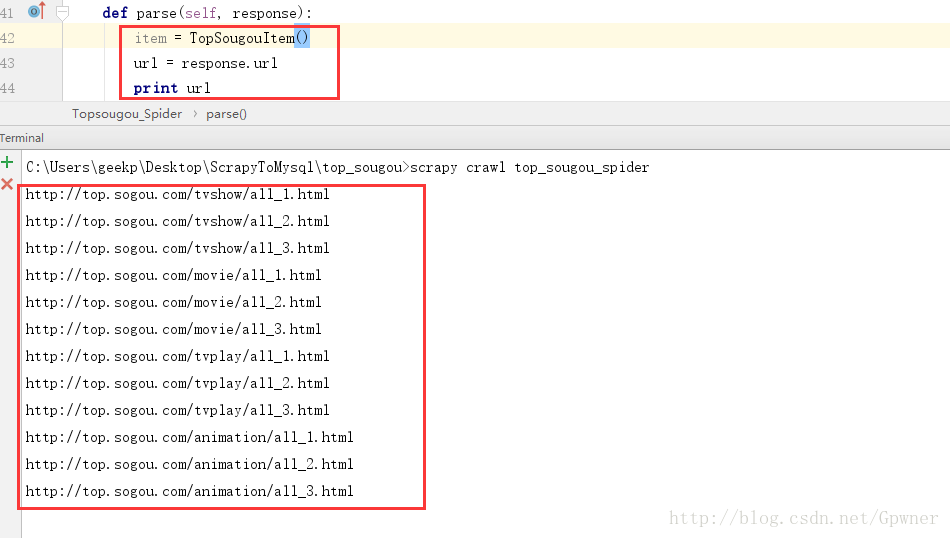
def parse(self, response):
item = TopSougouItem()
url = response.url
print url执行结果:














 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









