







n目录
Bias and Variance
在开始前首先了解机器学习中的偏差和方差。在有监督学习中,模型的泛化误差主要来源于偏差和方差。
偏差指的是由训练数据集训练出的模型的所有输出的平均值和真实模型输出间的偏差。通常是对学习算法做了错误假设导致的。
方差指的是由训练数据集训练出的模型的所有输出的方差。通常是模型的复杂度过高所导致。

使用特定模型对一个测试样本进行预测,就像打靶一样。靶心(红点)是测试样本的真实值,测试样本的y(橙色点)是真实值加上噪音,特定模型重复多次训练会得到多个具体的模型,每一个具体模型对测试样本进行一次预测,就在靶上打出一个预测值(图上蓝色的点)。所有预测值的平均就是预测值的期望(较大的浅蓝色点),浅蓝色的圆圈表示预测值的离散程度,即预测值的方差。所以,特定模型的预测值 与 真实值 的误差的 期望值,分解为上面公式中的三个部分,对应到图上的三条橙色线段:预测值的偏差、预测值的方差、样本噪音。
来源于https://www.jianshu.com/p/8c7f033be58a,关于偏差和方差具体也可以参考此文。
Aggregation Models
Why Aggregation?
假如你现在想买股票,在两支股票中犹豫不决,想向你的朋友们请教买哪支。
第一种,从朋友们中选取一个你最信任,对股票预测能力最强的人,直接听取他的意见。这个做法对应的是validation思想,即选择犯错误最小的模型。这种方法是通过验证集来选择最佳模型,而不是训练集。
第二种,如果你的朋友们都是预测股票的好手,那你可以考虑所有人的意见,对所有结果进行投票,一人一票,最后选择出得票多的那支股票。这种对应的是uniformly思想。
第三种,如果每个朋友水平不一,那么再采取uniformly就不合适了,厉害的投票权重应当更大一些,差的权重该小一些。这种方法对应的是non-uniformly思想。
第四种,这种与第三种类似,但是权重是不固定的,是根据条件而变化的,比如如果这个股票是互联网公司的,那么互联网方面厉害的朋友就要高权重。
上述四方法都是将不同人的意见融合起来,Aggregation的思想也是如此,即把多个hypothesis结合起来,得到更好的预测效果。我们接着再看一个简单的例子来理解下为什么aggregation能表现得更好。
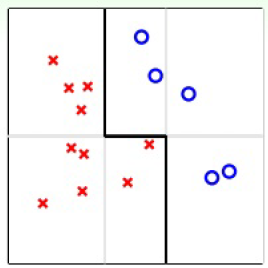
如上所示,进行一个二分类。如果要求只能用一条水平或垂直的直线进行分类,那不管怎么分都不能完全分开。这实际上就对应了刚才所说的validation的方法。这种方法不能利用集体智慧。但是,如果利用集体智慧,比如我们用一条横线和两条竖线,就能得到上图的折现从而将点完全分开。
这有点像之前的特征转换,将非线性数据转到高维空间就成了线性可分的。所以,aggregation是有特征转换的作用的。
再换个角度,
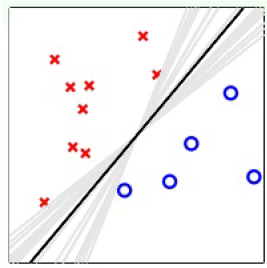
简单的PLA算法产生无数条能满足分类要求的直线,但是最好的应该是上图中最粗的那条,这很像SVM的目标。如果我们将所有的直线(hypothesis)结合起来,以投票的方式进行组合选择,得到的结果就是中间黑色那条。所以,aggregation也有正则化的作用。
所以aggregation就有两个优势:feature transform和regularization。而feature transform和regularization却是相互对立的,前者增大维度后者减小维度。通常来说一种模型只能倾向于其中一个,在两者间权衡,但是aggregation却能将两者的优势结合起来,从而得到不错的预测模型。
Aggregation Type

aggregation type有三种:uniform,non-uniform,conditional。有两种情况,一种是所有的hypothesis是已知的,即blending。对应的三种类型分别是voting/averaging,linear和stacking。另外一种情况是所有hypothesis未知,只能通过手上的资料重构hypothesis,即learning。其中uniform和non-uniform分别对应的是Bagging和AdaBoost算法,conditional对应的Decision Tree。
parallel methods:
Bagging,Random Forests
sequential methods:
AdaBoost
Blending and Bagging
Uniform Blending
在得到一些性能不错的hypothesis后,将它们进行整合,合并,来得到最佳的预测模型,这个过程叫blending(混合),首先介绍最常用的一种方法,uniformly blending。
for classification
应用于分类问题就是将每一个可能的hypothesis赋权重1,进行投票。这种方式又对应这三种不同情况:
1.每个hypothesis都相同,任选一个;
2.每个hypothesis都有区别,大多数是通过投票的方法,可以使多数修正少数意见,如前面说明aggregation有特征转换的例子的图。
3.针对多分类问题,选择得票数最多的一类。
for regression
uniform blending for regression分为两种情况:
1.每个hypothesis都相同,任选一个;
2.每个hypothesis都有区别,有的h>f,有的h<f(f是期望得到的目标函数),此时采用求平均值可以消去这种大于和小于的影响,从而得到更好的模型。从直观感受上来说,求平均使得模型更加稳定和准确。数学上也是可以证明计算不同h的平均值会比单一的h更加稳定。
结合前面所讲的偏差和方差,uniform blending求平均的过程,就减小了模型的方差,使得模型更加稳定。
Linear and Stacking
Linear
uniform blending中每个h权重为1,即求平均。在linear blending中,每个h权重不一。

确定α的值,方法是利用误差最小化的思想。这和linear regression很类似。

这种求解α的方法类似probabilistic SVM。采取两步计算:先计算g(t),再进行linear regression得到α值。所以,linear blending由三部分组成:LinModel,hypothesis as transform,constriants。把g(t)当成feature transform,求解就和线性回归没什么区别。注意这里的限制条件α>=0,其实这个条件可以不要,因为α<0,只需要将正类看成负类,负类当成正类。

stacking
linear blending中,G(t)是g(t)的线性组合,而在any blending(stacking)中,G(t)可以是g(t)的任何函数形式(非线性)。其优点是模型复杂度高能获得更精确的预测模型;缺点是复杂模型也会带来过拟合的风险。所以stacking中也可采用regularization来提高泛化能力。
Bagging
前面说的blending方法是将一些已经得到的h进行aggregate。得到不同h的方法有很多,比如:
1.选取不同类型的模型
2.同类型模型设置不同的参数
3.借由算法本身的随机性,如PLA
4.选择不同数据样本
Bagging是利用bootstrap进行aggregation的操作。bootstrapping是统计学的一个工具,思想就是从已有数据集D中模拟出其他类似的样本Dt。也就是对应第四点,选择不同的数据样本。
bootstrapping的做法是,假设有N笔资料,先从中选出一个样本,再放回去,再选择一个样本,再放回去,共重复N次。这样我们就得到了一个新的N笔资料,这个新的Dt中可能包含原D里的重复样本点,也可能没有原D里的某些样本, 与D类似但又不完全相同。可以发现这种采样会有约36.8%的样本不会出现在bootstrap所采集的样本集合中,将这种未参与模型训练的数据称为袋外数据(OOB,out of bag).它可以用于取代测试集用于误差估计。
Adaboost
基本推导
Adaboost是Boosting族算法最著名的代表,该方法虽然简单但是特别有效。Boosting是一族可将弱学习器提升为强学习器的算法,根据这个定义,再联系一开始对偏差和方差的定义(结合那个打靶图),学习器由弱变强,即减小了偏差。下图是adaboost的一个基本步骤:

1.通过原始数据训练出一个学习器
2.注重该学习器在对应数据集中预测错误的样本,组成新的数据集,再训练一个学习器
3.不断重复
4.将这些学习器组合起来
所以从以上步骤来看,最重要的就是两点:
一. 如何更新数据集使得更关注错误样本
二. 是如何组合学习器
首先回一下前面说到得aggregation的一个原则每个学习器g要尽可能不一样。先来在adaboost中g是如何得到的:

这里参数u指的是样本的权重因子,比如一个数据集经过bootstrap后,新数据集中的样本是有重复的(u>1)和没有出现的(u=0)。所以g(t)是由u(t)得到的,g(t+1)是由u(t+1)得到的,所以如果g(t)这个模型在使用u(t+1)的时候(也就是在u(t+1)对应的数据集上测试)得到的error很大,即预测效果非常不好,那就说明g(t)和g(t+1)差异很大。如果其error近似为0.5时,就像是随机选择一样,这样救恩那个最大限度地保证两者的差异性。

要让分式等于0.5,即需要将错误点和正确点的数量设成一样,可以利用犯错的比例(错误率)来缩放,令犯错率为![]() ,在计算
,在计算
u(t+1)时,u(t)中错误的乘以![]() ,正确的乘以
,正确的乘以![]() 。但是在具体算法中我们会引入一个新的尺度因子:
。但是在具体算法中我们会引入一个新的尺度因子:
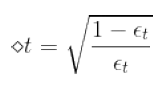
如果![]() <=0.5,则
<=0.5,则![]() >=1。所以对错误的u(t)与
>=1。所以对错误的u(t)与![]() 相乘就相当于把错误点放大了,而正确的u(t)与
相乘就相当于把错误点放大了,而正确的u(t)与![]() 相除就相当于把正确点缩小了。现在我们得到了u(t)的更新方法,那么初始u(t)该如何确定?通常来说,我们设u(1)=1/N,这样可以保证第一次Ein最小。
相除就相当于把正确点缩小了。现在我们得到了u(t)的更新方法,那么初始u(t)该如何确定?通常来说,我们设u(1)=1/N,这样可以保证第一次Ein最小。
有了初始值和更新方法,我们就能得到一个个不同的模型g。所以该考虑将所有的g合并起来了。
当前的方法是在计算g的同时也计算出线性组合系数α。这种算法使得最终求得g(t+1)的时候,所有的系数α也求得了。对于一个g,如果其错误率较小,那么它对应的α应该较大。我们构造:![]() ,
,![]() ,当
,当![]() 时,此时
时,此时![]() ,即此g的预测和随机选择一样,权值就该设为零。反之当
,即此g的预测和随机选择一样,权值就该设为零。反之当![]() 时,没有err,代表预测完全正确,此时
时,没有err,代表预测完全正确,此时![]() 。
。
综上所述,完整的adaptive boosting(AdaBoost)Algorithm流程如下:

误差分析
Adaboost算法理论上满足:

Eout是指泛化误差,Ein训练误差。已经证明了在adaboost中Ein在![]() 的条件下是可以降到0的。我们再来看看上式的第二项,不难看出,第二项的大小是与训练轮数T成正比并且与样本数N成反比,这和我们的一贯认知是符合的,即训练轮数越多,模型就越复杂,就越容易过拟合,泛化误差增大。而样本数越大,泛化误差就会越小。这似乎看起来十分完美,但是在实际应用中缺发现了问题:adaboost看起来好像不会overfitting
的条件下是可以降到0的。我们再来看看上式的第二项,不难看出,第二项的大小是与训练轮数T成正比并且与样本数N成反比,这和我们的一贯认知是符合的,即训练轮数越多,模型就越复杂,就越容易过拟合,泛化误差增大。而样本数越大,泛化误差就会越小。这似乎看起来十分完美,但是在实际应用中缺发现了问题:adaboost看起来好像不会overfitting
Adaboost不会过拟合?

从图中可以看到,训练误差在第八轮已经降到了0,按刚才的理论,训练误差到0后如果接着增大模型,应该会导致过拟合,但是实际上测试误差依然还在下降。这违背了奥卡姆剃刀这个科学基本原则。在训练误差都为0的情况下,我们应该选择更简单的那个。
在解释这个问题前我们先来看看adaboost的两种解释:margin theory和statistical view
statistical view
在统计学家看来,机器学习是首先定义一个损失函数,然后找个方法来不断优化它,比如SVM的hinge loss和LR的exponential loss,他们都是01loss的上界且是凸的,所以用来代替并优化,adaboost也不例外,下面我们就来分析下:
在adaboost中的权重更新中,对correct样本和incorrect样本,u(t+1)的表达式是不同的,现在将两种情况合二为一:

对correct样本来说,![]() ;反之,
;反之,![]() 。可以看出,u(t+1)由u(t)与某个常数相乘得到,所以,我们可以将最后一轮更新的u(T+1)写成u(1)的级联形式,再加之初始值是1/N,所以:
。可以看出,u(t+1)由u(t)与某个常数相乘得到,所以,我们可以将最后一轮更新的u(T+1)写成u(1)的级联形式,再加之初始值是1/N,所以:
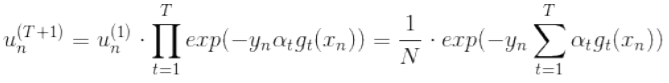
上式 被称为voting score,而最终的模型就是
被称为voting score,而最终的模型就是 。voting score由许多
。voting score由许多![]() 乘以各自的系数线性组合而成。我们可以将
乘以各自的系数线性组合而成。我们可以将![]() 看成对xn的特征转换
看成对xn的特征转换![]() ,α就是线性模型中的权重w。这里联系SVM中,w与
,α就是线性模型中的权重w。这里联系SVM中,w与![]() 的乘积再除以w的模就是margin。所以,voting score也可以看成没有正则化(即没有除w的模)的距离。这里也是为后面讲adaboost的margin theory中margin的定义。所以我们可以将voting score看成该点到分类边界距离的。从效果上说,距离越大越好,也就是voting score尽可能大一些。除此之外,乘积再与yn相乘,表示点是在正确的一方(乘积为正)还是错误的乙方(乘积为负)。所以算法的目的就是让yn与voting score的乘积是正的,且越大越好。那在
的乘积再除以w的模就是margin。所以,voting score也可以看成没有正则化(即没有除w的模)的距离。这里也是为后面讲adaboost的margin theory中margin的定义。所以我们可以将voting score看成该点到分类边界距离的。从效果上说,距离越大越好,也就是voting score尽可能大一些。除此之外,乘积再与yn相乘,表示点是在正确的一方(乘积为正)还是错误的乙方(乘积为负)。所以算法的目的就是让yn与voting score的乘积是正的,且越大越好。那在![]() 的推导中,
的推导中,![]()
就该越小越好,也就是![]() 越小越好。
越小越好。
在Adaboost中,随着训练轮数的增加,每个样本的u是逐渐减小的。减小需要轮数到一定程度,比如第一轮u就可能变大。之所以会减小,是因为经过一定程度的训练,每个样本都会大概率被分对,所以对应的u应该减小。这是从单个样本点来看,总体来说,所有样本的![]() 之和也应该最小。所以我们的目标就是在(T+1)轮学习后,让
之和也应该最小。所以我们的目标就是在(T+1)轮学习后,让![]() 之和尽可能小,即:
之和尽可能小,即:

这个形式就是指数损失,因为目前也是用于二分类,所以来看看它和01loss的关系。

无独有偶,指数损失也是01损失的一个凸的上界。所以现在我们的问题就是来使其取最小值,同样也是使用梯度下降法。和以往不同的是,这里的梯度方向是一个函数,而不是一个向量。函数和向量的唯一区别就是一个下标是连续的,一个下标是离散的,二者在梯度下降算法上没太大区别。经过推导可得:(这部分更加详细的推导见)

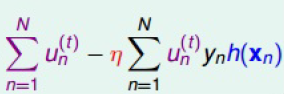
这样Eada就被分解成了两部分,一个是前N个u之和,也就是当前所有Ein之和;另一个包含下一步前进方向h(xn)和步长![]() 的第二项。所以如果要最小化Eada的话,就要让第二项(包括负号)越小越好。则我们的目标就是找到好的h(xn)和步长
的第二项。所以如果要最小化Eada的话,就要让第二项(包括负号)越小越好。则我们的目标就是找到好的h(xn)和步长![]() 来最小化
来最小化 。
。
对于二分类来说,y和h(x)均限定取值1或-1,据此我们对上式进行推导和平移,得:

所以现在就目标就成了最小化Ein了,而能让Ein变得更小的正是表现好的g,所以这里g(基学习器)就等于h(下降方向)。
Adaboost中使用base algorithm得到的g就是让Eada减小的方向,而步长![]() 就是前面的α,也就是Adaboostg的权重。所以,Adaboost所做的其实就是在gradient descent上找到下降最快的方向和最大的步长。
就是前面的α,也就是Adaboostg的权重。所以,Adaboost所做的其实就是在gradient descent上找到下降最快的方向和最大的步长。
从这个角度来理解adaboost可以将其分为三部分:
1.优化的是指数函数
2.是一个加性模型
3.用梯度下降或牛顿法优化
这样理解有几个好处,其中最重要的是能够通过改写损失函数或者优化方法来构建其他的算法,比如GBDT(gradient boost decision tree),后面我们会介绍到。但是统计学理论在实际中被发现理论和实验不一致的地方,而这还不是最重要的问题,最重要的是它依然没能解决我们之前提到的adaboost看起来好像不会overfitting的这个问题。所以下面我们从margin理论来探讨下。
margin theory
前面也说到了,adaboost里的margin和SVM中的margin有异曲同工之妙。下图就能形象的解释adaboost为什么不会overfitting。

当分类面是虚线时,训练损失已经为零,继续下去训练损失依然为零,但是分类面能变得更好,所以测试损失依然会下降。
Decision Tree
我们一开始就提出的6种aggregation type,现在已经介绍了五种,下面介绍最后一种,Decision Tree。先来直观上看下为什么决策树属于混合模型,决策树是一种树结构,我们可以将根节点到树最下面的一个叶节点看成一个g(hypothesis),这样整个决策树就是许多不同的g的非线性组合,也就对应了我们前面表中所说的,learning&&conditional的情况。
决策树从直观上非常好理解,它与人类根据实际条件做决策的思维方式十分相似。这种理解方式相信大家都十分了解,下面我们要从数学形式方面来阐述决策树。可以利用条件分支将整体G(x)分成若干个Gc(x),也就是将大树分为若干个小树。

上式中,G(x)表示完整的大树,即full-tree hypothesis,b(x)表示每个分支条件,即branching criteria, Gc(x)表示第c个分支下的子树,即sub-tree。这种结构被称为递归型的数据结构,即将大树分割成不同的小树,再将小树继续分割成更小的子树。所以,决策树可以分为两部分:root和sub-trees。
决策树的流程可以分为四个部分:
1.确定划分不同分支的标准和条件是什么
2.将整个数据集D根据分支个数c和条件,划分为不同分支下的子集Dc
3.对每个分支下的Dc进行训练,得到相应的机器学习模型Gc(这里可以是其他的机器学习模型)
4.最后将所有分支下的Gc合并到一起,组成G(x)
除此之外,这种递归的形式需要终止条件,不然会一直进行下去。所以,决策树的基本算法中最重要的四点就是:
1.分支个数
2.分支条件
3.终止条件
4.基本算法
以上就是决策树的基本通用算法。根据不同的目标函数,建立决策树主要有以下三种算法:
1.ID3(Iterative Dichotomiser),使用信息增益
2.C4.5,使用信息增益率
3.CART(Classification And Regression Tree),Gini系数
一个特征的信息增益(或信息增益率,Gini系数的降低值)越大,说明该特征对样本的熵减少的能力更强,这个属性使得数据由不确定性变成确定性的能力越强。这里就不详细介绍,会专门再写一个来介绍这三种算法。
Random Forest
基础概念及为什么叫随机森林
前面介绍了Bagging和Decision Tree,随机森林就是将两者结合起来。我们先来看看两者各自的特点:
1.bagging具有减小方差的特点,因为bagging将不同的g求平均。
2.决策树具有增大方差的特点,因为它对数据集D比较敏感,所以不同的D对得到较大的方差(和过拟合有联系?)
所以我们希望将两者结合起来互补,即用bagging的方式将众多的CART 决策树进行uniform结合起来,这就是随机森林。有趣的是为什么会叫随机森林,由树到森林是因为很多树组成,那么随机是从何而来呢?我们从其算法流程来分析:
1.利用bootstrap从数据集D中选取新的数据集Dc(随机选择)
2.利用Dc构建CART树,在构建的时候不一定是用所有的特征,而是随机地选择一部分特征,这样既保证了决策树的多样性,也使得算法更有效率。除此之外,还可以将现有的特征x,通过线性组合来得到不同的特征。这种方法使得每次分支得到的不再是单一的子特征集合,而是子特征的线性组合,这样又增强了随机性。
可以看见随机森林中处处都有随机的思想,故名副其实。还值得注意的是,随机森林最常用的基础学习器是决策树,但它不局限于此,它也可以使用svm,lr等其他分类器,这些分类器组成的总分类器仍然叫做随机森林。
Out-Of-Bag Estimate
随机森林最重要的一点就是bagging,前面第一次提到bagging的时候我们了解到,通过bootstrap得到的新样本集Dc不能涵盖原数据集全部数据,会有大概36.8%的样本不被包含进去。这个值是如下计算得到的:

我们就可以顺便利用这些OOB样本去做validation,这叫做随机森林的self-validation。这种validation相比以前的cross validation的好处就是不用重新训练。
feature selection
如果样本特征过多,则需要考虑舍弃一些。要舍弃的特征主要分为两类:
1.冗余特征 ,如重复的,生日和年龄这种
2.不相关特征, 比如房价预测时你的婚姻情况
那么具体该如何操作,最简单的想法是计算出每个特征的重要性(权重),然后再根据重要性来排序进行选择就行。由于随机森林算法是一个非线性的模型,我们不能单纯以线性模型中的权重作为衡量特征重要性的标准。
换个角度,在随机森林中,特征选择的核心思想是random test,即对于某个特征,如果用另外一个随机值替代它之后表现得比之前更差,则说明该特征比较重要。最常用的是Permutation Test,该方法是通过将第i个维度特征的所有数据重新的随机调整位置,然后比较一下原始数据和调整之后的数据表现的差距,来评价这个维度的特征是有多么重要。
但是 如果我们将原数据集D的第i个特征打乱后重新训练,再验证,再比较出前后差距,会导致除了第i个特征其他的特征都重复训练了,过程是繁琐的。所以我们可以把permutation的操作从原始数据集D中迁移到OOB中,也就是说在训练的时候仍然使用D,但是在OOB验证的时候,将所有的OOB样本的第i个特征打乱。
RF将bagging与decision tree结合起来,通过把众多的决策树组进行组合,构成森林的形式,利用投票机制让G表现最佳,分类模型更稳定。其中为了让decision tree的随机性更强一些,可以采用randomly projected subspaces操作,即将不同的features线性组合起来,从而进行各式各样的切割。同时,我们也介绍了可以使用OOB样本来进行self-validation,然后可以使用self validation来对每个特征进行permutaion test,得到不同特征的重要性,从而进行feature selection。总的来说,RF算法能够得到比较平滑的边界,稳定性强,前提是有足够多的树。
Adaptive Boosted Decision Tree
随机森林是bagging和决策树的结合,那如果将bagging替换成adaboost,情况会如何呢?回顾下adaboost,每训练一次就改变一次数据样本的分布,从而得到不同的g,在训练的同时得到组合系数α,线性组合得到G。这其中的重点是改变数据样本的分布,即改变每个样本的系数u(回顾之前所说)。但是在决策树模型中,并没有引入样本系数u这一概念,所以要因地制宜。
具体做法是将一个决策树看成一个黑盒,即不对决策树算法本身进行修改,转而对数据集进行处理。其实,权重u实际上也表示该样本在数据集中出现的次数,反映了其出现的概率。所以我们可以根据u值来对原数据集进行一次重新的随机sampling,也就是带权值的随机抽样。进行该操作后得到的新的数据集Dc就可以直接带入决策树中进行训练。
如此一来,我们就得到了不同的g,下面要解决的就是系数α,我们知道,α是根据错误率来的:
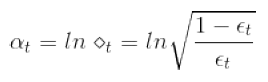
这里有一个问题,如果用所有的样本来训练一个完全长成树(fully grown tree),也就是如果每个样本都不同的话,那么最后所有的样本都会被分开,这样一来Ein(g)=0,训练误差为0,也就是说错误率为0,从而导致该g的权重α=∞,相当于一个g就决定了整个G的结构。这样是发挥不了aggregation的作用的,所以需要改进。
首先看看是什么导致α=∞。有两个原因:
1. 使用了所有样本进行训练——解决方法:每训练一课树仅用部分数据
2.树的分支过多——结局方法:剪枝
也就是说AdaBoost-DTree使用的是pruned DTree,也就是说将这些预测效果较弱的树结合起来,得到最好的G,避免出现autocracy。















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









