







这是发表在2016 CVPR上的一篇用深度学习做目标跟踪的文章,区别于传统的目标跟踪方法,文章所用方法学习过程全部在线下完成,模型确定以后,跟踪期间不再进行模型的更新。
先感受一下文章的*pipeline:*
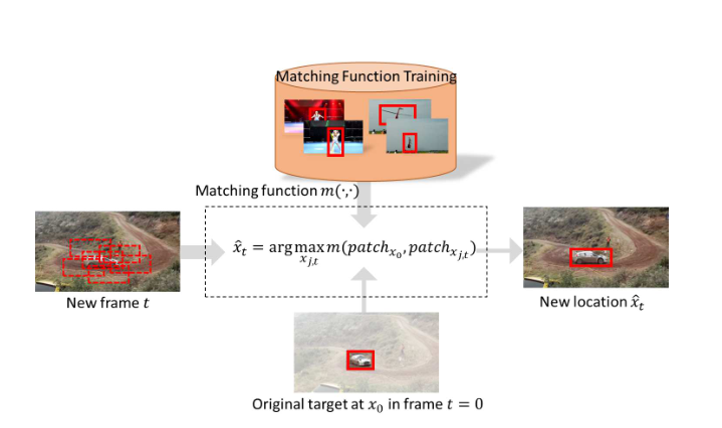
整个流程大致为:首先离线训练卷积网络得到匹配函数,然后在线跟踪,根据匹配函数选择与初始帧标定目标最为匹配的patch作为跟踪结果。
- 所用的深度学习框架:caffe
- 网络结构:Siamese网络(“双胞胎”网络)
单支网络模型:Alexnet/Vgg
训练阶段:
网络结构如下:
作者借鉴了以图搜图的思想,采用两支网络(Siamese结构)来完成模型学习和跟踪。在训练阶段每次输入都是一个图像对儿(包含两幅图像和一个正负标签),训练的目标是使得在处理后的特征空间里正样本之间距离尽量近,负样本距离尽量远,作者设计的损失函数充分体现了这一点。
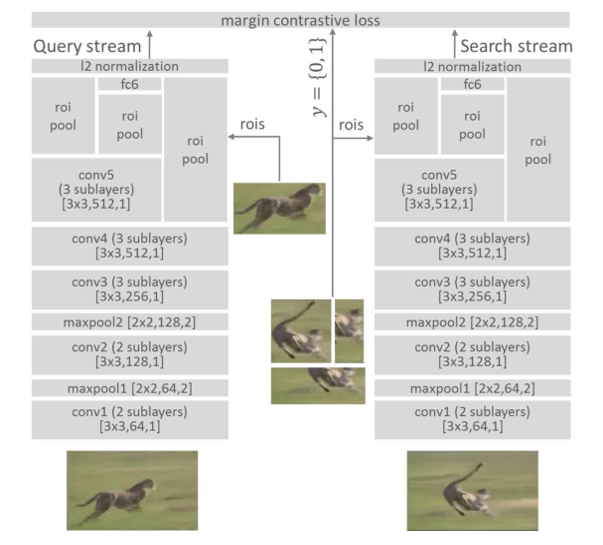
网络结构的几点改进说明:
- 对pooling层的改进:减少原本网络结构的pooling层数。作者解释的原因是pooling会降低图像的空间分辨率,这个分辨率对分类任务来说影响不大,但是类似定位、目标跟踪这样的任务对分辨率还是有一定要求的,但同时又为了保证pooling带来的消除高频小噪声的好处,所以,对pooling层要适当减少。具体为VGG只包含两个pooling层,Alexnet不再包含pooling层。
- 对fast-Rcnn的借鉴:由于单个处理多个candidate regions耗时耗力,因此采用region pooling layer来快速处理多个重叠区域,每一分支的输入为全图加上一系列bounding box,前几层网络先处理整幅图像,然后ROI层把特定区域的特征图转换为固定长度的表达,再送往网络的高层。
- 多层特征综合考虑:网络层越深,表达越抽象,低层特征对类内差异更敏感,高层特征对类间差异更敏感。在跟踪任务里是高层特征好,还是低层特征好,难以定论,所以高层和低层的特征都采用,将多层的输出特征直接馈送到损失层 。
- 正则项约束:激活函数采用RELU,但是这样输出的幅度就会没有限制,幅度的大小会影响损失函数的大小,所以在损失函数前加一个l2范数层来限制幅度。
- 损失函数的设计:正样本对尽量离得近,负样本对离得远。
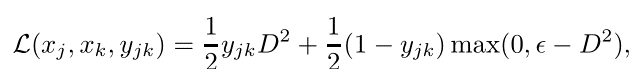
tracking阶段:
认为第一帧的bounding box是没有污染的,所以每个candidate region都和它进行比对,即一支网络送入初始帧的bounding区域,另一支网络送入当前帧的candidate regions,返回最匹配的作为跟踪结果。
实验结果:
作者做的实验很充分,在和其他传统的跟踪算法做对比之前,先对自身网络结构上从三方面进行了比对:
- 有微调&有微调(没有微调指直接用imagenet训练好的alex/vgg参数,有微调是在该参数基础上又用额外的图像序列库(ALOV300)进行了训练微调)
- 减少max pooling &不减少max pooling
- 单层特征&多层特征(直接从fc6层馈送给损失层,以及conv4,conv5&fc6一起馈送给损失层)
-附一下对比的结果图:
实验结果当然一一说明了作者之前对网络的改进是大大的有效滴。
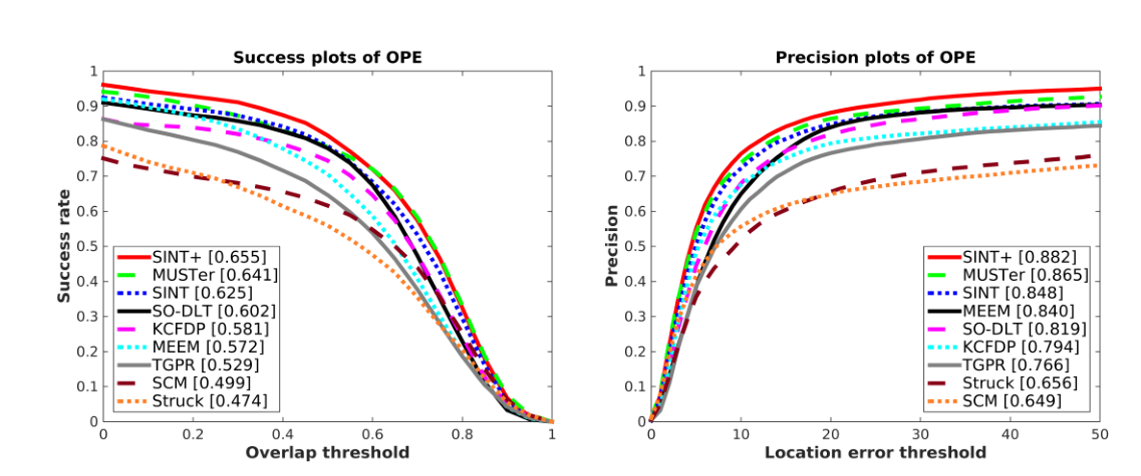
再来看一下跟别的传统算法的比较结果:
注:SINT+据作者解释,是在跟踪阶段加入了光流法的结果,所以,感觉基于深度学习来做目标跟踪如果再融合传统算法还是有很大的进步空间滴。
















 2469
2469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









