







[Hadoop] 实际应用场景之 - 阿里
Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处理,例如对日志的分析,也涉及内容部分,结构化数据等。使用Hadoop主要基于可扩展性的考虑,规模从当初的3-4百节点增长到今天单一集群3000节点以上,2-3个集群,支付宝的集群规模也达700台,使用Hbase,个人消费记录,key-value型。
阿里对Hadoop的源码做了如下修改:
- 改进Namenode单点问题
- 增加安全性
- 改善Hbase的稳定性
- 改进反哺Hadoop社区
阿里数据处理的整体架构图如下:

架构分为五层,分别是数据源、计算层、存储层、查询层和产品层。
- 数据源:这里有淘宝主站的用户、店铺、商品和交易等数据库,还有用户的浏览、搜索等行为日志等。这一系列的数据是数据产品最原始的生命力所在。
- 计算层:在数据源层实时产生的数据,通过淘宝主研发的数据传输组件DataX、DbSync和Timetunnel准实时地传输到Hadoop集群“云梯”,是计算层的主要组成部分。在“云梯”上,每天有大约40000个作业对1.5PB的原始数据按照产品需求进行不同的MapReduce计算。一些对实效性要求很高的数据采用“云梯”来计算效率比较低,为此做了流式数据的实时计算平台,称之为“银河”。“银河”也是一个分布式系统,它接收来自TimeTunnel的实时消息,在内存中做实时计算,并把计算结果在尽可能短的时间内刷新到NoSQL存储设备中,供前端产品调用。
- 存储层:针对前端产品设计了专门的存储层。在这一层,有基于MySQL的分布式关系型数据库集群MyFOX和基于HBase的NoSQL存储集群Prom。
MyFOX的结构图如下:

Prom(即普罗米修斯)结构图如下:

- 查询层(glider)
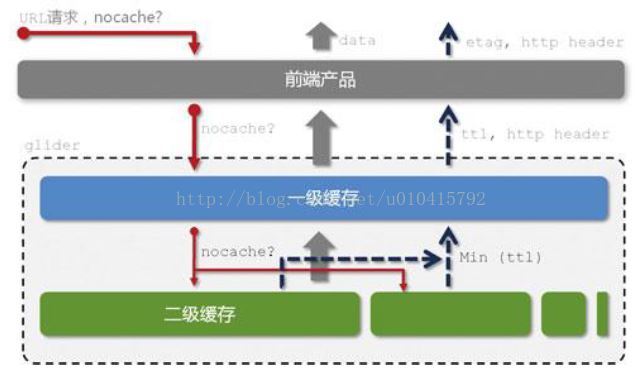
- 产品层:数据魔方、量子恒道等
[Hadoop] 实际应用场景之 - 百度
百度在2008年就开始使用Hadoop作为其离线数据分析平台,从Hadoop v0.18/0.19开始,300台机器,2个集群,现在的规模为2W台节点以上,最大集群接近4,000节点,每日处理数据20PB+,每日作业数120,000+
Hadoop在百度主要用于如下场景:
- 日志的存储和统计;
- 网页数据的分析和挖掘;
- 商业分析,如用户的行为和广告关注度等;
- 在线数据的反馈,及时得到在线广告的点击情况;
- 用户网页的聚类,分析用户的推荐度及用户之间的关联度。

百度和其它公司对Hadoop的应用最大的不同是对源代码做了大量的修改,当Hadoop 2.0官方版本还没有出来时,百度就已经在开发自己的Hadoop 2.0,如下图所示:

HDFS 1.0面临的问题有:
- 集群规模大,Namenode响应变慢
- Namenode单点,切换时间太长
- 没有数据压缩
- Namespace过于耗用资源
百度自己开发的HDFS 2.0改进了如下功能:
- Namenade热备切换
- 分钟级别切换
- 最坏情况,可能丢失1分钟数据
- 透明数据压缩(利用CPU低谷时压缩、长时间未使用的块才压缩等)
MapReduce 1.0面临的问题有:
- JobTracker单点问题
- 资源粒度过粗(slot)
- 资源利用率不高
百度自己开发的MapReduce 2.0改进了如下功能:
- 可扩展性强(支持万台节点以上)
- 架构松耦合,支持多种计算框架
- 可支持热升级
- 更精细的资源控制
- MR优化:Shuffle独立/Task同质调度















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









