







台湾国立大学机器学习技法.听课笔记(第二讲)
:Dual Support Vector Machine
一,Motivate of Dual SVM(对偶SVM的动机)

上一讲我们知道要想假设尽可能的少,边界尽可能的精细,我们可以采用non-linear SVM。即Large-MarginHyperplane + numerous feature transform:

虽然进行了feature transform,但是由此带来了问题,随着特征转换的不同,QP(二次规划)的变量数目就不同。同一个问题用SVM解,就不能单纯的套用同一个变量。那我们能不能即用feature transform,又使得变量固定呢?

我们此时就想到与原问题对偶的拉格朗日问题,我们在正则化是曾经用过拉格朗日乘子,那拉格朗日对偶问题的乘子与拉格朗日问题有啥区别呢?

于是我们把SVM问题写成:

把SVM有条件的约束问题看成无条件的最小值问题。其实可以理解为:把任意的b和ω带入 α),对于所有的α_n大于等于0,求出L(b,w,α)的最大值;然后对所有的b和w带入所得到的L(b,w,α)进行对比,求出其最小值,就是我们要求的SVM。无约束的最小值问题,其约束条件其实隐藏在max中了。

最终我们达到了:
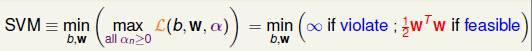
二,Largange Dual SVM(SVM的对偶拉格朗日问题)
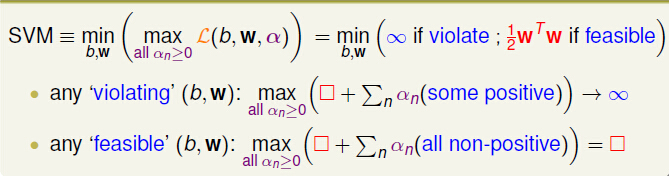
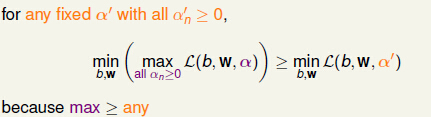
由上图可知,当α固定时,对于任何b、w,都存在:(1) α’不是SVM的最优解时,左边就大于等于右边;(2)当α’是最优解时,左边就等于右边。所以:


当SVM的问题是强对偶问题是,上式的大于等于号就可以变成等号。
当拉格朗日问题和拉格朗日对偶问题是等价是,我们就对对偶问题进行简化,我们进行简化分为来年两个步骤: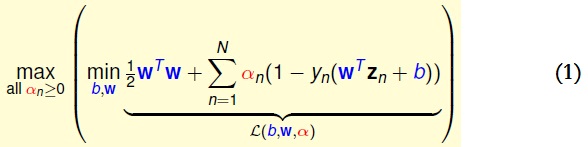
1,对b进行积分

我们就对(1)进行简化,可以得到:
2,对(2)的w_i进行积分
我们就可以得到:
因此,我们称这个为KKT条件。我们得出了结论:

三,Sloving Dual SVM
既然我们已经知道SVM简化的式子了,那我们应该如何计算这个式子呢?
首先我们先把这式子写成二次规划的形式:



上面已经用二次规划的标准形式表示了SVM,那真的dual的SVM带入二次规划里真的能很快就接出来么?
我们首先定义Q_D是q_(n,m)组成的矩阵,Q_D由于是稠密的,而且算每个q_(n,m)都得进行举证运算,所以算和存储Q_D需要很长时间和内存:

虽然解SVM存在一些问题,但是我们仍然可以由KKT条件解决SVM的对偶为题(Dual):

其中红色的框是由于点(y_n,Z_n)在SV的fat boundary边界上。
四,Messarge behind Dual SVM
1,计算(b,w)
所以我们计算(b,w)时,只需要考虑SV的这些点。

2,dual SVM算出w的形式说明
我们算出的w_(SVM)的形式和w_(PLA)类似,而PLA是从某个点开始计算,遇到犯错误的点就把犯错误的点的点加在PLA的式子中,同时加上权重。

这是不是偶然呢??其实逻辑回归或者是线性回归(LogReg/LinReg)的梯度下降/随机梯度下降(GD/SGD)问题都是有类似的表达形式。都是(y_n*z_n)的线性表示。

3,两种Hard-MrginSVM的对比


4, 同时产生的问题
我们用对偶问题的原因是什么:

但是:

总结:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









