









论文题目:Curriculum Learning
论文地址:http://dl.acm.org/citation.cfm?id=1553380
论文发表于:ICML 2009(A类会议)
论文大体内容:
本文考虑到人的学习,学的是经过组织的知识,才能学习得更快。那么对应到机器学习,是否能够通过改变学习的顺序(对知识进行简单的组织),提升机器学习的效果呢?本文经过实验,发现这确实是一个可行的思路,改变学习的顺序,能对学习的速度和质量进行提升。
1、人类的学习策略——先易后难是一个有效并且高效的学习策略,那么机器学习是否能够使用这一策略,达到同样的效果呢?这就是本文要探索的。
2、深层神经网络有一个局限,就是很多时候会陷入一个局部最小值而不能自拔,而本文提出的curriculum learning的方法,能够帮助找到更好的局部最小值,以提升结果。后面通过实验能够验证这一说法。
3、深层神经网络的layer结构,其实有点类比于我们人类的学习过程的,比如第一层先进行简单抽象(学习出简单的东西),随着层数的增加,抽象慢慢加深,其实就是学习的东西慢慢变难了,与本文的curriculum learning观点是契合的。
4、Definition of Curriculum
样本z的分布概率是P(z),权重是W(z),那么在某个step λ(λ范围为[0, 1]),对应的实际值为:

同时,随着step增加(样本数也增加),需要满足:
①熵递增,以增加训练样本的多样性;
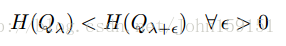
②权重递增,以提升样本在训练集的作用,从而增加样本数量;

5、本文的“从易到难”策略,避不开的一个关键问题是,到底什么样例才是easy的呢?这个得具体问题具体分析,所以本文做了3个实验来验证这一设想。
6、在supervised learning中,noisy的样本是那些分类错了的样本,比如linear SVM中,分错了方向的样本自然可以认为是noisy的样本。所以本文认为,不noisy的就是easy的。作者也发现,仅使用easy的样本训练linear SVM模型,相比使用easy+noisy样本能得到更好的结果(16.3%的错误率 VS 17.1%的错误率)。
在linear SVM中,作者使用了2种方法,对“从易到难”策略进行验证:
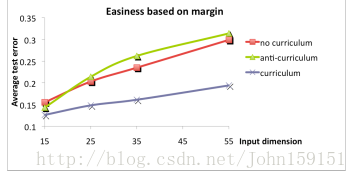
①输入的样本有irrelevant(noisy)的,通过随机去掉irrelevant样本的数量,从而能够调整样本的训练难度,最简单(去掉所有irrelevant的) -> 最困难(保留所有irrelevant的);
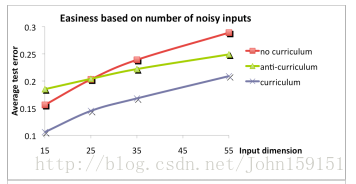
②另一种方法是根据yw’x的大小(y=sign(w’x))来进行排序easy程度,因为y=sign(w’x),所以yw’x越大,说明越准确,也代表了越easy。
7、形状分类实验
本实验使用了2个数据集,BasicShapes(包含3类图形,有正方形、圆形、等边三角形)和GeomShapes(包含3类图形,有矩形、椭圆形、普通三角形,可看作BasicShapes的进阶版)。使用了包含3个hidden layer的神经网络,训练的策略是这样的:
①使用随机生成的10000个BasicShapes样本作训练;
②重复①epoch次;
③使用10000个GeomShapes样本作训练;
最后在GeomShapes的测试数据集上作评测。实验结果表明,随着epoch次数的上升,误差会越来越低,说明先使用很多easy的样本去训练,最后再学习难的,效果会更好。
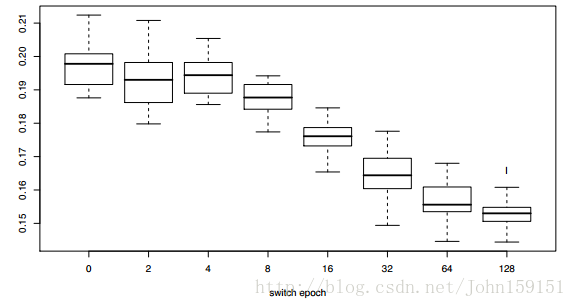
但是这样有一些质疑的声音认为,相比于epoch=0的baseline,其它epoch大的情况下,学习器是因为看到了更多的训练数据,才学到了更好的结果。所以作者又做了2个尝试,①将2个dataset联合一起训练;②仅训练简单的dataset。但发现结果都不好。
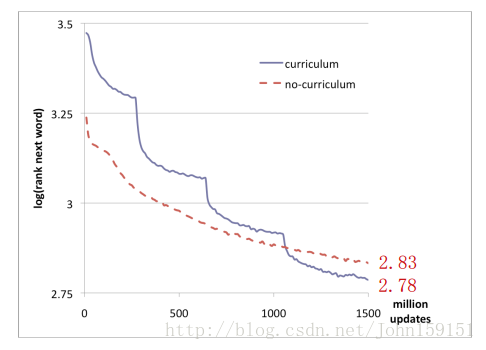
8、语言模型实验——预测句子的下一个词语
本实验使用了别人的一个语言模型结构f(s),用于计算句子s的分数(分数取值为[0, 1]),分数越高,代表该句子越通顺,越正确。句子text窗口选择5,使用了包含631 million的wiki语料,根据句子中的词语是不是常见词来判断样本的难易程度。词典每次增加5000个最常用的words,只要文档中有一个词不在词典中,那么就过滤掉这个文档,从而能够不断增加训练集的文档数。使用的loss function是:
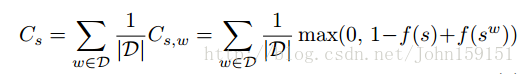
其含义是:假如s是一个好句子,那么f(s)的得分就高(接近1),而f(s^w)(s^w代表用词典中的其它词语代替掉s句子中最后的一个词语,所生成的句子)得分就相对低,所以Cs接近0,比较低;而假如s是一个坏句子,那么f(s)的得分就低,导致Cs接近1,比较高。
最后的实验结果发现使用curriculum策略确实能减少错误率。
9、思考:
机器学习,就是要让机器模拟人类去进行学习。而我们人类接受的教育,都是经过高度组织、编排的,正是这样,才使得我们更好、更快的去学到知识。而对于机器来说,一般我们会直接把一堆杂乱的数据扔给它,让它根据相应的算法,自己探索里面存在的知识。而本文考虑的问题,就是不能把数据直接扔给机器,需要先对数据进行组织(组织这步当然可以让机器自己组织),从易到难,不断扩充自己的知识,从而实现类人的学习,以达到更好、更快的效果。这个想法结合Lifelong Machine Learning也是不错的,2013 AAAI中已经有学者完成了相关的工作,详见[1]。
参考资料:
[1]、http://blog.csdn.net/john159151/article/details/54176637
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!














 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









