







集成算法:
将多个分类器集成起来而形成的新的分类算法。这类算法又称元算法(meta-algorithm)。最常见的集成思想有两种bagging和boosting。
集成思想 :
-
boosting:重赋权(re-weighting)
--基于错误提升分类器性能,通过集中关注被已有分类器分类错误的样本,构建新分类器并集成。
boosting的思想是 : 训练集(其中各个元素)的权重是根据学习器的表现来改变的.
bagging采用自助采样的方式”产生”出多个训练集.但是boosting只有一个训练集,但是训练集中各个元素(输入向量)的权重是不同的.boosting是先从具有初始权重的训练集训练出一个弱学习器1,然后根据弱学习器1的表现,来更新样本的权重. 然后再具有新的权重的训练集上面训练弱学习器2,然后根据弱学习器2的表现来更新样本的权重……..反复多次 ,得到m个学习器,最后整合这些弱学习器得到强学习器. 比较出名的就是Adaboost算法。
-
bagging:bootstrap sampling(有放回地取样)
--基于数据随机重抽样的分类器构建方法。
bagging的思想 : 通过自助采样的方法得到K个训练集,然后分别在这K个训练集上面训练学习器.然后就得到了K个学习器.
bootstrap : 不依靠外界的帮助,或者叫做自助法. 在这里表示一种有放回的抽样方法. bootstrap sampling : 自助采样,对于N个样本的训练集,我从里面随机取出m个样本,得到一个子训练集.然后把这些样本放回. 然后再取m个样本,得到第二个子训练集,再放回去………..重复这样的步骤k次,得到k个子训练集. Bagging可以看做是bootstrap aggregation的简写.

bagging对于弱学习器没有限制,也就是说,你可以用决策树,SVM等等都是可以的.一般常用的是决策树和神经网络. 因为bagging的随机采样思路,模型的泛化能力很强,降低了模型的方差.但是对于训练集的拟合程度就不是那么好,也就是说偏差会大一些. 符合bagging思想的比较出名的学习算法就是随机森林.
主要方法:
1、强可学习和弱可学习
2、在验证集上找表现最好的模型
3、多个模型投票或者取平均值
- 分类问题:采用投票的方法,得票最多的类别为最终的类别
- 回归问题:采用简单的平均方法
4、对多个模型的预测结果做加权平均
- 分类问题:有权重的投票方式
- 回归问题:加权平均
算法示例:
-
随机森林(Random Forest: bagging + 决策树):
将训练集按照横(随机抽样本)、列(随机抽特征)进行有放回的随机抽取,获得n个新的训练集,训练出n个决策树,通过这n个树投票决定分类结果。主要的parameters 有n_estimators 和 max_features。
-
Adaboost (adaptive boosting: boosting + 单层决策树):
训练数据中的每个样本,并赋予其一个权重,这些权重构成了向量D。一开始,这些权重都初始化成相等值。首先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在统一数据集上再训练分类器。在第二次训练中,会调高那些前一个分类器分类错误的样本的权重。如此反复,训练出许多分类器来进行加权投票,每个分类器的权重是基于该分类器的错误率计算出来的。
-
GBDT (Gradient Boosting Decision Tree: boosting + 决策树):
GBDT与Adaboost类似,反复训练出多个决策树,每次更新训练集的权重是按照损失函数负梯度的方向。n_estimators是弱分类器个数;max_depth或max_leaf_nodes可以用来控制每棵树的规模;learning_rate是hyper-parameter,取值范围为(0, 1.0],用来控制过拟合与欠拟合
(1)从偏差-方差分解的角度看,Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;而Bagging主要关注降低方差,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效用更加明显;
(2)Bagging的训练集的选择是随机的,各轮训练集之间相互独立,而Boosting的各轮训练集的选择与前面各轮的学习结果有关,即Bagging采用均匀取样,而Boosting根据错误率来取样,因此Boosting的分类精度要优于Bagging;
(3)Bagging的各个预测函数没有权重,而Boosting是有权重的;
(4)Bagging的各个预测函数可以并行生成,而Boosting的各个预测函数只能顺序生成;
(5)对于像神经网络这样极为耗时的学习方法,Bagging可通过并行训练节省大量时间开销;
(6)bagging和boosting都可以有效地提高分类的准确性。在大多数数据集中,boosting的准确性比bagging高。但在有些数据集中,boosting会导致Overfit。
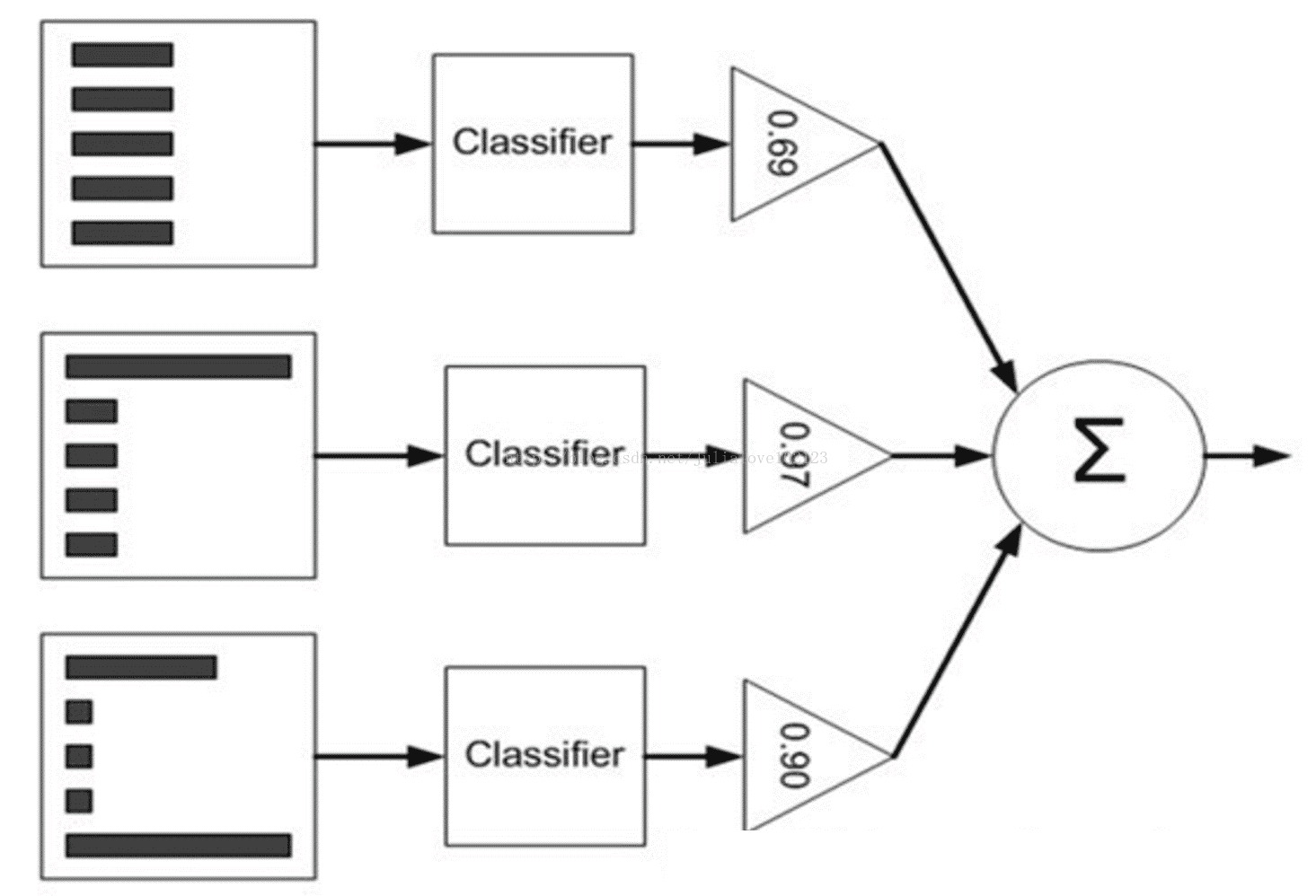
补充结合策略 :
假设集成包含T个基学习器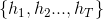
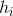
一.平均法
对于数值型输出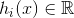
(1)Simple averaging(简单平均法)
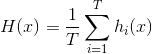
(2)Weighted averaging(加权平均法)
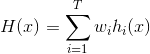
其中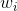
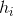
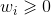
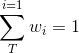
注意:
加权平均法的权重一般是从训练数据中学习而得,现实任务中的训练样本通常不充分或存在噪声,这将是的学习出的权重不完全可靠。尤其是对规模比较大的集成来说,要学习的权重比较多,容易导致过拟合。因此实验和应用均显示出,加权平均法未必一定优于简单平均法。一般而言,在个体学习器性能相差较大时适合使用加权平均法,而在个体学习器性能相近时适合使用简单平均法。
二.投票法
对分类任务来说,学习器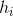
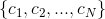
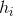
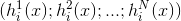
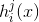
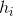
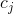
(1)Majority voting(绝对多数投票法)
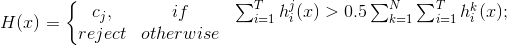
即若某标记得票过半数,则预测为该标记,否则拒绝预测。
(2)Plurality voting(相对多数投票法)
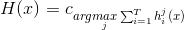
即预测为得票最多的标记,若同时有多个标记获得最高票,则从中随机选取一个。
(3)Weighted voting(加权投票法)
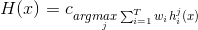
与加权平均法类似,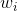
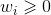
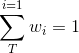
三.学习法
当训练数据很多时,一种更为强大的结合策略是使用“学习法”,即通过另一个学习器来进行结合。Stacking是学习法的典型代表。
Stacking先从初始数据集训练出初级学习器,然后“生成”一个新的数据集用于训练次级学习器。在这个新的数据集中,初级学习器的输出被当作样例输入特征,而初级样本的标记仍被当作样例标记。我们假定初级学习器使用不同的学习算法产生,即初级集成是异质的,具体过程如下:
(1)划分训练数据集为两个不相交的集合;
(2)在第一个集合上训练多个学习器;
(3)在第二个集合上测试这几个学习器;
(4)把第三步得到的预测结果作为输入,把正确的回应作为输出,训练一个高层学习器。
注意:
在训练阶段,次级训练集是利用初级学习器产生的。若直接用初级学习器的训练集来产生次级训练集,则过拟合的风险会比较大。因此,一般是通过使用交叉验证或者留一法的方式,用训练初级学习器未使用的样本来产生次级学习器的训练样本。
















 1724
1724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











