







 超级会员免费看
超级会员免费看
 本文详细介绍了在Centos 7中如何进行Hadoop的伪分布式安装,包括添加root用户、更改主机名、配置IP映射、安装jdk、安装hadoop、配置环境变量以及相关配置文件,最后启动并测试Hadoop进程。
本文详细介绍了在Centos 7中如何进行Hadoop的伪分布式安装,包括添加root用户、更改主机名、配置IP映射、安装jdk、安装hadoop、配置环境变量以及相关配置文件,最后启动并测试Hadoop进程。
简介:
windows 7中安装VMware,VMware中安装Centos 7,Centos 7中安装伪分布式HaDoop
请提前下载jdk和hadoop
至于如何在windows中安装VMware以及在VMware中Centos 7,
请参照博主的博客:
1. 安装前的重要事情
(1)添加root用户
su———使用su命令进入root(需要roo密码)
vi /etc/sudoers———–使用此命令修改文件sudoers中的内容
[关于vi命令的使用方法,如果不会,请参照本博主的博客]
linux系统下修改文件命令vi的使用
找到如下图所示的内容,添加一行,其中红色方格内为你的root用户名
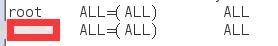

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











