









学习理论
主要想表达的东西
想一下,在什么样的情况下,我们会想到机器学习。可能你在碰到这么一个问题时:你现在有很多有癌症和没有癌症的人的身体情况资料,然后让你判断一个人是否患有癌症。在你碰到这个问题的时候,你会说现在有了现成的训练集,我把它扔到机器学习算法里去学习一下,学习出来一个模型,然后就可以做判断了啊!!这很easy啊。在这一讲里面,我想说的就是,为什么这么做是有效的?在这个看起来很easy的做法背后有什么样子的理论去支撑它?我觉得这个问题值得拿出来专门讲一讲,它贯穿着整个机器学习。
1.
我们先看看 “你会说现在有了现成的训练集,我把它扔到机器学习算法里去学习一下,学习出来一个模型,然后就可以做判断了啊!!” 这个过程中,发生了什么。“把训练集扔到机器学习算法里去学习一下,得到一个模型。”在这一步,实际上就是学习得到一个模型h,这个模型h对训练集里的样本而言误差很小,E_in(h)≈0。“然后就可以用这个模型去判断训练集之外的样本了”,在这一步实际上我们默认了一个东西,这个模型对训练集以外的样本的误差也是很小的。E_out(h)≈E_in(h)。我们很自然不自觉就认为这是理所当然的。可实际上,这个并不一定是对的。上面所提到的E_in(h)≈0和E_out(h)≈E_in(h),机器学习所做的事情就是去想尽各种办法寻找一个h保证这两个式子的成立,只有这两个式子成立,机器学习所得到的模型才能真正有效果。在这里,我们的重点是第二个式子,我们非常有必要去弄清楚训练集内的误差E_in(h) 和训练集外的误差E_out(h) 之间的关系。
2.
这里先解释一下 “上面所提到的E_in(h)≈0和E_out(h)≈E_in(h),机器学习所做的事情就是去想尽各种办法寻找一个h保证这两个式子的成立” ,为什么这么说呢?
例如上面所提到的那个判断人是否有癌症的问题,现在假设有一个非常非常完美的模型f,f可以对所有的人(已知的未知的)做出正确的判断,即E_out(f)=E_in(f)=0。我们想知道这个模型f是什么样子的,可是我们没有直接的办法去求它,所以机器学习所做的事情是想从假设空间中找到一个很接近模型f的模型h,就可以认为h在一定程度上就可以代替我们真正想寻找的模型f了。如果模型h满足了那上面两个式子,那么就会有E_out(h)≈E_in(h)≈0,所以模型h就可以一定程度上代替模型f。(注:假设空间:我们说的一个算法的假设空间指这个算法所能生成的所有可能模型的一个集合,例如:如果某个算法只能产生 h=wx+b 这种类型的模型,那么我们就说这个算法的假设空间是所有直线的集合,这个算法的工作就是从假设空间中找到最接近理想直线f的那条直线h)。
在这里我觉得有必要说一下一些学习理论里面的专业名词了,不同的资料对同样的东西的叫法并不一样。E_in可以说成训练误差,经验误差,training error,empirical risk, empirical error。 E_out 被称为 generalization error,泛化误差,生成误差。我们可以发现,E_in并不能真正反映你的模型到底是好是坏,E_out这个误差才能真正地反映模型的预测的准确性。
经常可以看到泛化,到底什么是泛化?我所理解的就是,我们用训练集去训练得到一个模型,然后把这个模型运用到训练集以外的样本上,这个过程就称为泛化。把这个模型运用到训练集以外的样本上的表现的好坏称为泛化能力。模型h的泛化能力强是指:当E_in(h)≈0时,然后把模型运用到训练集以外的样本上所得到的E_out(h)≈0。模型h的泛化能力弱是指:当E_in(h)≈0时,然后把模型运用到训练集以外的样本上所得到的E_out(h)>>0,这也就是通常所说的过拟合(overfitting)。
对一个名词的说明:本文中所出现的“模型”一词,在本文中的解释是模型就是某一个h。“机器学习算法产生通过训练得到一个模型”,这句话的意思就是机器学习在假设空间中的众多h中找到一个最好的h,这个最好的h就是机器学习算法得到的模型。h又是什么呢?可以先简单的理解成某一个h是一个固定的函数。例如这个假设空间里面所包含很多不一样的直线,h=wx+b(w,b各不相同)。那么机器学习算法需要做的就是从这么多条直线中挑选出最好的那一条直线(
h∗=w∗x+b∗
)作为输出模型。
3. 正式步入正题
接下来所写的主要是参考《斯坦福机器学习公开课》和《台湾大学机器学习基石公开课》。
我们如何去求出来E_in和 E_out的关系呢?
E_in是一个小集合样本里面的错误出现概率。E _out是一个大集合样本里面错误出现的概率。这个小集合和大集合都是服从同一分布的。是不是突然想到了高中所学的那一点点概率论的知识了。 原来你肯定遇到过一个这样的概率论问题:让你统计一个非常大的集合里面,某一个事件出现的概率。我们当时是这么做的:从这个大集合里面去随机挑出来一个小集合,然后在这个小集合里面求出这个事件出现的概率,然后我们就可以很高兴的说大集合里面这个事件出现的概率就是这么多了。这个现在来看虽然当时的做法有些不严谨,不过确实是有一些合理性的。 霍夫丁不等式保证了我们的做法的合理的。
图片出自《机器学习基石课件》
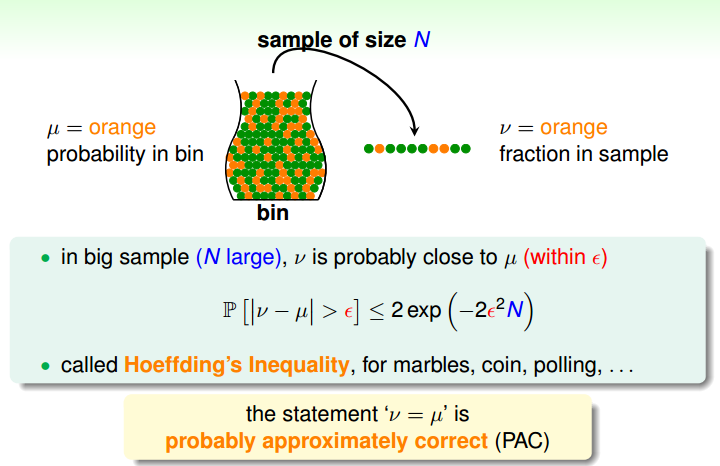
在图片中可以看出,我们用抽样出来的橘色小球的概率去出现估计瓶子里橘色小球的概率。霍夫丁不等式保证了
|v−μ|>ε
出现的概率有一个上界。
可以把这种思想引入到机器学习中。
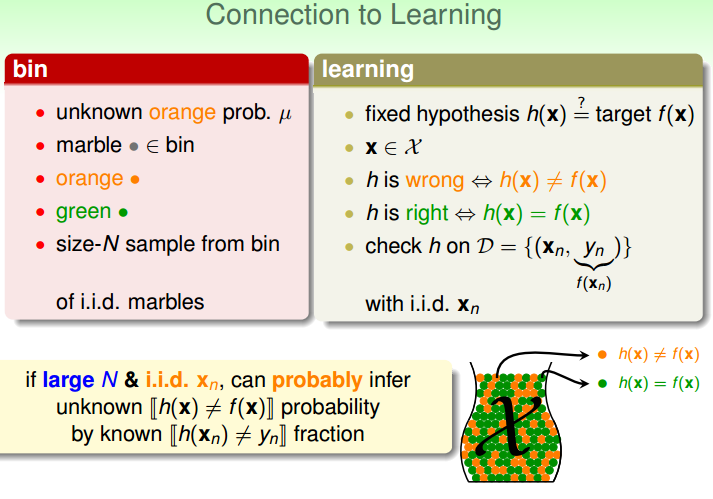

重点来了,看上图最开始的地方有一个限定,for any fixed h, any fixed h, fixed h,顿时心中一万头草泥马奔腾而过,这不是扯淡么~~算法所做的事就是从假设空间中找到那个最佳的h(上面已经对这个做了解释),假设空间里面有那么多h,我怎么知道我找到的h就是满足上面那个不等式的?所以说现在就要想办法把fixed h扩展到假设空间中的所有h。问题又来了,假设空间有可能无限大唉!!所以就必须要分开讨论。当假设空间是finite的怎样?当假设空间是infinite的怎样?
4.假设空间是finite(有限大)的情况
*我们先令假设空间H里面有k个可能的h
P(∃h∈H.|E_in(h)−E_out(h)|>ε)=P(|E_in(h1)−E_out(h1)|>ε∪|E_in(h2)−E_out(h2)|>ε∪...∪|E_in(hk)−E_out(hk)|>ε)≤∑ki=0P(|E_in(hi)−E_out(hi)|>ε)=2kexp(−2εN)
上面的式子意思就是在一个集合中至少一个事件发生的意思是第一个事件发生或者第二个事件发生或者….最后一个事件发生。
事件的并表示至少有一个发生,故事件A,B,C中至少有一个发生可表示为A∪B∪C。
A∪B∪C发生的概率是小于每个事件发生概率之和的。(通过集合论中的韦恩图可以直观看出来)
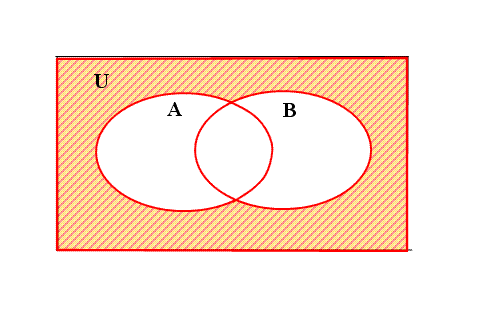
继续:
P(!∃h∈H.|E_in(h)−E_out(h)|>ε)=P(∀h∈H.|E_in(h)−E_out(h)|≤ε)≥1−2kexp(−2εN)
注意:!表示非的意思。
对假设空间中任意的h,
|E_in(h)−E_out(h)|≤ε
的概率是大于
1−2kexp(−2εN)
的。我们终于可以丢掉前面那个fixed h的限定了。
也就是说对假设空间中所有的h,当
N≥12ε2log(2kδ)
时,有
1−δ
的概率使
|E_in(h)−E_out(h)|≤ε
,
δ=2kexp(−2εN)
。
当抽样的样本数量N足够大的时候,就可以说E_out(h)≈E_in(h)了。
5.假设空间是infinite(无限)的情况
在这里,我们直接引入VC理论,只进行说明,没有证明。VC维的证明有点复杂了,我也只是知道好像大概或许是那么回事,而且我觉得关于VC维理论,我们省略掉证明过程,并不会妨碍我们对它的理解。出于尊敬,必须说一下,VC理论是机器学习中最最经典的几个理论之一。

为什么要引入VC维?在4中,当假设空间是有限大的时候,我们就可以用假设空间里面包含的h的个数k去衡量这个算法所产生的模型的复杂程度。(算法是从假设空间挑选出来一个最好的h作为输出模型。做一个不是特别恰当的比喻:想象一下,现在有两种情形A:如果假设空间中可供选择的数量是8的话,那就意味着必须要有3个二进制位才能把8个东西表示下来;B:如果假设空间中可供选择的数量是16的话,那就意味着必须要有4个二进制位才能把16个东西表示下来。现在分别从A和B的假设空间中挑一个作为输出的话,A挑出来的是一个3位的二进制数,而B挑出来的是一个4位的二进制数,显然4位的二进制数比3位的二进制数复杂,不过正是因为它是4位的,所以它对应到B情形中,B情形可供选择的数量才能比A情形多8个。所以可供选择的数量可以衡量这个算法所产生的模型的复杂程度,一般认为数量越多模型越复杂)。现在假设空间的大小是无限大的,我们没有假设空间的大小这种类似的衡量指标了,所以这个时候就需要引入了VC维。
VC维:我自己的理解非常直观,它可以代表这个算法所产生模型的复杂程度。这个算法它最后输出的模型越复杂,那这个算法的
dvc
就越大。反着,亦然。
关于VC维的具体定义,我并不想在这里做过多的介绍,以后可能会在具体的算法中介绍到。具体可参照下面这篇博客,或者百度自行搜索
**随手一搜
http://www.cnblogs.com/wuyuegb2312/archive/2012/12/03/2799893.html**
6.
接下来就会有一些比较有意思的事情发生:
我们从4.中得到这个(a):
当 N≥12ε2log(2kδ) 时,有 1−δ 的概率使 |E_in(h)−E_out(h)|≤ε , δ=2kexp(−2εN) 。
我们从5.中得到这个(b):
通过观察你会发现什么规律?
(a):
如果N变大,
E_in(h)和E_out(h)
的差距会变小。
如果k变大,
E_in(h)和E_out(h)
的差距会变大。
(b):
如果N变大,
E_in(h)和E_out(h)
的差距会变小。
如果
dvc
变大,
E_in(h)和E_out(h)
的差距会变大。
N变大,
E_in(h)和E_out(h)
的差距会变小。 这个我们直观上可以理解的,从大集合挑选的样本数量越多,越能衡量大集合的分布。
重点看当k和
dvc
变大,
E_in(h)和E_out(h)
的差距会变大。 k和
dvc
是描述什么的?算法输出的模型的复杂程度的。那么这个变化过程就可以解释成:算法所产生的模型越复杂,这个模型的泛化能力就越差,那这个模型在训练集中的误差和在训练集外的误差 相差的就越多。
如果单从泛化能力来看,我们希望我们产生的模型的复杂度越小越好。
回想一下,我们在2.的里面说过“上面所提到的E_in(h)≈0和E_out(h)≈E_in(h),机器学习所做的事情就是去想尽各种办法寻找一个h保证这两个式子的成立”,如果我们一味的降低我们产生的模型的复杂度的话,E_out(h)≈E_in(h)这个式子会越来越好。
可是问题是E_in(h)≈0这个式子会怎么样啊?答案是随着模型的复杂度的降低,E_in(h)会越来越大于0。(为什么?最简单解释是:我们如果想去描述一件物品,例如苹果,我们用的描述词越多,我们对这个物品的描述就会越好。当然实际情况稍微有点偏差,随着描述词越来越多,对描述效果的影响会越来越小。这个就像是你用2个词比用1个词对描述效果的提升是巨大的;可是如果你用10个词和你用9个词的话,这时候对描述效果的提升就微乎其微了)。
现在问题来了!!!
我们想要同时满足两个式子,这不是矛盾的么!!!
模型复杂度越小,E_out和E_in就越接近,可是E_in就越不接近0。
模型复杂度越大,E_in就越接近0,可是E_out和E_in就越不接近。
这就是矛盾的,而且这个矛盾贯穿这个整个机器学习。而且我认为如果机器学习如果不存在这个矛盾的话,那就会变得很没意思!!
这个矛盾还可以称作偏差(bias) 和 方差(variance)的矛盾,欠拟合(underfitting)和过拟合(overfitting)的矛盾。
模型复杂度越小,E_out和E_in就越接近,可是E_in就越不接近0,这时variance会变小,bias会变大,导致欠拟合(underfitting)的问题。
模型复杂度越大,E_in(h)就越接近0,可是E_out和E_in就越不接近,这时bias会变小,variance会变大,可能导致过拟合(overfitting)的问题。
就像下图所描述的一样。图中的out-of-sample error就是E_out,in-sample error就是E_in。随着模型复杂度(model complexity)的变大,E_in会变得越来越小,不过减小速度越来越慢,到最后会趋于直线;E_out是先减小,后变大的(这个减小过程可以理解成:刚开始模型复杂度不是特别大,E_out和E_in的差距很小,随着模型复杂度的增加,E_in的减小幅度非常大,虽然说E_out和E_in的差距会变大,不过这时的决定因素是E_in的减小,所以E_out(h)也会被带着减小。那个增加的过程的理解成:这个时候的模型复杂度已经很大了,随着模型复杂的增加,E_in的减小已经趋向于平缓了,这时E_out和E_in的差距变得越来越大,虽然这个时候E_in会减小,不过这时的决定因素变成了E_out和E_in差距的变大,所以E_out会增加)。

所以最好的模型是最能平衡这两个问题的模型,而不是一味将一个方面做到极致的模型。
我们在这里不讲怎么去平衡这两个矛盾,我们只是将这个矛盾呈现出来。我认为,带着这种矛盾去学习机器学习会有更多的收获。















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









