







交流请加群:580043385
我的知乎专栏同步发布:https://zhuanlan.zhihu.com/p/22542101
转载请标明出处:http://blog.csdn.net/ikerpeng/article/details/53031551
本文是强化学习的基础,主要参考 Divid Silver 教程,Reinforcement Learning:An Introduction,以及周志华的西瓜书。
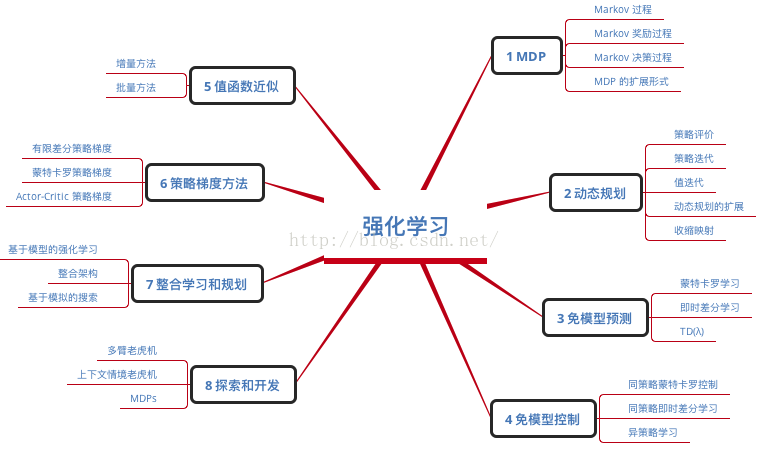
可能之前大家已经听过了强化学习的介绍,因此,我首先问几个问题:
强化学习和MDP过程是一回事吗?
强化学习和监督学习的区别是什么?
什么是值迭代,什么是策略迭代?
有模型和无模型的强化学习的各自有什么样的学习方法?
强化学习和深度学习其实很早就有了,为什么深度强化学习到了2013才开始爆发?
总体理解:
强化学习指的是在一系列的情景之下,通过多步恰当的决策来达到一个目标的学习过程,是一种序列多步决策的问题。强化学习的目标就是要寻找一个能使得我们获得最大累积奖赏的策略。强化学习的最终奖赏在多步动作之后才能观察到,可以看出强化学习有别于传统的机器学习,是不能立即得到标记的,而只能得到一个反馈,也可以说强化学习是一种标记延迟的监督学习。
强化学习任务通常通过马尔科夫决策过程来描述:对于处于环境E当中的状态为s(s属于状态空间S)的感知单元M,它采取某种动作a(a属于 动作空间A)达到另一状态s‘,得到的奖励为r(r属于奖励R);所以整个过程可以表示为:M=<S,A,S',R>。过程中执行的某个操作时,并不能立即获得这个操作是否能达到目标,仅能得到一个当前的反馈。因此需要 不断摸索,才能总结到一个好的策略 。摸索这个策略的过程,实际上就是强化学习的过程。
通常来讲每一个动作的奖励并不是以一个固定的值出现的,而是以一定的概率分布出现。因此,需要不断的去尝试出,到底各个动作的期望奖励是多少,这个过程被称作是探索(Exploration)的过程(这个过程一般来平均的去尝试每一种动作,通过很多次(越多越好,越准确)的尝试得到每一个动作的期望的结果,这种方式最大的问题是:你知道当前期望最高的奖励,但是为了探索你就失去了使用当前最好的机会);另一种方式被称作是利用(Exploitation),既然当前已经得到了最大期望的动作,那就直接使用它就好了(这种方式,应用了当前最好的策略,但是它仍然是以一定概率出现而已,说不定你还是得不到最大的;另一点,这样不去探索,万一最好的还在后面勒?)。
文章还是从一个周志华课本当中的例子开始:

摇臂赌博机是用来理解强化学习很好的一个例子,但是不足之处就是它一步就获得了最终的奖励。如图所示假设摇臂赌博机存在5个臂,玩家在投入一个硬币以后可以按下其中的一只臂。每个臂以一定的概率吐出硬币(假设吐出的个数分别为:5个,5个,10个,2个,2个),但是玩家并不知道。玩家的目的就是要通过一定的策略进行选择最大化收益,也就是得到尽量多的硬币。
在这个当中就开始采取探索和利用的方式。假设我很有钱,不怕花钱。于是我分别花了1000块测试了每一个摇臂出币的概率,最终测试的结果是1,2,3,4,5号臂分别出币的次数是100,200,100,50,150,那么我就可以知道每一个摇臂的出币的概率分别为:10%,20%,10%,5%以及15%。那么我们就知道在某一个状态下投入一颗币,采取选择第一只臂的策略得到的期望奖励值为:0.5个硬币,之后的摇臂依次为1个,1个,0.1个,0.3个。
那么在接下来,我们直接采取其中期望收益最高的2或者是3号策略就好了。那么其实我们会发现也许要发现这样一个分布情况,也不根本就不需要测试这么多次就可以得到。这样也是节约成本以及增加收益的一种方式。但是,你也可能会觉得,1000次还不够,尝试的次数越多越接近真实的概率,于是你在每一个臂上面测试直到一万次,然后之后的每一次都执行其中期望最大的策略。
其实我们在探索的过程中也是摇消耗资源的,因此从最大收益的角度讲,大量的进行探索并不是一种好的策略;而不进行探索也是差的策略。因此采用:ϵ-greedy算法: 就是以ϵ 的概率进行探索,采用1-ϵ的概率使用当前最好的策略。这样是在探索和利用当中的一个平衡。
我们这样来表示摇臂k在经历过n次尝试以后得到的平均奖励:
 上式当中需要记录每一次的奖励值,显然更加高效的方式是引入增量式计算,记录好上一次的平均奖励,然后用这次的收益来更新平均奖励:
上式当中需要记录每一次的奖励值,显然更加高效的方式是引入增量式计算,记录好上一次的平均奖励,然后用这次的收益来更新平均奖励: 

MDP:
马尔科夫决策过程可以表示为:M=<S,A,Pss′,S',R> :
状态集合S: 有限状态state集合,s表示某个特定状态
动作集合A: 有限动作action集合,a表示某个特定动作
状态转移矩阵P: 矩阵每一项是从S中一个状态s转移到另一个状态{s’}的概率
Pss′=P[St+1=s′|St=s]以及执行动作a后从一个状态转移到另一个概率为
Pss′a=P[
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8071
8071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









