







 本文深入分析了zip压缩算法中Huffman编码的原理和实现,包括编码树的概念、Huffman编码算法、zip如何使用和实现Huffman树。通过详细解读源码,阐述了length、literal和distance数据的组织方式,以及建树和编码的过程。
本文深入分析了zip压缩算法中Huffman编码的原理和实现,包括编码树的概念、Huffman编码算法、zip如何使用和实现Huffman树。通过详细解读源码,阐述了length、literal和distance数据的组织方式,以及建树和编码的过程。
zip压缩算法分析(2)
前言
在zip压缩算法分析(1)中已经分析了利用文本中短语重复的特性来进行压缩的lz77算法部分,接下来分析利用信息熵进行压缩的huffman编码算法,zip作者在这里对霍夫曼树的处理十分精彩,huffman树本身就已经很cool了,简直无法想象还能有这么流弊的改进。
gzip源码下载地址 参考资料 1 参考资料 2
huffman编码是很有名的一种压缩编码方式,网上,书上都有很多描述;其主要思想如下:
给出文本中所有字符c与各个字符出现频率f组成的字符表S[2, n],比起定长编码,一个比较明智的编码方法是将频率大的赋予较短的编码,频率小的则赋予较长的编码。那么究竟该如何分配呢?
1.编码树的概念。
为了便于解码,这里只使用前缀码(从实际含义上来讲,应该是无前缀码,但是由于权威文献中都使用这种坑爹翻译就只好随大流了),原因如图:
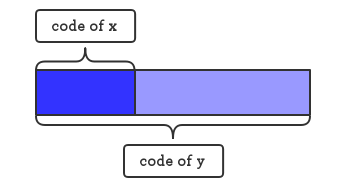
如果字符x的编码成为了字符y编码的一个前缀,那么很明显地,在解码时可能无法分辨是x还是y。考虑如图的一棵树:
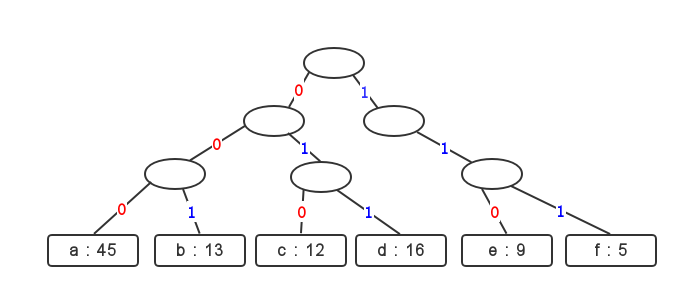
所有字符与其在文本中出现的频率构成这棵树的所有叶节点,由叶节点到根节点的路径决定了该字符的编码,因此编码树就成为了表示前缀编码方案的一个极好的模型:对于2个不同叶节点,不可能存在一个编码为另一个编码前缀的情形。
2.Huffman编码算法
Huffman给出了一个构造最优编码树的贪心算法,其正确性证明见《算法导论》(第三版)16章第三节。算法如下:
Huffman(C) //C 为带频率的字母表
n = |C|; // n = C 字符数目
Q = C; //用C初始化一个最小优先队列Q
for i = 1 to n - 1
allocate a new node z
z.left = x = EXTRACT-MIN(Q) //取出最小节点
z.right = y = EXTRACT-MIN(Q)
z.freq = x.freq + y.freq
INSERT(Q, z)
return EXTRACT-MIN(Q)
主要思想是用最小优先队列装载字母表,每次循环将频率最小的2个节点取出,合并为一个新节点,
再插入队列,直到队列只剩一个节点为止。
霍夫曼编码的原理讲解到此打住,接下来说一说zip压缩算法为何使用 以及如何实现霍夫曼树的。
zip压缩算法分析(1)中分析的lz77压缩算法部分已经利用重复出现的短语进行了压缩,短语式重复的倾向已被破坏,无再次进行lz77的条件。但此时压缩后输出的几种形式的压缩数据:(distance, length), literal仍然在信息熵方面上有压缩的可能,就是说,不同的distance,length, literal在lz77输出流中的频率可能存在较大差距,这样就可以用huffman编码继续对其进行压缩。
huffman编码的主要部分位于tree.c文件中,既然是源码分析,接下来就上码吧:
头部注释
/* trees.c -- output deflated data using Huffman coding
* trees.c -- 对deflate()处理过后的数据使用霍夫曼编码
* Copyright (C) 1992-1993 Jean-loup Gailly
* This is free software; you can redistribute it and/or modify it under the
* terms of the GNU General Public License, see the file COPYING.
*/
/*
* PURPOSE
*
* Encode various sets of source values using variable-length
* binary code trees.
* 使用二进制变长编码树来编码各种值。
*
* DISCUSSION
*
* The PKZIP "deflation" process uses several Huffman trees. The more
* common source values are represented by shorter bit sequences.
* PKZIP的"deflation"算法使用了一些霍夫曼树,出现频率越高的值用越短的bit序列编码。
*
* Each code tree is stored in the ZIP file in a compressed form
* which is itself a Huffman encoding of the lengths of
* all the code strings (in ascending order by source values).
* (此处更倾向于意译而非直译,因为我觉得理解这几句话比看懂这个句子更重要)
* 编码树的实现方式是:按照源数据(即lz77压缩后输出的length, distance, literal)
* 所有可能值从小到大顺序,将它们的霍夫曼码长(只记录长度!很神奇吧)记录在数组里。
* The actual code strings are reconstructed from the lengths in
* the UNZIP process, as described in the "application note"
* (APPNOTE.TXT) distributed as part of PKWARE's PKZIP program.
*
* REFERENCES
* 一些相关算法知识的参考书籍
* Lynch, Thomas J.
* Data Compression: Techniques and Applications, pp. 53-55.
* Lifetime Learning Publications, 1985. ISBN 0-534-03418-7.
*
* Storer, James A.
* Data Compression: Methods and Theory, pp. 49-50.
* Computer Science Press, 1988. ISBN 0-7167-8156-5.
*
* Sedgewick, R.
* Algorithms, p290.
* Addison-Wesley, 1983. ISBN 0-201-06672-6.
*
* INTERFACE
* 3个接口
* 1.初始化函数
* void ct_init (ush *attr, int *methodp)
* Allocate the match buffer, initialize the various tables and save
* the location of the internal file attribute (ascii/binary) and
* method (DEFLATE/STORE)
* 2.计数器函数
* void ct_tally (int dist, int lc);
* Save the match info and tally the frequency counts.
* 3.
* long flush_block (char *buf, ulg stored_len, int eof)
* Determine the best encoding for the current block: dynamic trees,
* static trees or store, and output the encoded block to the zip
* file. Returns the total compressed length for the file so far.
*
*/和上篇文章一样,分析是以3个interface函数为主要对象的,在分析源码的同时补充相关信息。
之所以这么安排是因为前面的常量和宏太尼玛多了,全部列出来,谁记得住啊?只有从对函数
的解读中才比较方便认识理解这些常量,宏。毕竟这些量说到底还是为了函数而存在的。
函数ct_init
代码:
/* ===========================================================================
* Allocate the match buffer, initialize the various tables and save the
* location of the internal file attribute (ascii/binary) and method
* (DEFLATE/STORE).
* 为匹配块收集空间,初始化变量表并存储文件属性(ASCII编码/二进制编码)与压缩方案
* (压缩/仅存储)
*/
void ct_init(attr, methodp)
ush *attr; /* pointer to internal file attribute */
int *methodp; /* pointer to compression method */
{
int n; /* iterates over tree elements */
int bits; /* bit counter */
int length; /* length value */
int code; /* code value */
int dist; /* distance index */
file_type = attr;
file_method = methodp;
compressed_len = input_len = 0L;
if (static_dtree[0].Len != 0) return; /* ct_init already called */
/* Initialize the mapping length (0..255) -> length code (0..28)
* 初始化映射 0到255的length值 -> 30个length区间码
* 这个区间压缩方案实在太厉害了,详情见该函数源码下方注1。
*/
length = 0;
for (code = 0; code < LENGTH_CODES-1; code++) {
base_length[code] = length;
for (n = 0; n < (1<<extra_lbits[code]); n++) {
length_code[length++] = (uch)code;
}
}
Assert (length == 256, "ct_init: length != 256");
/* Note that the length 255 (match length 258) can be represented
* in two different ways: code 284 + 5 bits or code 285, so we
* overwrite length_code[255] to use the best encoding:
* 刚好有一个剩下的code,分配给length 255(+ 3 = 258)
*/
length_code[length-1] = (uch)code;
/* Initialize the mapping dist (0..32K) -> dist code (0..29)
* 初始化映射 所有0 ~ 32k(16bit)distance值 -> 30个区间码,
* 详情见该函数源码下方注2。
*/
dist = 0;
//此处的循环与前面length数据处理方法类似。
for (code = 0 ; code < 16; code++) {
base_dist[code] = dist;
for (n = 0; n < (1<<extra_dbits[code]); n++) {
dist_code[dist++] = (uch)code;
}
}
Assert (dist == 256, "ct_init: dist != 256");
//此处的处理很微妙,见下方注2。
dist >>= 7; /* from now on, all distances are divided by 128 */
for ( ; code < D_CODES; code++) {
base_dist[code] = dist << 7;
for (n = 0; n < (1<<(extra_dbits[code]-7)); n++) {
dist_code[256 + dist++] = (uch)code;
}
}
Assert (dist == 256, "ct_init: 256+dist != 512");
//初始化静态literal树中各值对应编码的长度,
//静态意为所有literal字符值都给出默认的编码
/* Construct the codes of the static literal tree */
for (bits = 0; bits <= MAX_BITS; bits++) bl_count[bits] = 0;
n = 0;
while (n <= 143) static_ltree[n++].Len = 8, bl_count[8]++;
while (n <= 255) static_ltree[n++].Len = 9, bl_count[9]++;
while (n <= 279) static_ltree[n++].Len = 7, bl_count[7]++;
while (n <= 287) static_ltree[n++].Len = 8, bl_count[8]++;
/* Codes 286 and 287 do not exist, but we must include them in the
* tree construction to get a canonical Huffman tree (longest code
* all ones)
*/
//调用gen_codes为已经分配好长度的静态literal树生成编码,
//gen_codes是一个重要函数,看懂就能理解为什么这里只需记录编码长度的分布
//而不需记录所有的编码值了。详情见后面对gen_codes的专门分析。
gen_codes((ct_data near *)static_ltree, L_CODES+1);
/* 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









