









CUT阅读笔记
- 论文标题: Contrastive Learning for Unpaired Image-to-Image Translation
- 论文作者:Taesung Park, Alexei A. Efros, Richard Zhang, Jun-Yan Zhu
- 机构:University of California, Berkeley; Adobe Research
- 开源代码:https://github.com/taesungp/contrastive-unpaired-translation
1. 文章整体理解
1.1 相关知识回顾
- 图 像 转 换 \color{red}图像转换 图像转换(image-to-image translation)的任务是在保留输入图像的结构特征的基础上,加入目标域的外观特征。一个经典的任务就是把马转换成斑马,在保留输入的马的图像结构的同时,将纹路换成目标域(斑马)的纹路。
- 目前主流的方法大都是基于CycleGAN方法及其变种,利用:
- 对 抗 损 失 \color{red}对抗损失 对抗损失(adversarial loss)强化目标域的外观特征;
- 循 环 一 致 性 损 失 \color{red}循环一致性损失 循环一致性损失(cycle-consistency loss)来保证原始输入图像的结构不变;
- 一 致 损 失 \color{red}一致损失 一致损失(Identity Loss)控制生成器(或者说生成图片)的色调,控制整体的颜色产生变化。
但是CycleGAN的假设非常严格,要求输入的图像域和目标域之间存在双射关系,这一点在其实是很难满足的。
1.2 CUT特点介绍
以下只是个人理解,有错误请指出!不喜勿喷~
- 本论文(CUT)提出了一个替代性方案:
-
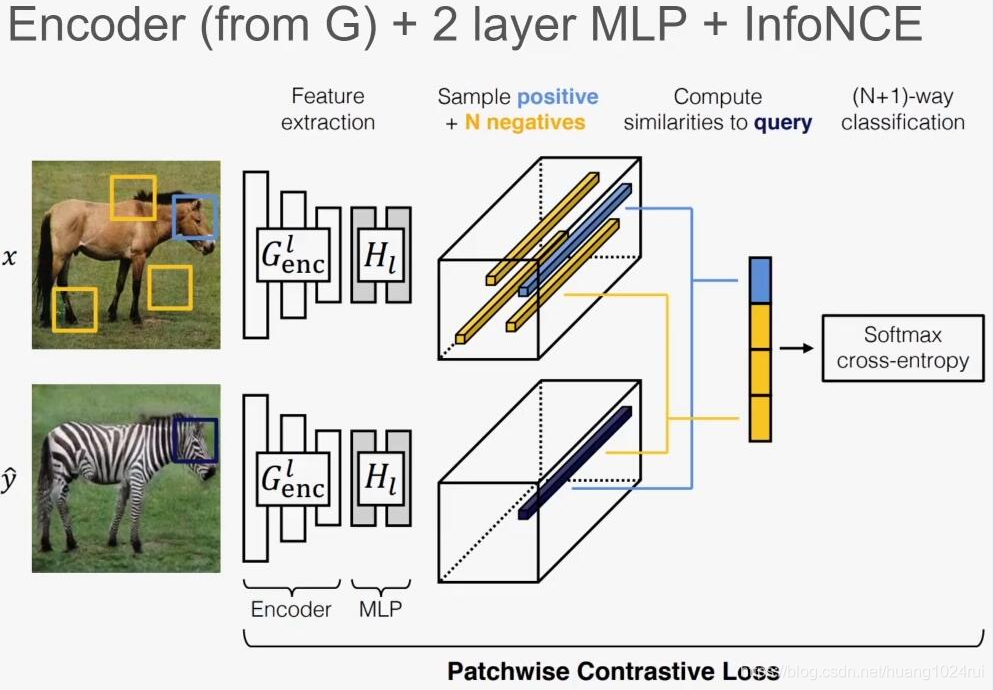
把 对 比 学 习 \color{red}对比学习 对比学习应用到Image-to-Image中。
-
只需要 训 练 一 个 生 成 器 和 判 别 器 \color{red}训练一个生成器和判别器 训练一个生成器和判别器。
-
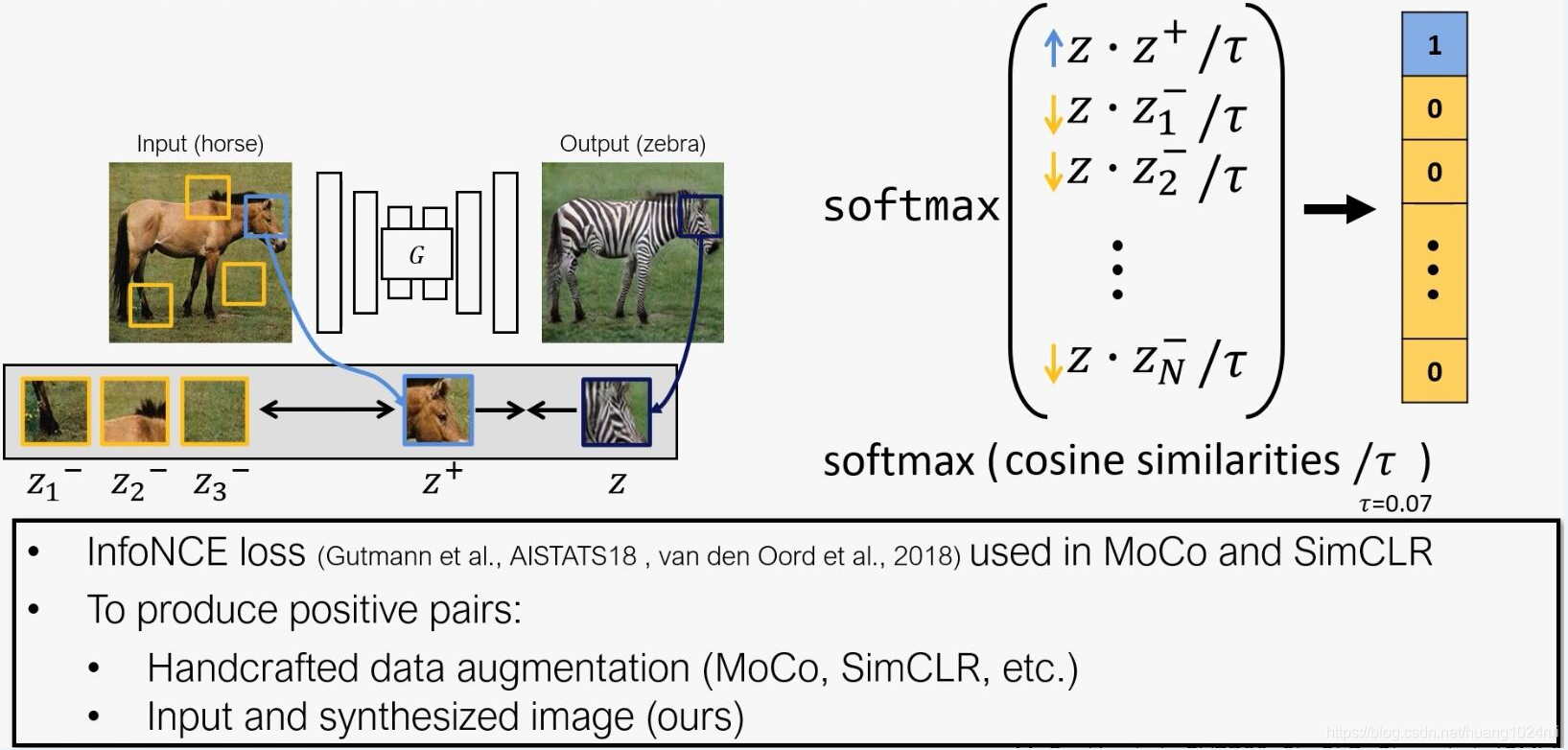
使用最大化输入输出图像块的互信息(mutual information)来替代循环一致性损失,使用 i n f o N C E l o s s \color{red}infoNCE\; loss infoNCEloss作为对比损失函数, 来学会一个生成器。
-
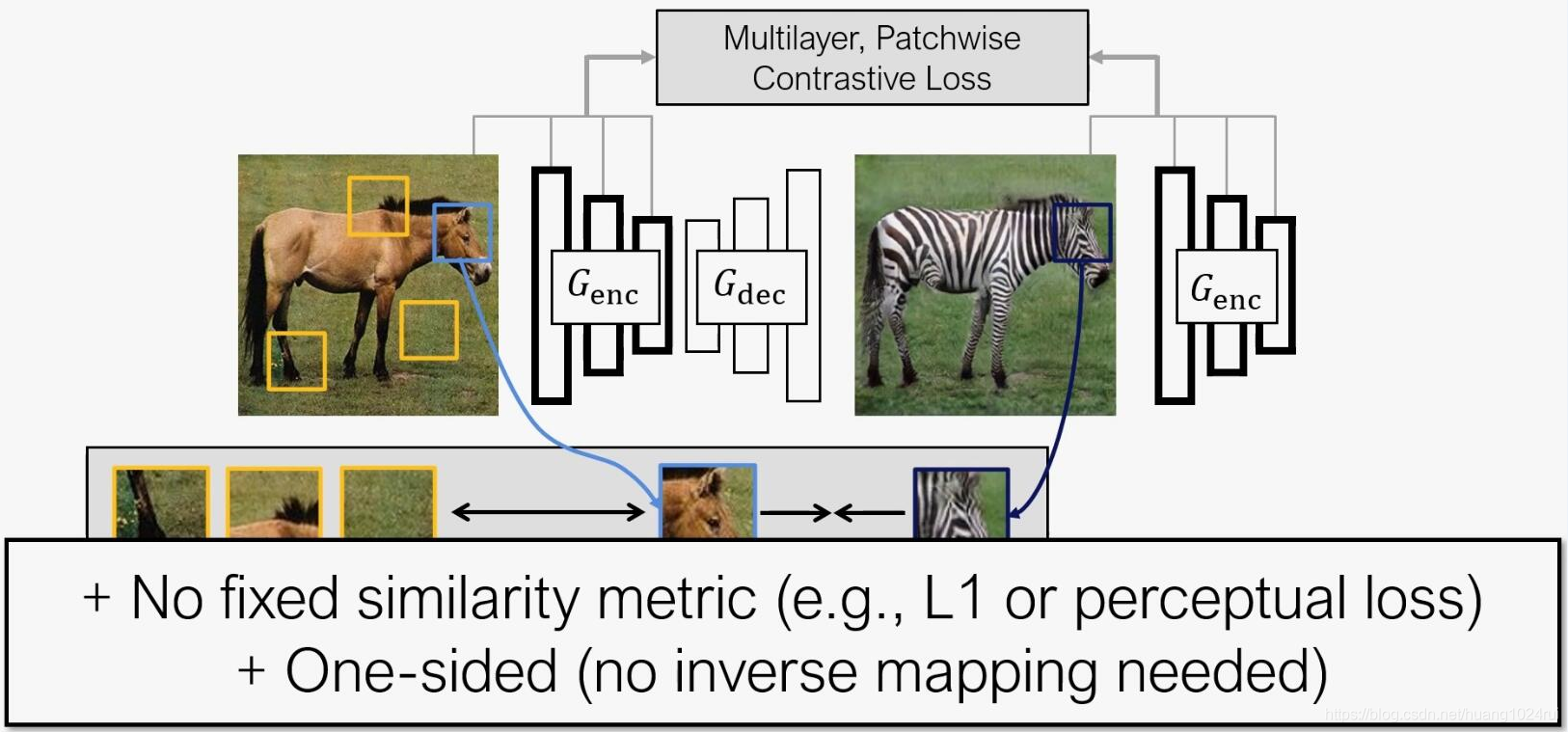
应用生成器(由 编 码 器 和 解 码 器 \color{blue}编码器和解码器 编码器和解码器组成)中的 编 码 器 \color{red}编码器 编码器将对应的图像块之间相互联系起来,通过 M u l t i l a y e r P a t c h w i s e C o n t r a s t i v e L o s s \color{red}Multilayer\; Patchwise\; Contrastive\; Loss MultilayerPatchwiseContrastiveLoss使得编码器专注于两个域之间共性的部分如形状,而忽略两个域之间的差异性部分如纹理。
-
相比于 对 比 学 习 \color{blue}对比学习 对比学习需要使用 I n t e r n a l + E x t e r n a l P a t c h e s \color{red}Internal+External\; Patches Internal+ExternalPatches, C U T \color{blue}CUT CUT仅仅使用 I n t e r n a l P a t c h e s \color{red}Internal\; Patches InternalPatches。

-
I
n
t
e
r
n
a
l
P
a
t
c
h
e
s
\color{red}Internal\; Patches
InternalPatches还用在:
1. Texture Synthesis by Non-parametric Sampling
2. ‘Zero-Shot" Super-resolution using Deep Internal Learning - 作者认为:It’s because the external patches are too easy to distinguish, and they sometimes contain false negatives, like the highlighted horse head patch.
-
I
n
t
e
r
n
a
l
P
a
t
c
h
e
s
\color{red}Internal\; Patches
InternalPatches还用在:
-
CUT从单张图像本身中提取负性图像块的效果要好于从整个数据集中其他的图像中提取,因此CUT甚至可以在单张图像上实现图像转换。
-
当 某 个 域 的 图 像 由 相 较 于 另 一 个 域 更 多 的 信 息 时 , 可 以 获 得 很 好 的 效 果 \color{red}当某个域的图像由相较于另一个域更多的信息时,可以获得很好的效果 当某个域的图像由相较于另一个域更多的信息时,可以获得很好的效果。

-
2. 相关概念
2.1 图像转换(image-to-image translation)
- 对称图像转换(pix2pix),使用对抗损失和重建损失形成输入和输出图像之间的映射。
- 非对称图像转换,没有目标域的对应样本,循环一致损失成为事实上的标准做法(例如CycleGAN),通过学习一个从目标域到输入图像的映射,来检查是否输入图像被正确映射到了目标域。之后的做法大多是在循环一致损失的基础上完成的(如UNIT,MUNIT)。
- 在非对称图像转换领域,循环一致损失主要在: 图 像 与 图 像 之 间 , 隐 空 间 到 图 像 , 图 像 到 隐 空 间 \color{red}图像与图像之间,隐空间到图像,图像到隐空间 图像与图像之间,隐空间到图像,图像到隐空间,三个层面上使用。
- 循环一致损失都基于输入域和目标域之间存在双射关系的严格假设, 当 某 个 域 的 图 像 由 相 较 于 另 一 个 域 更 多 的 信 息 时 就 更 难 获 得 很 好 的 效 果 \color{red}当某个域的图像由相较于另一个域更多的信息时就更难获得很好的效果 当某个域的图像由相较于另一个域更多的信息时就更难获得很好的效果。
2.2 关系保存(relationship preservation)
-
为了避开双射的限制,一个替代的想法是: 输 入 图 像 中 存 在 的 关 系 , 类 似 地 也 应 该 在 生 成 的 图 像 中 \color{blue}输入图像中存在的关系,类似地也应该在生成的图像中 输入图像中存在的关系,类似地也应该在生成的图像中,就比如同一张图内近似的图像块,在生成的图像中也应该有这样近似的图像块。
- TraVeLGAN, DistanceGAN and GcGAN通过预定义的距离函数保证共享相似的内容,或是使用triplet loss保存输入图像之间的向量计算;
- 计算输入图像之间的距离和生成图像的距离使之保持一致等等做法,绕开循环一致性损失的限制。
但是这些方法要么是需要预定义一个距离函数,要么保存的关系是基于整个图像的。
-
CUT是通过 最 大 化 互 信 息 的 方 法 \color{red}最大化互信息的方法 最大化互信息的方法,学习一个输入输出图像块之间的相似性函数,避免了以上的方法的缺陷。
2.3 深度网络的感知相似性度量
1. 大多是图像转换工作都是使用
逐
像
素
重
建
\color{blue}逐像素重建
逐像素重建进行度量,这无法反映人类的感知习惯并且会导致生成图片非常模糊。
2. 定义一个
高
维
信
号
的
感
知
距
离
函
数
\color{blue}高维信号的感知距离函数
高维信号的感知距离函数,这一点使用在ImageNet上预训练的VGG分类网络就可以实现 ,并且其在人类感知测试中取得了超过传统度量方法(SSIM and FSIM)的效果。但是这个方法没法适应其他的数据集,并且它也不是一个基于图像对的相似性度量。
ImageNet上预训练的VGG分类需要去了解!
- CUT以互信息作为约束,将图像本身中的负样本利用起来,可以适用于不同特定的输入输出域,从而避免了对相似性函数的预定义。
2.4 对比特征学习
1. 传统的无监督学习需要预先设计好的损失函数来衡量预测表现,新的方法通过最大化互信息绕开这个问题,使用噪声对比估计(
n
o
i
s
e
c
o
n
t
r
a
s
t
i
v
e
e
s
t
i
m
a
t
i
o
n
,
N
C
E
\color{red}noise\;contrastive\;estimation,NCE
noisecontrastiveestimation,NCE)来学习一个Encoder,将关联的信号拉近,并与数据集中的其他样本形成对比。
2. CUT首先将infoNCE loss应用到了条件图像生成领域。
3. CUT方法的数学表达
3.1 相关定义
- 图像输入域为
X
∈
R
H
×
W
×
C
\mathcal{X}\in\mathbb{R}^{H\times W\times C}
X∈RH×W×C 而输出图像域
Y
∈
R
H
×
W
×
3
\mathcal{Y}\in\mathbb{R}^{H\times W\times 3}
Y∈RH×W×3 ,数据集为
X
=
{
x
∈
X
}
,
Y
=
{
y
∈
Y
}
X=\{x \in \mathcal{X}\}, Y=\{y \in \mathcal{Y}\}
X={x∈X},Y={y∈Y}。
在CUT的方法中数据集可以只包含单张图像。 - 在CUT方法中,生成器被
G
G
G分解为两个部分, 先是一个
E
n
c
o
d
e
r
Encoder
Encoder再是一个
D
e
c
o
d
e
r
Decoder
Decoder,这样生成输出图像
y
^
\hat y
y^可以表示成:
y ^ = G ( z ) = G d e c ( G e n c ( x ) ) (3.1.1) \hat y=G(z)=G_{dec}(G_{enc(x)})\tag{3.1.1} y^=G(z)=Gdec(Genc(x))(3.1.1) - 最大互信息采用
N
o
i
s
e
C
o
n
t
r
a
s
t
i
v
e
E
s
t
i
m
a
t
i
o
n
(
N
C
E
)
\color{red}Noise\;Contrastive\;Estimation(NCE)
NoiseContrastiveEstimation(NCE)框架。对比学习的问题有三个信号组成:
q
u
e
r
y
和
正
样
本
,
负
样
本
\color{red}query和正样本,负样本
query和正样本,负样本,要做的就是让query和正样本信号相关联和负样本形成对比。
- 将query和正样本, 以及N个负样本,分别映射成
K
K
K维向量
v , v + ∈ R K , v − ∈ R N × K (3.1.2) v,\ v^+\in \mathbb{R}^K,\ v^-\in \mathbb{R}^{N\times K}\tag{3.1.2} v, v+∈RK, v−∈RN×K(3.1.2)
其中 v n − ∈ R K v^-_n\in \mathbb{R}^K vn−∈RK表示第 n n n个负样本。 - 将这些样本 归 一 化 至 单 位 球 \color{red}归一化至单位球 归一化至单位球中,防止空间扩张或坍缩。这样就形成了一个 N + 1 \color{red}N+1 N+1的分类问题。
- 交叉熵损失计算如下其中
τ
\color{red}\tau
τ是比例超参,常被称为温度系数,表示正样本被选中的概率。
ℓ ( v , v + , v − ) = − log [ exp ( v ⋅ v + / τ ) exp ( v ⋅ v + / τ ) + ∑ n = 1 N exp ( v ⋅ v − / τ ) ] (3.1.3) \color{red}\ell(v,v^+,v^-)=-\log\left[\frac{\exp(v\cdot v^+/\tau)}{\exp(v\cdot v^+/\tau)+\sum^N_{n=1}\exp(v\cdot v^-/\tau)}\right]\tag{3.1.3} ℓ(v,v+,v−)=−log[exp(v⋅v+/τ)+∑n=1Nexp(v⋅v−/τ)exp(v⋅v+/τ)](3.1.3)
- 将query和正样本, 以及N个负样本,分别映射成
K
K
K维向量
3.2 CUT的损失函数
3.2.1 GAN对抗损失
在GAN的图像生成部分,CUT仍然是使用GAN的对抗损失(此处用
B
C
E
BCE
BCE,也可以使用
M
S
E
MSE
MSE),保证生成的图像能和目标域的图像尽可能相似,这部分的损失就是:
L
(
G
,
D
,
X
,
Y
)
=
E
y
∼
Y
log
D
(
y
)
+
E
x
∼
X
log
(
1
−
D
(
G
(
x
)
)
)
(3.2.1)
\color{red}\mathcal{L}(G,D,X,Y)=\mathbb{E}_{y\sim Y}\log D(y)+\mathbb{E}_{x\sim X}\log(1-D(G(x))) \tag{3.2.1}
L(G,D,X,Y)=Ey∼YlogD(y)+Ex∼Xlog(1−D(G(x)))(3.2.1)
3.2.2 PatchNCE损失
- CUT用的对比学习,既有图像层次也有图像块层次,即:对整个输入、输出图像应该有着同样的结构,对应的图像块之间也应该有相应的结构 。此处用多层次图像块(multilayer patch-based) 的学习目标。
- 通过Encoder G e n c G_{enc} Genc编码特征层,其中不同层、不同空间位置代表了不同的图像块,层数越深图像块越大。
- 假设选择感兴趣的共
L
L
L层的特征图,将其通过2层
M
L
P
MLP
MLP网络
H
l
H_l
Hl产生的特征为:
{ z l } L = { H l ( G e n c l ( x ) } L (3.2.2) \{z_l\}_L=\{H_l(G^l_{enc}(x)\}_L\tag{3.2.2} {zl}L={Hl(Gencl(x)}L(3.2.2)
其中:- G e n c l G^l_{enc} Gencl表示第 l l l 层输出特征。 z l z_l zl表示第 l l l层特征。
- l l l表示层数( l ∈ { 1 , 2 , 3 , . . . , L } l\in\{1,2,3,...,L\} l∈{1,2,3,...,L}) ; s s s表示每层的patch数( s ∈ { 1 , 2 , . . . , S l } \ s\in\{1,2,...,S_l\} s∈{1,2,...,Sl}), 其中 S l S_l Sl表示第 l l l层有 S l S_l Sl个空间位置。
- z l s ∈ R C l z^s_l\in\mathbb{R}^{C_l} zls∈RCl表示第 l l l层里第 s s s个patch对于的特征向量的维度为 C l {C_l} Cl(或者说特征维度为 C l C_l Cl)。
- 如下公式表示第 l l l层,所有的patch S S S中除去 s s s的特征: z l S \ s ∈ R ( S l − 1 ) × C l (3.2.3) z^{S\backslash s}_l\in\mathbb{R}^{(S_l-1)\times{C_l}}\tag{3.2.3} zlS\s∈R(Sl−1)×Cl(3.2.3)
- 输出图像
y
^
\hat y
y^表示:
{ z ^ l } L = { H l ( G e n c l ( x ) } L (3.2.4) \{\hat z_l\}_L=\{H_l(G^l_{enc}(x)\}_L\tag{3.2.4} {z^l}L={Hl(Gencl(x)}L(3.2.4)
- CUT的目标是将输入输出对应位置的图像块进行匹配,同一张图像其他位置的图像块作为负样本,将损失记做PatchNCE loss(
ℓ
\ell
ℓ为公式(3.1.3)):
L P a t c h N C E ( G , H , X ) = E x ∼ X ∑ l = 1 L ∑ s = 1 S l ℓ ( z ^ l s , z l s , z l S \ s ) (3.2.5) \color{red}\mathcal{L}_{PatchNCE}(G,H,X)=\mathbb{E}_{x\sim X}\sum^L_{l=1}\sum_{s=1}^{S_l}\ell(\hat z^s_l,z^s_l,z^{S\backslash s}_l)\tag{3.2.5} LPatchNCE(G,H,X)=Ex∼Xl=1∑Ls=1∑Slℓ(z^ls,zls,zlS\s)(3.2.5)
3.3.3 External 损失
增加负样本 z ~ \tilde z z~,形成负样本字典 Z − Z^{-} Z−:
- 可以从数据集的其他图像中提取图像块做负样本记做 z ~ \tilde z z~;
- 可以像MOCO一样用一个辅助的移动平均Encoder
H
^
l
\hat H_l
H^l和移动平均
M
L
P
H
^
MLP\ \hat H
MLP H^共同计算。
L e x t e r n a l ( G , H , X ) = E x ∼ X , z ~ ∼ Z − ∑ l = 1 L ∑ s = 1 S l ℓ ( z ^ l s , z l s , z ~ l ) (3.2.6) \color{red}\mathcal{L}_{external}(G,H,X)=\mathbb{E}_{x\sim X,\tilde z\sim Z^-}\sum^L_{l=1}\sum_{s=1}^{S_l}\ell(\hat z^s_l,z^s_l,\tilde z_l)\tag{3.2.6} Lexternal(G,H,X)=Ex∼X,z~∼Z−l=1∑Ls=1∑Slℓ(z^ls,zls,z~l)(3.2.6)
3.3.4 整体损失函数
- 最终的目标函数,和CycleGAN一样也添加一致损失(identity loss)
L
P
a
t
c
h
N
C
E
(
G
,
H
,
Y
)
\color{red}\mathcal{L}_{PatchNCE}(G,H,Y)
LPatchNCE(G,H,Y),以使
E
y
∼
Y
∥
G
(
y
)
−
y
∥
1
\mathbb{E}_{y\sim Y}\|G(y)-y\|_1
Ey∼Y∥G(y)−y∥1尽量小避免生成器对产生的图片造成不必要的变化。所以总损失包含对抗损失,对比损失,一致损失三个部分。
L ( G , D , X , Y ) + λ X L P a t c h N C E ( G , H , X ) + λ Y L P a t c h N C E ( G , H , Y ) (3.2.7) \color{red}\mathcal{L}(G,D,X,Y)+\lambda_X\mathcal{L}_{PatchNCE}(G,H,X)+\lambda_Y\mathcal{L}_{PatchNCE}(G,H,Y)\tag{3.2.7} L(G,D,X,Y)+λXLPatchNCE(G,H,X)+λYLPatchNCE(G,H,Y)(3.2.7) - CUT模型和FastCUT模型
- 当使用 λ X = 1 , λ Y = 1 \color{red}\lambda_X=1,\ \lambda_Y =1 λX=1, λY=1联合训练时称为CUT;
- 当取 λ Y = 0 \color{red}\lambda_Y=0 λY=0时,作为补偿取 λ X = 10 \color{red}\lambda_X=10 λX=10时称为FastCUT, 可以被看做是更快更轻量级的CycleGAN。
4. 实验
4.1 数据下载
下载网址:https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets,我下载了horse2zebra.zip进行实验。
4.2 pycharm中配置参数
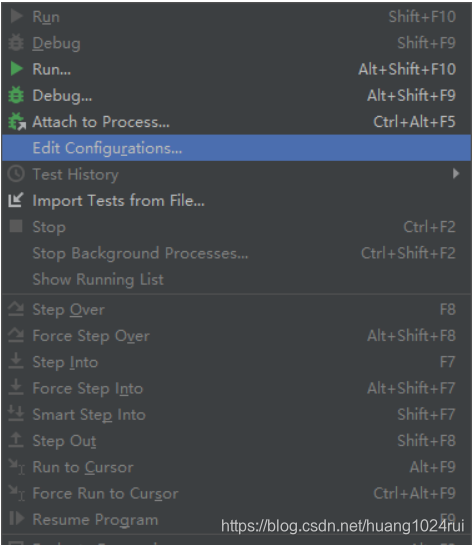
- 点击上面窗口中的
run,然后选择Edit Configurations
- 输入:
--dataroot ./datasets/horse2zebra --name horse2zebra_CUT --CUT_mode CUT
4.3 安装和运行visdom库
参考:Visdom库(pytorch中的可视化工具)安装问题的解决方案及使用方法详解
迭代190次的效果

4.4 Internal Patches Vs External Patches
- 构造的负样本是从目标图像其他位置选的patch(本文称之为Internal Patches),
- 从其他图像选一些patch来当做负样本(本文称之为External Patches),本文就做了关于这个问题的对比试验:
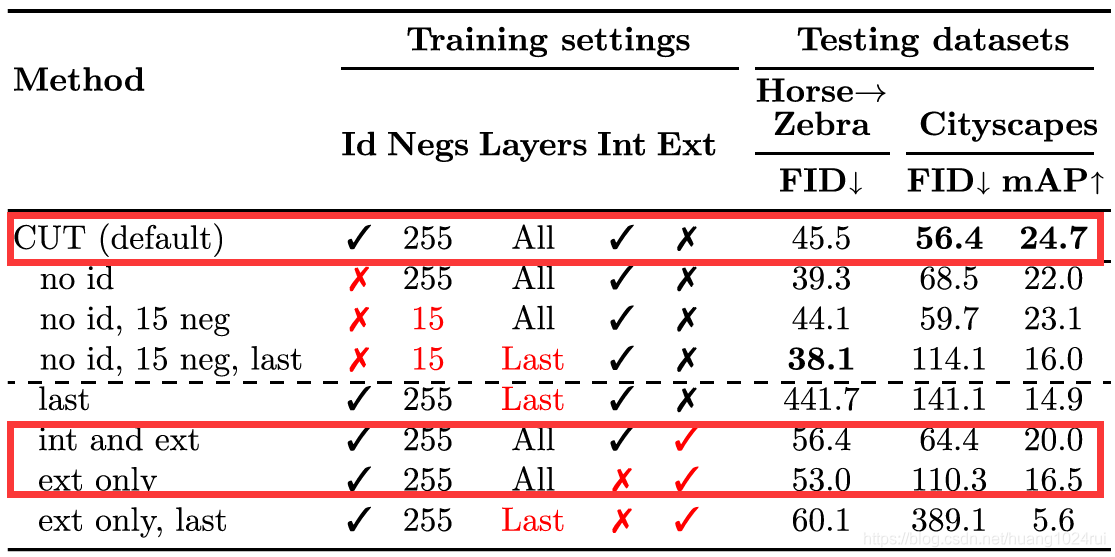
可以看出来,在仅有External Patches和Internal Patches+External Patches的情况下,对比只有Internal Patches,性能都有不同程度的下降。这里文中给出了一点直观的解释:作者认为:It’s because the external patches are too easy to distinguish, and they sometimes contain false negatives, like the highlighted horse head patch.
4.5 实验评价
CUT从图像质量和发现对应关系的能力上进行评价:
- 图像质量通过 F I D FID FID(Frechet Inception Distance) 进行度量;
- 发现对应关系的能力使用生成器Encoder的第一个残差块,可视化输出对应图像块特征的相似性,并通过PCA可视化主成分,验证了Encoder学到了相似性函数。
此处不是很懂。
4.6 出现问题的解决
- Q:
AttributeError: Can't pickle local object 'Visdom.setup_socket.<locals>.run_socket'
解决:If your OS environment is windows, try changing the default "num_threads" argument to 0 in base_option.py in the options folder.
5. 个人理解
5.1 相较于CycleGAN
- CUT只需要1个生成网络和一个判别网络,使得训练速度更加快。
- CUT用了Multilayer Patchwise Contrastive loss,损失函数不仅仅是pixel-to-pixel层面。
- CUT的映射没有要求是双射。
- 虽然CycleGAN的Discriminater用了PatchGAN,但是CUT用了信息熵进一步增强的正负样本之间的距离。
5.2 相较于传统对比学习(MoCo、SimCLR)
- 传统对比学习用same image+ random image 作为负样本不同,CUT只对same image进行处理,所有的patch都是来自于same image.
- CUT增加了Identity Loss,进一步优化图像的质量。

















 1345
1345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









