







MNIST : 是一个入门级的计算机视觉数据集,它包含各种手写数字图片,每一张图片对应的标签。
目的 : 训练一个机器学习模型用于预测图片里面的数字。
模型开始,它叫做Softmax Regression。
重点:理解设计思想-->TensorFlow工作流程和机器学习的基本概念。
1、MNIST数据集
数据集被分成两部分:60000行的训练数据集( mnist.train )和10000行的测试数据集( mnist.test )。
每个MNIST数据单元:一张包含手写数字的图片和一个对应的标签。训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是mnist.train.images ,训练数据集的标签是mnist.train.labels 。每一张图片包含28X28个像素点。
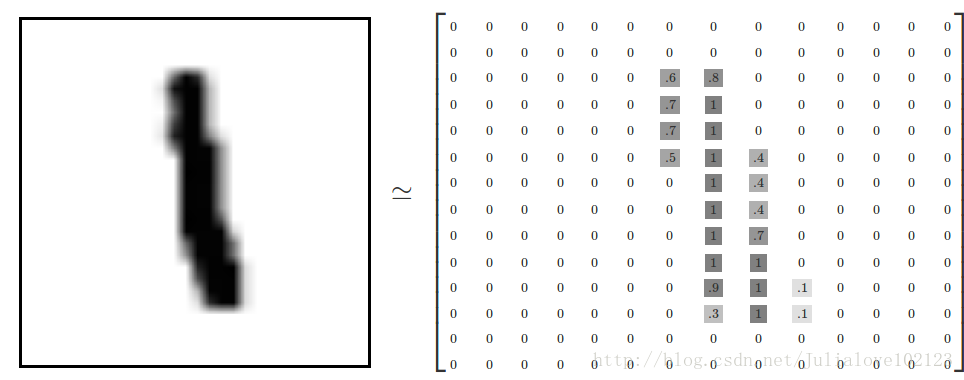
2、Softmax回归
3、实现回归模型
整体步骤:
- 加载数据;
- 定义输入、权重、预测值、真实值、误差、评估方式;
- 开启会话,并初始化;
- 训练,计算误差,并优化误差;
- 测试,输出;
#-*-coding:utf-8-*-
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#1、输入数据
mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
#2、定义权值、偏置
sess = tf.InteractiveSession()
#通过操作符号变量来描述这些可交互的操作单元,x是占位符
x=tf.placeholder(tf.float32,[None,784])
#一个Variable 代表一个可修改的张量
W=tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
y=tf.nn.softmax(tf.matmul(x,W)+b) #预测分布 one-hot vector
y_=tf.placeholder(tf.float32,[None,10]) #实际分布
#3、训练
#loss或者说cost
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y),reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
#TensorFlow在这里实际上所做的是,它会在后台给描述你的计算的那张图里面增加一系列新的计算操作单元用于
实现反向传播算法和梯度下降算法。然后,它返回给你的只是一个单一的操作,当运行这个操作时,它用梯度下
降算法训练你的模型,微调你的变量,不断减少成本。
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#tf.global_variables_initializer().run()
#开始训练模型
for i in range(10000):
batch_xs,batch_ys = mnist.train.next_batch(100)
#随机抓取训练数据中的100个批处理数据点,然后我们用这些数据点作为参数替换之前的占位符来运行train_step 。
#train_step.run({x:batch_xs,y_:batch_ys})
sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys})
#4、评估模型
corret_pre = tf.equal(tf.arg_max(y,1),tf.argmax(y_,1))
#tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如tf.argmax(y,1) 返回的是模型对于任一输入x预测到的标签值,而tf.argmax(y_,1) 代表正确的标签,我们可以用tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
accuracy = tf.reduce_mean(tf.cast(corret_pre,tf.float32))
print sess.run(accuracy,feed_dict=({x:mnist.test.images,y_:mnist.test.labels})补充知识:
one_hot = true
在读取mnist数据时,需要执行one-hot为true。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data", one_hot=True)在多类场景下,onehot=true表示,只有一个元素的值是1,其他元素的值是0, 一个长度为n的数组,只有一个元素是1.0,其他元素是0.0。
onehot=False则没有这样的限制。
例如在n为10的情况下,标签2对应的onehot标签就是 [0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 ,0.0, 0.0]
使用onehot的直接原因是现在多分类cnn网络的输出通常是softmax层,输出是一个概率分布,从而要求输入的标签也以概率分布的形式出现,进而算交叉熵。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
BATCH_SIZE=10
mnist =input_data.read_data_sets('MNIST_data/')
xs,ys = mnist.train.next_batch(BATCH_SIZE)
print(ys.shape)
print(ys)
print('-------------编码后--------------')
mnist =input_data.read_data_sets('MNIST_data/',one_hot = True)
xs,ys = mnist.train.next_batch(BATCH_SIZE)
# print(xs.shape)
print(ys.shape)
print(ys)Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
(10,)
[7 0 8 2 4 5 7 8 6 2]
-------------编码后--------------
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
(10, 10)
[[ 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[ 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[ 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]]
tf.reduce_mean
用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。
reduce_mean(input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None)
- 第一个参数input_tensor: 输入的待降维的tensor;
- 第二个参数axis: 指定的轴,如果不指定,则计算所有元素的均值;
- 第三个参数keep_dims:是否降维度,设置为True,输出的结果保持输入tensor的形状,设置为False,输出结果会降低维度;
- 第四个参数name: 操作的名称;
- 第五个参数 reduction_indices:在以前版本中用来指定轴,已弃用;
以一个维度是2,形状是[3,3]的tensor举例:
import tensorflow as tf
x = [[1,2,3],
[1,2,3]]
xx = tf.cast(x,tf.float32)
mean_all = tf.reduce_mean(xx, keep_dims=False)
mean_0 = tf.reduce_mean(xx, axis=0, keep_dims=False)
mean_1 = tf.reduce_mean(xx, axis=1, keep_dims=False)
with tf.Session() as sess:
m_a,m_0,m_1 = sess.run([mean_all, mean_0, mean_1])
print m_a # output: 2.0
print m_0 # output: [ 1. 2. 3.]
print m_1 #output: [ 2. 2.]
如果设置保持原来的张量的维度,keep_dims=True ,结果:
print m_a # output: [[ 2.]]
print m_0 # output: [[ 1. 2. 3.]]
print m_1 #output: [[ 2.], [ 2.]]
类似函数还有:
tf.reduce_sum :计算tensor指定轴方向上的所有元素的累加和;
tf.reduce_max : 计算tensor指定轴方向上的各个元素的最大值;
tf.reduce_all : 计算tensor指定轴方向上的各个元素的逻辑和(and运算);
tf.reduce_any: 计算tensor指定轴方向上的各个元素的逻辑或(or运算);
tf.cast()
cast(
x,
dtype,
name=None
)
将x的数据格式转化成dtype.例如,原来x的数据格式是bool, 那么将其转化成float以后,就能够将其转化成0和1的序列。反之也可以
【code】
a = tf.Variable([1,0,0,1,1])
b = tf.cast(a,dtype=tf.bool)
sess = tf.Session()
sess.run(tf.initialize_all_variables())
print(sess.run(b))
#[ True False False True True]















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











