







原文地址:http://xccds.github.io/2011/09/caret_24.html/
在进行数据挖掘时,我们并不需要将所有的自变量用来建模,而是从中选择若干最重要的变量,这称为特征选择(feature selection)。一种算法就是后向选择,即先将所有的变量都包括在模型中,然后计算其效能(如误差、预测精度)和变量重要排序,然后保留最重要的若干变量,再次计算效能,这样反复迭代,找出合适的自变量数目。这种算法的一个缺点在于可能会存在过度拟合,所以需要在此算法外再套上一个样本划分的循环。在caret包中的rfe命令可以完成这项任务。
首先定义几个整数,程序必须测试这些数目的自变量.
subsets = c(20,30,40,50,60,70,80)然后定义控制参数,functions是确定用什么样的模型进行自变量排序,本例选择的模型是随机森林即rfFuncs,可以选择的还有lmFuncs(线性回归),nbFuncs(朴素贝叶斯),treebagFuncs(装袋决策树),caretFuncs(自定义的训练模型)。
method是确定用什么样的抽样方法,本例使用cv即交叉检验, 还有提升boot以及留一交叉检验LOOCV
ctrl= rfeControl(functions = rfFuncs, method = "cv",verbose = FALSE, returnResamp = "final")最后使用rfe命令进行特征选择,计算量很大,这得花点时间
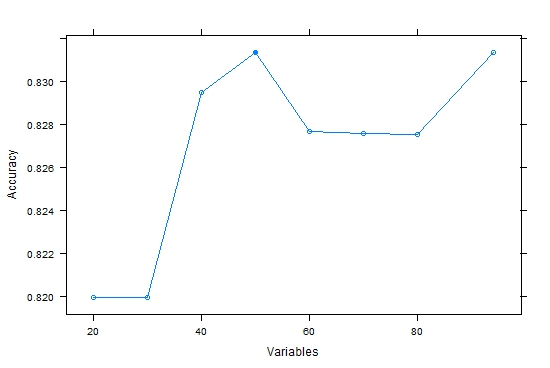
Profile = rfe(newdata3, mdrrClass, sizes = subsets, rfeControl = ctrl)观察结果选择50个自变量时,其预测精度最高
print(Profile)
Variables Accuracy Kappa AccuracySD KappaSD Selected
用图形也可以观察到同样结果20 0.8200 0.6285 0.04072 0.08550
30 0.8200 0.6294 0.04868 0.10102
40 0.8295 0.6487 0.03608 0.07359
50 0.8313 0.6526 0.04257 0.08744 *
60 0.8277 0.6447 0.03477 0.07199
70 0.8276 0.6449 0.04074 0.08353
80 0.8275 0.6449 0.03991 0.08173
94 0.8313 0.6529 0.03899 0.08006
plot(Profile)
下面的命令则可以返回最终保留的自变量
Profile$optVariables















 2907
2907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









