 正则化技术在机器学习中的应用
正则化技术在机器学习中的应用





 正则化是防止机器学习模型过拟合、提高泛化能力的关键技术,主要包括L1和L2正则化。L2正则化通过惩罚权重的平方和,倾向于得到接近0但不为0的权重,适合处理共线性特征。L1正则化则通过L1范式促使权重向0收缩,实现模型稀疏化和特征选择。在特征个数远大于样本数且需要稀疏模型的场景下,L1正则化表现更好。Elastic Net结合了L1和L2的优势,通过调整参数p平衡两者效果。
正则化是防止机器学习模型过拟合、提高泛化能力的关键技术,主要包括L1和L2正则化。L2正则化通过惩罚权重的平方和,倾向于得到接近0但不为0的权重,适合处理共线性特征。L1正则化则通过L1范式促使权重向0收缩,实现模型稀疏化和特征选择。在特征个数远大于样本数且需要稀疏模型的场景下,L1正则化表现更好。Elastic Net结合了L1和L2的优势,通过调整参数p平衡两者效果。
正则化(regularization)技术是机器学习中十分常用的技术,它在不同的模型或者情景中以不同的名字出现,比如以L2正则化为例,如果将L2正则化用于linear regression,那么这就对应了ridge regression;如果将L2正则化用于神经网络(neural network),那么L2对应为权重衰减(weight decay)。
正则化的作用实际上就是防止模型过拟合,提高模型的泛化能力。正则化的种类有很多,这里主要介绍在工程中用得较多的两类正则化,一个是L1正则化,另一个则是L2正则化。为了配合阐述,本文用linear regression的正则化作为例子来贯穿全文。
当我们用linear regression在训练数据集上训练模型时,我们定义一个最优化目标函数:
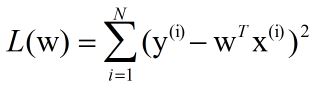
式中(x(i), y(i))为训练数据,w为线性模型的参数向量,为了使得模型能够充分拟合训练样本点,我们希望上述目标函数的值尽可能小,即:
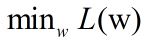
但是由于实际中的训练数据量往往并不大,如果让模型完美拟合训练数据的话,很可能造成模型过拟合,从而使得模型的泛化能力较差。这
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1400
1400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









