









0.
先通过一个例子引入:
例子转自:http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html

如果对树结构有所了解的话,很容易生成一个树,
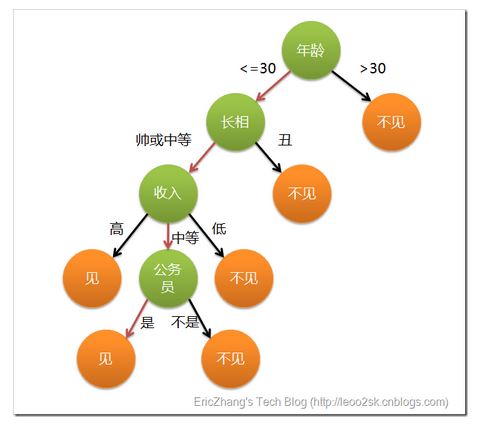
这就是一个决策树,通过这个树就可以判断出女孩到底会不会去见一个相亲对象。
我们可以看到决策树描述了整个做决定的过程,它和人们实际做决定的过程非常的类似,有着很强的可解释性。
总结一下,这是一个二分类问题,我们可以通过判断相亲对象的年龄,长相,收入等去判断这个女孩会不会去见面。
1.
上面只是举了一个例子引入决策树算法,实际上,想要构造一个可以解决二分类问题的决策树没有这么简单。我们需要根据训练样本去学习得到决策树。
构造一棵决策树,首先面临的一个问题是:并不是所有的特征都像上面举得例子那样,有着很强的实际意义的。更多的时候,特征只是一个数值,没有什么明确的物理含义,该选择哪些特征作为树的节点,阈值该设成多少?
我们可以想象一下这个问题,直觉上,我们会选择能尽量使样本分开的特征和阈值。这也就是说 训练集经过这个特征和阈值划分成两部分,两个部分的类别要尽量单一,通常称为纯度,纯度越大越好。假设0/1二分类问题,经过划分之后,我们希望一部分里全是0类别,另一部分全是1类别。我们会选择能达到这样效果的特征和阈值作为树的节点。
生成决策树有很多不同的算法,有ID3,C4.5,C&RT等算法,他们使用不同的衡量指标去选择切分的特征和阈值。虽然衡量指标不一样,不过大体上都是使切分后的纯度尽量大。
我们在这里详细介绍一下C&RT算法,C&RT算法在生成分类决策树的时候是通过Gini系数进行特征和阈值选取的。
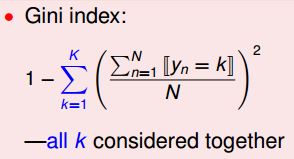
可以看一下Gini系数公式所代表的物理含义:Gini系数可以大概描述切分之后的样本的纯度。
C&RT算法生成决策树的基本步骤如下:
1. 遍历每个特征的每一个阈值,计算Gini系数找到最好的分割点
2. 分割成两个节点N1和N2
3. 对N1和N2分别继续执行1-2步,直到每个节点足够“纯”为止(类别足够单一)
这个时候,会发现只要次数足够多,切分到最后肯定就可以使树的叶子的类别是单一的。这时决策树的叶子就可能很多,决策树就会变得很大。我们在前面说过模型变得很复杂的话,就很容易产生过拟合(overfitting)的问题。我们在这里通过加入约束项去对生成的决策树进行修剪。

在这里我们用叶子的数量去衡量决策树的模型复杂度。加入叶子的数量作为约束项,达到平衡
Ein
和模型复杂度的目的。
G(0)
表示没有修剪的决策树,
G(1)
表示去掉一个叶子的决策树,
G(2)
表示去掉一个叶子的决策树………
然后就是从这些决策树中选择一个,使
Ein(G)+λΩ(G)
最小,作为修剪之后的决策树。
决策树就是这么构建起来的,我们可以看出来决策树有着很强的可解释信,很符合人的思维习惯。同时它也有着一些缺点,它并没有很强的理论保证,很多情况都是从直觉上感觉有道理,并没有什么理论保证。
2.
森林是什么?很多树就构成森林了。
那随机森林就是由许多决策树通过模型融合的方法构成的,而且这些决策树的生成具有一定的随机性。
g1,g2,...,gn
代表n个随机生成决策树,通过前一讲说的模型融合方法,将这n个决策树融合成一个模型,这个就是随机森林了。
现在的问题是:怎么生成这n个具有随机性的决策树呢?
这个有很多途径。
(1)、假设样本是通过100维特征表示的,可以随机从这100维特征中挑出来50个特征去生成决策树。
(2)、将特征乘以一个随机生成的映射矩阵,对特征进行映射,然后学习相应的决策树。
(3)、前面所说的,bootstrapping方法,随机有放回的挑选样本作为训练集。
。。。。。等等(开动你的小脑袋,想到什么就去试一试吧)
这些方法都可以随机生成决策树。
理论上,决策森林所包含的决策树的数量是越多越好。
3.
扯点关于特征选择的内容。
决策树可以进行特征选择。生成决策树的时候会通过计算纯度去选择特征作为切分点,我们一定程度上就可以认为作为切分点的特征是比较重要的。因为这个特征可以很大程度将样本划分开,所以就可以认为这个样本是重要的。
类似的,线性模型可以进行特征选择。我们知道,在线性模型的学习过程中,我们为每一个特征学习一个权重,我们可以认为权重值的大小可以代表对应特征的重要程度。越重要的特征所对应的权重值越大。
还有一个比较常用的求某个特征的重要性的方法是permutation test。
假设样本是用10维特征表示的,我们想知道第三个特征的重要性程度。我们将所有样本的第三个特征值打乱顺序重新赋值,然后用现在这样的样本重新训练一个模型,计算这个模型在测试集上的表现。比较现在这个模型和原来模型的表现的差距,和原来模型的表现差的越多,那就说明这个特征就越重要。
















 588
588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









