







 本文介绍了普利姆算法的一种eager实现方式,通过避免将不再候选的废边加入优先队列,使用索引式优先队列在常量时间内找到所需元素,从而优化了算法效率,使得最差情况下的时间复杂度为O(ElogV)。内容包括算法描述、实现分析、完整实现和时间复杂度的讨论。
本文介绍了普利姆算法的一种eager实现方式,通过避免将不再候选的废边加入优先队列,使用索引式优先队列在常量时间内找到所需元素,从而优化了算法效率,使得最差情况下的时间复杂度为O(ElogV)。内容包括算法描述、实现分析、完整实现和时间复杂度的讨论。
算法描述
在普利姆算法的lazy实现中,参考:普利姆算法的lazy实现
我们现在来考虑这样一个问题:
我们将所有的边都加入了优先队列,但事实上,我们真的需要所有的边吗?
我们再回到普利姆算法的lazy实现,看一下这个问题:
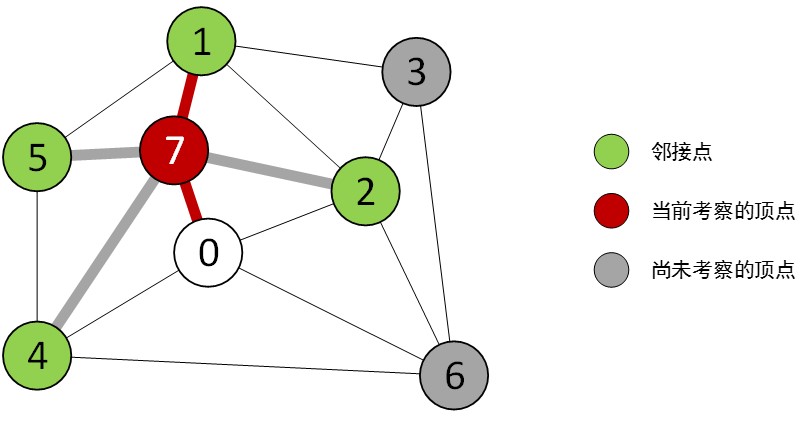
当顺着顶点0的邻接表考察顶点7时,边7-2和边7-1被加入了优先队列Q.
然而,当我们开始对顶点2进行考察时:
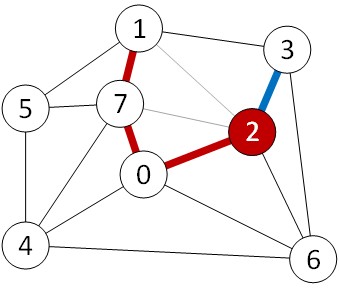
边2-3是最轻边,我们显然不需要对边7-2和边7-1进行再次考察.
但是,由于边7-2和边7-1在对顶点2进行考察之前已经加入了优先队列Q,似乎我们对之前发生的事无可奈何,也必须让优先队列维护着这些不再候选的废边,从而加重了优先队列的负担,影响了效率.
结果是否真的如此?
如果我们仔细思考,会注意到我们可以采取这样的一个技巧去防止将废边加入优先队列:
我们关注的只是当前能看到的最轻边,所以边7-2和边7-1对我们来说只有这样的意义:
边7-2:到顶点2的距离是x;
边7-1:到顶点2的距离是y;
边3-2:到顶点2的距离是z.
而z > x且z >y.
所以我们既然无法避免在先于顶点2之前就将边7-2和边7-1当做废边(贪心算法),所以我们可以
采取更新的方式来在优先队列Q中维护到某个顶点的最短距离.
换句话说,我们对某个顶点,只在Q中维护一条边,就是当前已知连着它的最轻边.
由此,我们避免了将所有的边都加入优先队列Q,从而使得最差情况下Q的操作与图的顶点数V 成线性渐进:O(V ).
但一般的优先队列只提供了入队(enqueue)和出队(dequeue)操作,要更新到某个顶点的最短距离,我们需要高效地在优先队列中访问这个顶点.
那么按照一般优先队列的方式,比如jdk中的优先队列,它会是这样:
private int indexOf(Object o) {
if (o !=  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2810
2810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









