









 本文详细介绍了开源搜索引擎Nutch的功能特点、工作流程,以及如何在Ubuntu上安装和配置Nutch,包括JDK、svn、ant的安装,Nutch源代码的下载和编译,最后展示了如何使用Nutch的爬虫抓取网页。
本文详细介绍了开源搜索引擎Nutch的功能特点、工作流程,以及如何在Ubuntu上安装和配置Nutch,包括JDK、svn、ant的安装,Nutch源代码的下载和编译,最后展示了如何使用Nutch的爬虫抓取网页。
一、Nutch介绍
1. 什么是Nutch
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己
的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本之后,Nutch已经从搜索引擎演化为网络爬虫,接着Nutch进一步演化为两大分支版本:1.X和2.X,这两大分支最大的区别在于2.X对底层的数据存储进行了抽象以支持各种底层存储技术。
2. Nutch相关技术
在Nutch的进化过程中,产生了Hadoop、Tika、Gora和Crawler Commons四个Java开源项目。如今这四个项目都发展迅速,极其火爆,尤其是Hadoop,其已成为大规模数据处理的事实上的标准。Tika使用多种现有的开源内容解析项目来实现从多种格式的文件中提取元数据和结构化文本,Gora支持把大数据持久化到多种存储实现,Crawler Commons是一个通用的网络爬虫组件。
3. Nutch 功能特点
Nutch 致力于让每个人能很容易, 同时花费很少就可以配置世界一流的Web搜索引擎. 为了完成这一宏伟的目标, Nutch必须能够做到:
- 每个月取几十亿网页
- 为这些网页维护一个索引
- 对索引文件进行每秒上千次的搜索
- 提供高质量的搜索结果
- 以最小的成本运作
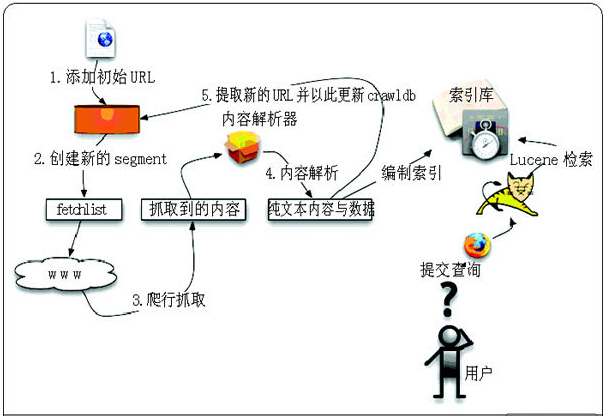
4. Nutch工作流程
(1) 创建一个新的WebDb (admin db -create).
(2) 将抓取起始URLs写入WebDB中 (inject).
(3) 根据WebDB生成fetchlist并写入相应的segment(generate).
(4) 根据fetchlist中的URL抓取网页 (fetch).
(5) 根据抓取网页更新WebDb (updatedb).
(6) 循环进行3-5步直至预先设定的抓取深度。
(7) 根据WebDB得到的网页评分和links更新segments (updatesegs).
(8) 对所抓取的网页进行索引(index).
(9) 在索引中丢弃有重复内容的网页和重复的URLs (dedup).
(10) 将segments中的索引进行合并生成用于检索的最终index(merge).
在创建一个WebDB之后(步骤1), “产生/抓取/更新”循环(步骤3-6)根据一些种子URLs开始启动。当这个循环彻底结束,Crawler根据抓取中生成的segments创建索引(步骤7-10)。在进行重复URLs清除(步骤9)之前,每个segment的索引都是独立的(步骤8)。最终,各个独立的segment索引被合并为一个最终的索引index(步骤10)。
二、Ubuntu上安装Nutch
1. 安装JDK
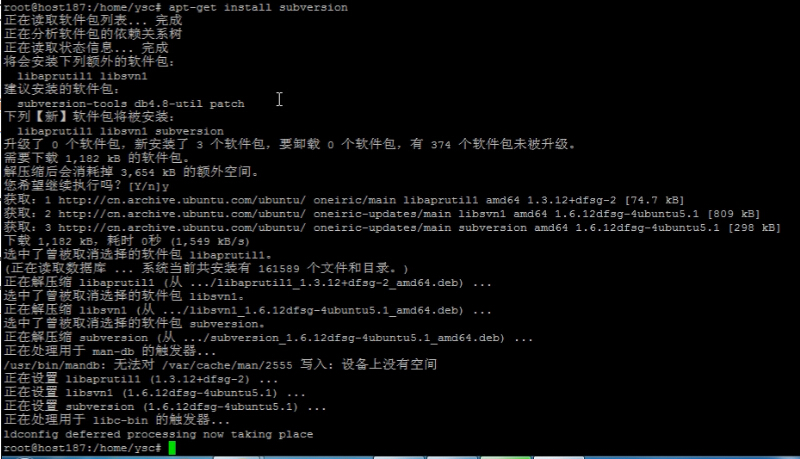
2. 安装svn
apt-get install subversion
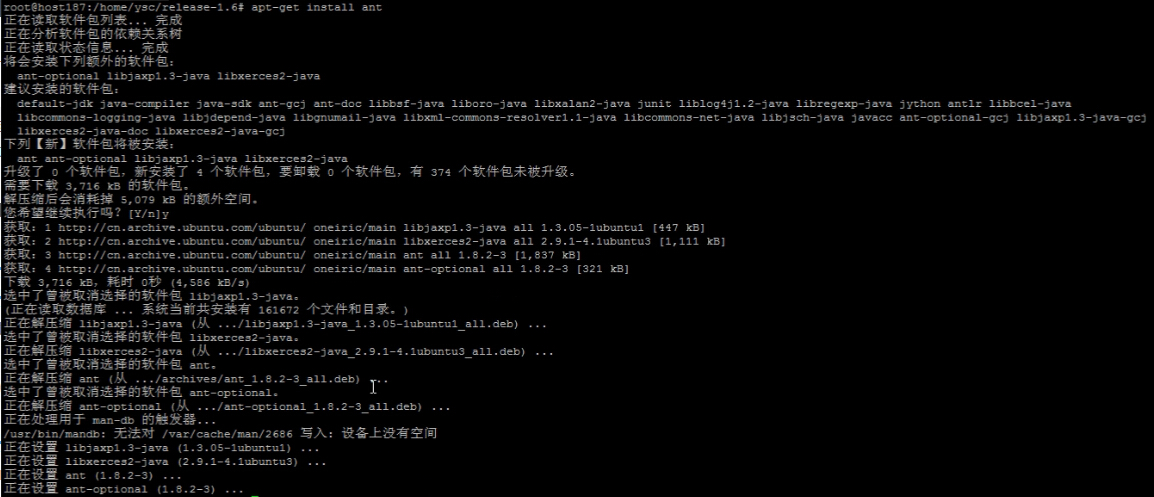
3. 安装ant
apt-get install ant
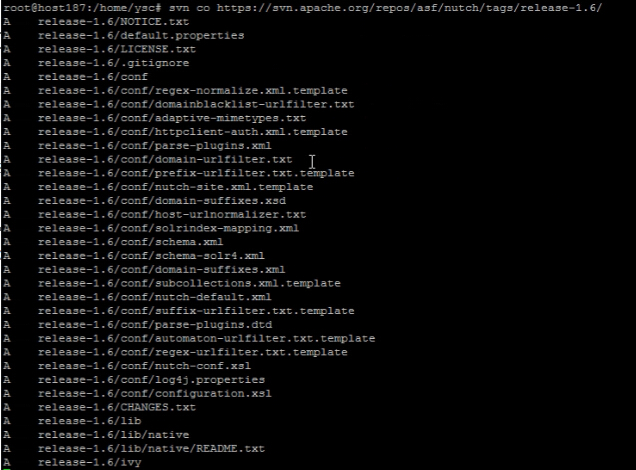
4. 使用svn下载Nutch源代码
svn co https://svn.apache.org/repos/asf/nutch/tags/release-1.6
三、编译Nutch
1. 进入release-1.6
cd release-1.6
目录结构如下:
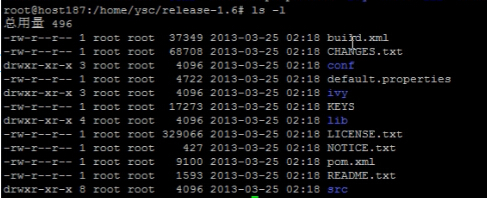
2. 修改配置文件,增加UA
修改conf目录下的nutch-site.xml文件,增加UA:
<property>
<name>http.agent.name</name>
<value>Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1</value>
</property>3. 使用ant编译源代码
直接输入ant编译
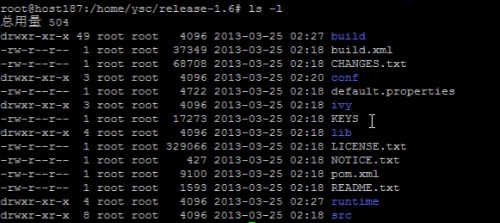
编译成功之后,目录下面会多几个目录:
四、使用Nutch中的爬虫抓取网页
1. 进入runtime->local目录
cd runtime/local
2. 建一个目录保存需要抓取的URL信息
mkdir urls
vi urls/url.txt
将需要抓取的URL写入url.txt中:

3. 使用Crawl命令抓取网页
nohup bin/nutch crawl urls -dir data -depth 3 -threads 100 &


















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









