






转载请注明作者和出处:http://blog.csdn.net/john_bh/
运行平台: Windows
Python版本: Python3.6
IDE: Sublime text3
一、 概述
朴素贝叶斯(naive Bayes)法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合概率分布;然后基于此模型,对给定的额输入x,利用贝叶斯定理求出后验概率最大的输出y,朴素贝叶斯法实现简单,学习与预测的效率很高,是一种常用的方法。
朴素贝叶斯的一般过程:
- 收集数据:可以使用任何方法,这里使用RSS源;
- 准备数据:需要数值型或者布尔型数据;
- 分析数据:有大量特征时,绘制特征作用不大,此时使用直方图效果更好;
- 训练算法:计算不同的独立特征的条件概率;
- 测试算法:计算错误率;
- 使用算法:一个常见的朴素贝叶斯应用是文档分类。可以在任意的分类场景中使用朴素贝叶斯分类器,不一定非要是文本。
二 、基于贝叶斯决策理论的分类方法
假设现在我们有一个数据集,它由两类数据组成,数据分布如下图1所示:
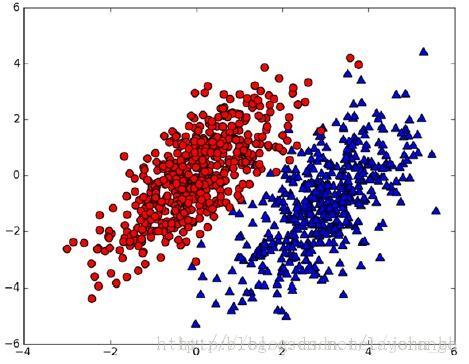
图1
我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中红色圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
- 如果p1(x,y) > p2(x,y),那么类别为1
- 如果p1(x,y) < p2(x,y),那么类别为2
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。那么接下来,就是学习如何计算p1和p2概率。
2.1 条件概率
条件概率(Condittional probability),就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。
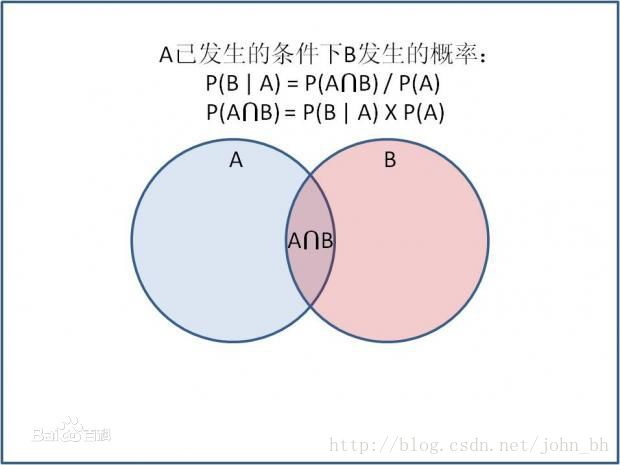
图2
同理可得, P(A∩B)=P(A|B)P(B) P ( A ∩ B ) = P ( A | B ) P ( B ) ;所以, P(A|B)P(B)=P(B|A)P(A) P ( A | B ) P ( B ) = P ( B | A ) P ( A ) 。
即:
2.2 全概率公式
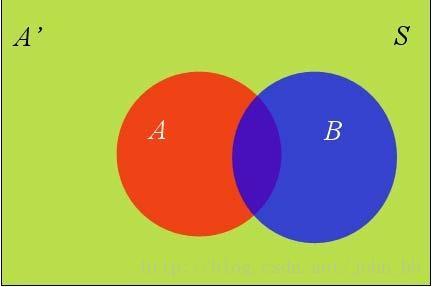
图3
由图可知: P(B)=P(B∩A)+P(B∩A′) P ( B ) = P ( B ∩ A ) + P ( B ∩ A ′ )
由上一节的推导可知: P(B∩A)=P(B|A)P(A) P ( B ∩ A ) = P ( B | A ) P ( A )
所以: P(B)=P(B|A)P(A)+P(B|A′)P(A′) P ( B ) = P ( B | A ) P ( A ) + P ( B | A ′ ) P ( A ′ )
它的含义是,如果A和A’构成样本空间的一个划分,那么事件B的概率,就等于A和A’的概率分别乘以B对这两个事件的条件概率之和。
将这个公式代入上一节的条件概率公式,就得到了条件概率的另一种写法:
2.3 贝叶斯推断
对条件概率公式进行变形,可以得到如下形式:
我们把P(A)称为” 先验概率”(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为” 后验概率”(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为” 可能性函数”(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成下面的式子:后验概率 = 先验概率 x 调整因子
我们先预估一个”先验概率”,然后加入实验结果,看这个实验到底是增强还是削弱了”先验概率”,由此得到更接近事实的”后验概率”。如果”可能性函数”P(B|A)/P(B)>1,意味着”先验概率”被增强,事件A的发生的可能性变大;如果”可能性函数”=1,意味着B事件无助于判断事件A的可能性;如果”可能性函数”<1,意味着”先验概率”被削弱,事件A的可能性变小。
2.3.1 实例:水果糖问题
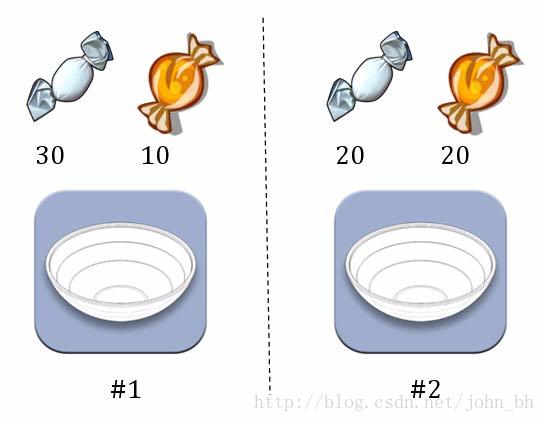
图4
两个一模一样的碗,一号碗有30颗水果糖和10颗巧克力糖,二号碗有水果糖和巧克力糖各20颗。现在随机选择一个碗,从中摸出一颗糖,发现是水果糖。请问这颗水果糖来自一号碗的概率有多大?
我们假定,H1表示一号碗,H2表示二号碗。由于这两个碗是一样的,所以P(H1)=P(H2),也就是说,在取出水果糖之前,这两个碗被选中的概率相同。因此,P(H1)=0.5,我们把这个概率就叫做”先验概率”,即没有做实验之前,来自一号碗的概率是0.5。
再假定,E表示水果糖,所以问题就变成了在已知E的情况下,来自一号碗的概率有多大,即求P(H1|E)。我们把这个概率叫做”后验概率”,即在E事件发生之后,对P(H1)的修正。
根据条件概率公式,得到:
已知,P(H1)等于0.5,P(E|H1)为一号碗中取出水果糖的概率,等于30÷(30+10)=0.75,那么求出P(E)就可以得到答案。根据全概率公式:
将数字代入原方程,得到:
这表明,来自一号碗的概率是0.6。也就是说,取出水果糖之后,H1事件的可能性得到了增强。
2.4 朴素贝叶斯推断
贝叶斯和朴素贝叶斯的概念是不同的,区别就在于“朴素”二字,朴素贝叶斯对条件个概率分布做了条件独立性的假设。 比如下面的公式,假设有n个特征:
由于每个特征都是独立的,我们可以进一步拆分公式:
2.4.1 实例:病人分类
某个医院早上来了六个门诊的病人,他们的情况如下表所示:
| 症状 | 职业 | 疾病 |
|---|---|---|
| 打喷嚏 | 护士 | 感冒 |
| 打喷嚏 | 农夫 | 过敏 |
| 头痛 | 建筑工人 | 脑震荡 |
| 头痛 | 建筑工人 | 感冒 |
| 打喷嚏 | 教师 | 感冒 |
| 头痛 | 教师 | 脑震荡 |
现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大?
根据贝叶斯定理:
可得:
根据朴素贝叶斯条件独立性的假设可知,”打喷嚏”和”建筑工人”这两个特征是独立的,因此,上面的等式就变成了:
计算可得:
因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。
三、使用朴素贝叶斯进行文档分类
以在线社区留言为例。为了不影响社区的发展,我们要屏蔽侮辱性的言论,所以要构建一个快速过滤器,如果某条留言使用了负面或者侮辱性的语言,那么就将该留言标志为内容不当。过滤这类内容是一个很常见的需求。对此问题建立两个类型:侮辱类和非侮辱类,使用1和0分别表示。
3.1 准备数据:从文本中建词向量
我们把文本看成单词向量或者词条向量,也就是说将句子转换为向量。考虑出现所有文档中的单词,再决定将哪些单词纳入词汇表或者说所要的词汇集合,然后必须要将每一篇文档转换为词汇表上的向量。简单起见,我们先假设已经将本文切分完毕,存放到列表中,并对词汇向量进行分类标注。新建文件FilterMessage.py,编写代码如下:
# -*- coding: UTF-8 -*-
"""
函数说明:创建实验样本
Parameters:
无
Returns:
postingList - 词条切分后的文档集合
classVec - 类别标签向量
"""
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #类别标签向量,1代表侮辱性词汇,0代表费侮辱性词汇
return postingList,classVec
"""
函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表,使用python中的sets数据类型
Parameters:
dataSet - 整理的样本数据集
Returns:
vocabSet - 返回不重复的词条列表,也就是词汇表
"""
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) #创建两个集合的并集
return list(vocabSet)
"""
函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0
Parameters:
vocabList - createVocabList返回的列表
inputSet - 切分的词条列表
Returns:
returnVec - 文档向量,词集模型
"""
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) #创建一个和词汇表等长的向量,其中所含元素都为0
for word in inputSet: #遍历文档中的每个词条
if word in vocabList: #如果词条存在于词汇表中,则置1
returnVec[vocabList.index(word)] = 1
else: print("the word: %s is not in my Vocabulary!" % word)
return returnVec #返回文档向量
if __name__ == '__main__':
postingList, classVec = loadDataSet()
#for each in postingList:
#print(each)
#print(classVec)
print('postingList:\n',postingList)
myVocabList = createVocabList(postingList)
print('myVocabList:\n',myVocabList)
trainMat = []
for postinDoc in postingList:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
print('trainMat:\n', trainMat)
运行结果如下:
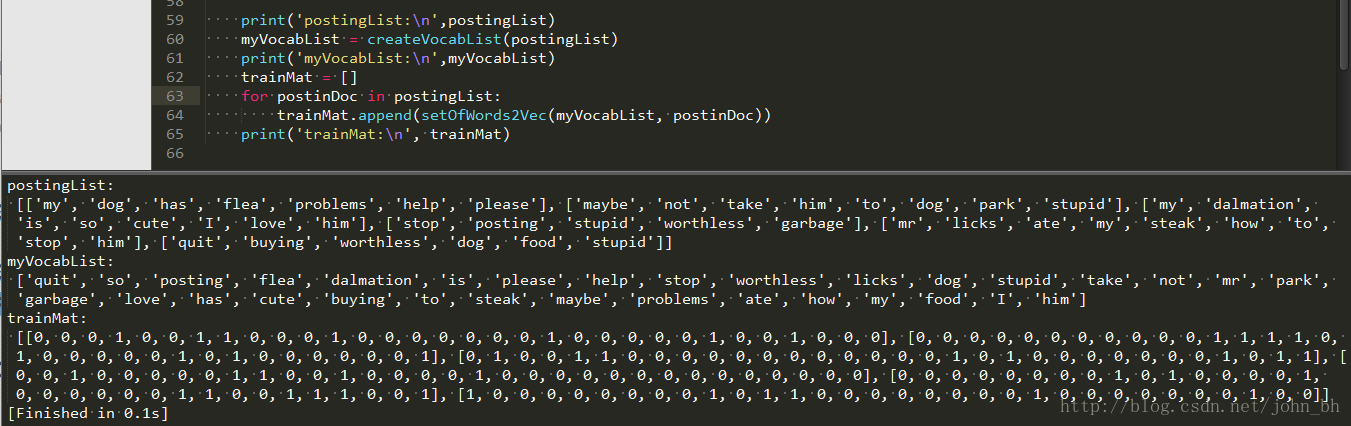
图5 运行结果
3.2 训练算法:从词向量计算概率
我们知道了如何将一组单词转化为一组数字,接下使用这些数字计算概率。已经知道了一个词是否出现在一篇文章中,也知道该文档所属的类别,那么使用贝叶斯计算概率,公式如下:其中
ww
w
w
表示一个向量,它由多个数值组成
利用上述公式,对每个类计算该值,然后比较两个概率值得大小。
计算步骤:
首先,可以通过类别i(侮辱性留言或非侮辱性留言)中文档数除以总的文档数来计算概率 p(ci) p ( c i ) ;
第二,计算 p(ww|ci) p ( w w | c i ) ,这里用到朴素贝叶斯假设,将展开作为一个独立的特征,可以将上述概率写作 p(w0,w1,...,wN|ci) p ( w 0 , w 1 , . . . , w N | c i ) ,假设所有词汇都是相互独立的,该假设成为条件独立假设,它意味着可以使用 p(w0|ci)p(w1|ci)...p(wN|ci) p ( w 0 | c i ) p ( w 1 | c i ) . . . p ( w N | c i ) 来计算上述概率,伪代码如下:
计算每个类别中的文档中数目
对每一篇训练文档:
对每个类别:
如果词条出现在文档中--->增加该词条的计数值
增加所有词条的计数值
对于每个类别:
对于每个词条:
将该词条的数目除以总词条数目的到条件概率
返回每个类别的条件概率
在文件FilterMessage.py中添加方法trainNB0()用于朴素贝叶斯分类器,代码实现:
"""
函数说明:朴素贝叶斯分类器训练函数
Parameters:
trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵
trainCategory - 训练类别标签向量,即loadDataSet返回的classVec
Returns:
p0Vect - 侮辱类的条件概率数组
p1Vect - 非侮辱类的条件概率数组
pAbusive - 文档属于侮辱类的概率
"""
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) #计算训练的文档数目
numWords = len(trainMatrix[0]) #计算每篇文档的词条数
pAbusive = sum(trainCategory)/float(numTrainDocs) #文档属于侮辱类的概率
p0Num = np.zeros(numWords); p1Num = np.zeros(numWords) #创建numpy.zeros数组,词条出现数初始化为0
p0Denom = 0.0; p1Denom = 0.0 #分母初始化为0
for i in range(numTrainDocs):
if trainCategory[i] == 1: #统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else: #统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom
p0Vect = p0Num/p0Denom
return p0Vect,p1Vect,pAbusive #返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率
if __name__ == '__main__':
postingList, classVec = loadDataSet()
#for each in postingList:
#print(each)
#print(classVec)
#print('postingList:\n',postingList)
myVocabList = createVocabList(postingList)
#print('myVocabList:\n',myVocabList)
trainMat = []
for postinDoc in postingList:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
print('trainMat:\n', trainMat)
p0V, p1V, pAb = trainNB0(trainMat, classVec)
print('p0V:\n', p0V)
print('p1V:\n', p1V)
print('classVec:\n', classVec)
print('pAb:\n', pAb)p0V是非侮辱类词汇的概率,例如p0V的第5个概率,就是stupid这个单词属于非侮辱类的概率为0。p1V是侮辱类词汇的概率,例如p1V的第5个概率,就是stupid这个单词属于侮辱类的概率为0.15789474,约等于15.79%的概率。pAb是所有侮辱类的样本占所有样本的概率,从classVec中可以看出,一用有3个侮辱类,3个非侮辱类。所以侮辱类的概率是0.5。因此p0V存放的就是P(my|非侮辱类) = 0.125、P(I|非侮辱类) = 0.04166667,一直到P(love|非侮辱类) = 0.04166667。同理,p1V存放的就是各个单词属于侮辱类的条件概率。pAb就是先验概率。运行结果如下:
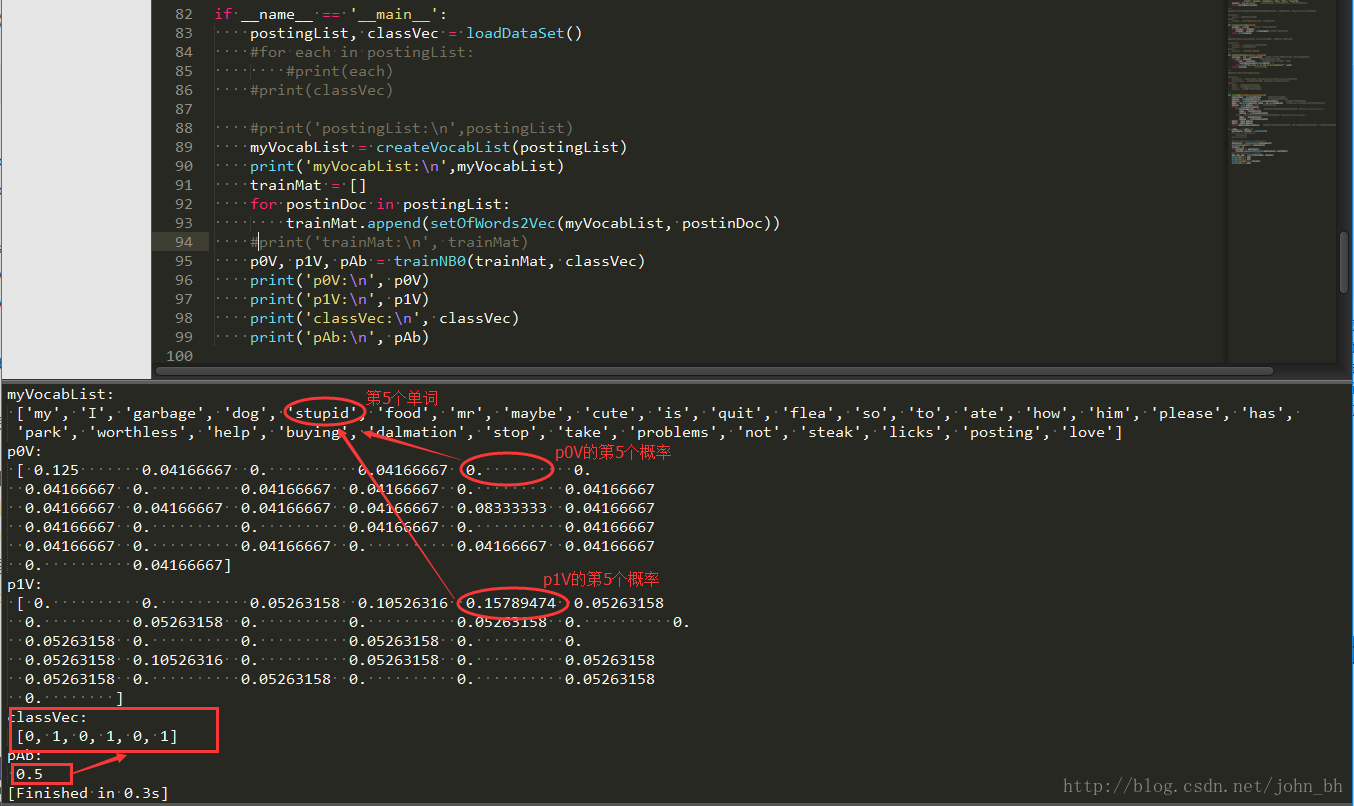
图6 运行结果
3.3 测试算法:根据现实情况修改分类器
3.3.1 朴素贝叶斯改进之拉普拉斯平滑
利用贝叶斯分类器对文档进行分类时,需要计算多个概率的乘积已获得文档属于某个类别的概率,即计算 p(w0|1)p(w1|1)p(w2|1) p ( w 0 | 1 ) p ( w 1 | 1 ) p ( w 2 | 1 ) ,如果其中的一个概率为零,那么最后的乘积也为零,为了降低这种影响,可以将所有词的出现数初始化为1,并将分母初始化为2。这种做法就叫做拉普拉斯平滑(Laplace Smoothing)又被称为加1平滑,是比较常用的平滑方法,它就是为了解决0概率问题。
修改函数trainNB0()第4,5行的代码:
p0Num = np.ones(numWords); p1Num = np.ones(numWords) #创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑
p0Denom = 2.0; p1Denom = 2.0 #分母初始化为2,拉普拉斯平滑另外一个问题是下溢出,这是有太多很像的数相乘造成的,当计算
p(w0|ci)p(w1|ci)p(w2|ci)...p(wN|ci)
p
(
w
0
|
c
i
)
p
(
w
1
|
c
i
)
p
(
w
2
|
c
i
)
.
.
.
p
(
w
N
|
c
i
)
乘积时,由于大部分因子都非常小,所以程序会下溢出或者得不到正确答案,一种解决办法是对乘积取自然对数,在代数中有
ln(a∗b)=ln(a)+ln(b)
ln
(
a
∗
b
)
=
ln
(
a
)
+
ln
(
b
)
,于是可以通过求对数避免下溢出或者浮点数舍入导致的错误;同时采用自然对数进行处理不会有任何的损失。图7 给出函数否
f(x)
f
(
x
)
和函数
ln(f(x))
ln
(
f
(
x
)
)
的曲线。检查这两条曲线,就会发现它们在相同区域内同时增加或者减少,并且在相同点上取到极值。它们的取值虽然不同,但不影响最终结果。
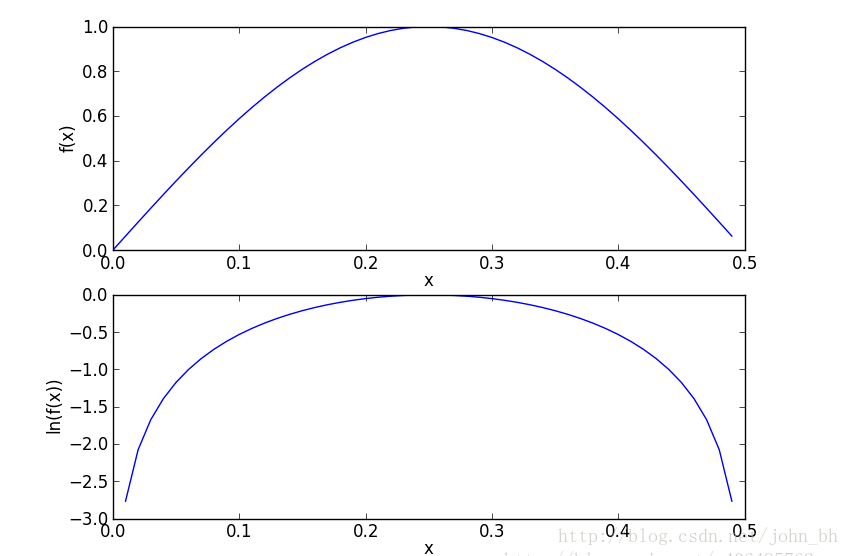
图7 函数否 f(x) f ( x ) 和函数 ln(f(x)) ln ( f ( x ) ) 的曲线
修改函数trainNB0()的返回值为:
p1Vect = np.log( p1Num/p1Denom )#取对数,防止下溢出
p0Vect = np.log( p0Num/p0Denom )接下来,使用分类器进行分类。分类函数classifyNB(),测试函数testingNB(),具体代码如下:
"""
函数说明:朴素贝叶斯分类器分类函数
Parameters:
vec2Classify - 待分类的词条数组
p0Vec - 侮辱类的条件概率数组
p1Vec -非侮辱类的条件概率数组
pClass1 - 文档属于侮辱类的概率
Returns:
0 - 属于非侮辱类
1 - 属于侮辱类
"""
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
#p1 = reduce(lambda x,y:x*y, vec2Classify * p1Vec) * pClass1 #对应元素相乘
#p0 = reduce(lambda x,y:x*y, vec2Classify * p0Vec) * (1.0 - pClass1)
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #对应元素相乘。logA * B = logA + logB,所以这里加上log(pClass1)
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
"""
函数说明:测试朴素贝叶斯分类器
Parameters:
无
Returns:
无
"""
def testingNB():
listOPosts,listClasses = loadDataSet() #创建实验样本
myVocabList = createVocabList(listOPosts) #创建词汇表
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) #将实验样本向量化
p0V,p1V,pAb = trainNB0(np.array(trainMat),np.array(listClasses)) #训练朴素贝叶斯分类器
testEntry = ['love', 'my', 'dalmation'] #测试样本1
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) #测试样本向量化
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'属于侮辱类') #执行分类并打印分类结果
else:
print(testEntry,'属于非侮辱类') #执行分类并打印分类结果
testEntry = ['stupid', 'garbage'] #测试样本2
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) #测试样本向量化
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'属于侮辱类') #执行分类并打印分类结果
else:
print(testEntry,'属于非侮辱类') #执行分类并打印分类结果
运行结果如下:
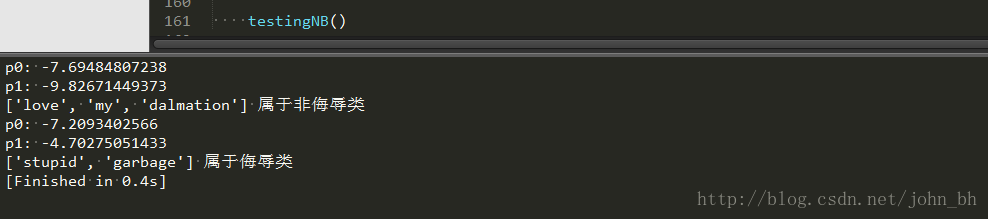
图8 运行结果
3.4 准备数据:文档袋模型
3.4.1 词袋模型的简介
我们将每个词的出现与否作为一个特征,这可以描述为词集模型(set-of-words model)。如果一个词在一个文档中出现不止一次,这可能意味着包含该词是否出现在文档中所不能表达的某种信息,这种方法称为词袋模型(bag-of-words model),在词袋中,每个单词可以出现多次,而在词集中,每个词中能出现一次,为了适应词袋模型,需要对函数setOfWords2Vec()稍加修改,修改后的函数为bagOfwords2Vec().
下面给出基于词袋模型的朴素贝叶斯代码,他与函数setOfWords2Vec()几乎完全相同,唯一不同的是每当遇到一个单词时,它会增加词向量中的对应值,而不只是将对应数值设为1。
def bagOfWords2Vec(vocabList,inputSet):
returnVec=[0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)]+=1
return returnVecBag-of-words模型是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。例如有如下两个文档:
- Bob likes to play basketball, Jim likes too.
- Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
- [1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
- [1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数(下文中,将用单词的直方图表示)。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序(这是本Bag-of-words模型的缺点之一,不过瑕不掩瑜甚至在此处无关紧要)。
3.4.2 词袋模型的应用
现在想象在一个巨大的文档集合D,里面一共有M个文档,而文档里面的所有单词提取出来后,一起构成一个包含N个单词的词典,利用Bag-of-words模型,每个文档都可以被表示成为一个N维向量,计算机非常擅长于处理数值向量。这样,就可以利用计算机来完成海量文档的分类过程。
考虑将Bag-of-words模型应用于图像表示。为了表示一幅图像,我们可以将图像看作文档,即若干个“视觉词汇”的集合,同样的,视觉词汇相互之间没有顺序。
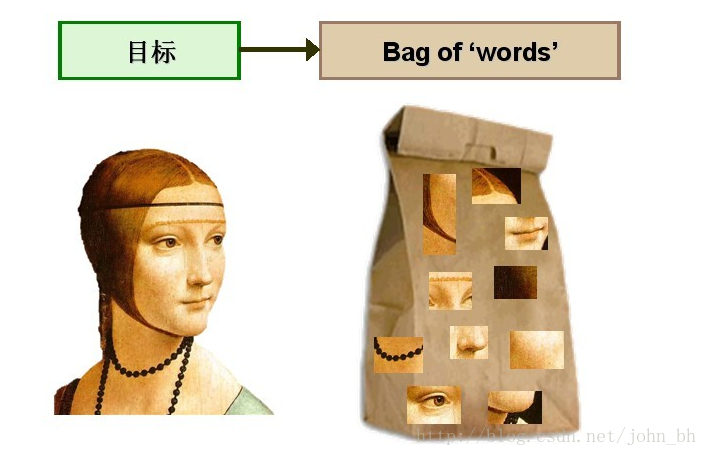
图9 将Bag-of-words模型应用于图像表示
由于图像中的词汇不像文本文档中的那样是现成的,我们需要首先从图像中提取出相互独立的视觉词汇,这通常需要经过三个步骤:(1)特征检测,(2)特征表示,(3)单词本的生成,请看下图10:

图10 从图像中提取出相互独立的视觉词汇
通过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛,嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
而SIFT算法是提取图像中局部不变特征的应用最广泛的算法,因此我们可以用SIFT算法从图像中提取不变特征点,作为视觉词汇,并构造单词表,用单词表中的单词表示一幅图像。
Bag-of-words模型应用三步:
接下来,我们通过上述图像展示如何通过Bag-of-words模型,将图像表示成数值向量。现在有三个目标类,分别是人脸、自行车和吉他。
Bag-of-words模型的第一步是利用SIFT算法,从每类图像中提取视觉词汇,将所有的视觉词汇集合在一起,如下图11所示:

图11 从每类图像中提取视觉词汇
第二步是利用K-Means算法构造单词表。K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。SIFT提取的视觉词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近的词汇合并,作为单词表中的基础词汇,假定我们将K设为4,那么单词表的构造过程如下图12所示:
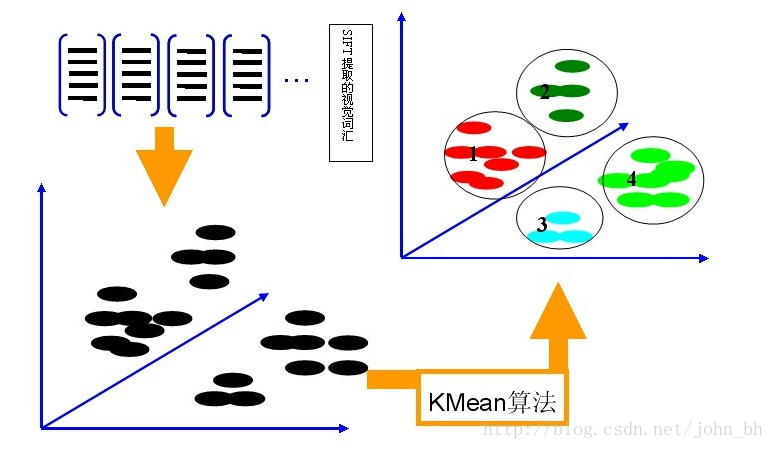
图12 利用K-Means算法构造单词表
第三步是利用单词表的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。请看下图13:
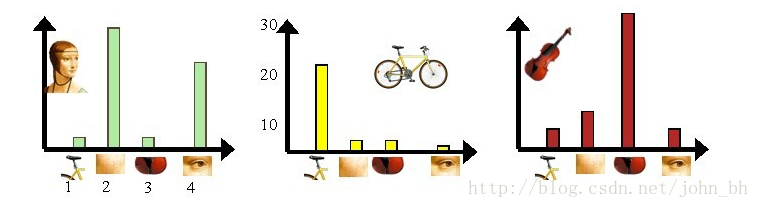
图13 每幅图像的直方图表示
上图中,我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇表中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉单词,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示(我们假定存在误差,实际情况亦不外如此):
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个词典,词典中包含4个视觉单词,即Dictionary = {1:”自行车”, 2. “人脸”, 3. “吉他”, 4. “人脸类”},最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数画成了上面对应的直方图。
需要说明的是,以上过程只是针对三个目标类非常简单的一个示例,实际应用中,为了达到较好的效果,单词表中的词汇数量K往往非常庞大,并且目标类数目越多,对应的K值也越大,一般情况下,K的取值在几百到上千,在这里取K=4仅仅是为了方便说明。















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









