







 本文介绍了使用Python Scrapy框架抓取非小号网站上的所有数字货币详情链接和名称。首先,环境配置包括OS、Python、Scrapy、PyMongo等。接着,内容说明目标是抓取货币链接和名称,设计数据库仅存储货币名称、URL和ID。在MongoDB中定义Pipeline以避免重复数据。然后,创建Scrapy项目,设置MongoDB存储,并定义爬虫文件。页面分析中,利用XPath选择器和正则表达式提取所需信息,过滤掉不需要的数据。最后,展示了部分抓取数据的截图。
本文介绍了使用Python Scrapy框架抓取非小号网站上的所有数字货币详情链接和名称。首先,环境配置包括OS、Python、Scrapy、PyMongo等。接着,内容说明目标是抓取货币链接和名称,设计数据库仅存储货币名称、URL和ID。在MongoDB中定义Pipeline以避免重复数据。然后,创建Scrapy项目,设置MongoDB存储,并定义爬虫文件。页面分析中,利用XPath选择器和正则表达式提取所需信息,过滤掉不需要的数据。最后,展示了部分抓取数据的截图。
一、环境
- OS:win10
- python:3.6
- scrapy:1.3.2
- pymongo:3.2
- pycharm
环境搭建,自行百度
二、本节内容说明
本节主要抓取非小号收录的所有数字货币的详情链接和数字货币名称。
三、数据库说明
1. 货币详情页链接
非小号大概收录了1536种数字货币的信息:
http://www.feixiaohao.com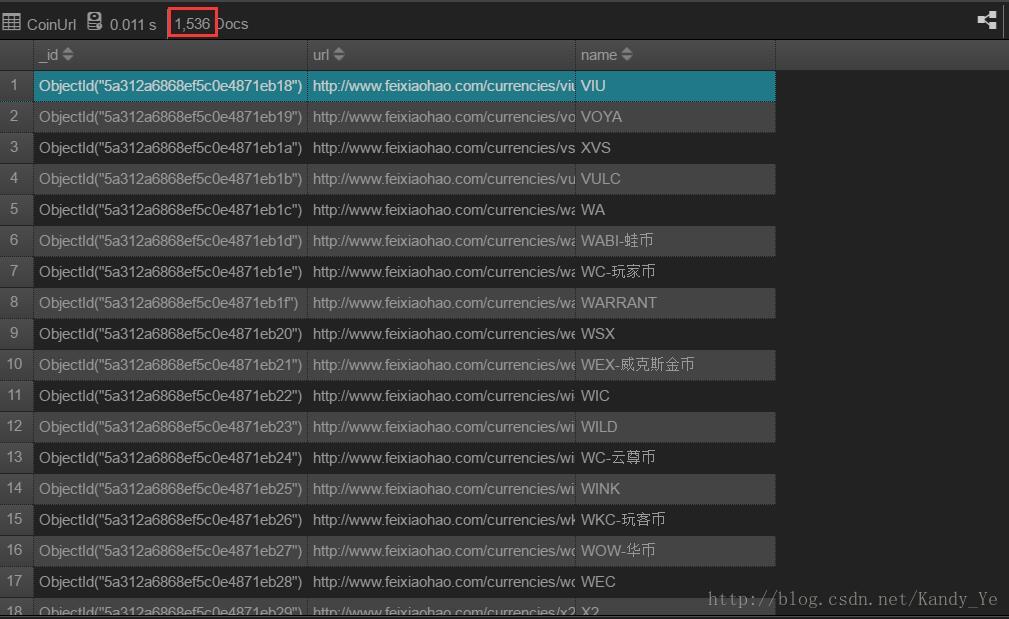
为了后面抓取详细的信息做准备,需要先抓取详情页的地址,所以我们对于数字货币的链接地址数据库设计,只需要货币名称和对应的URL即可,然后是id。如下:
name #分类名称
url #分类url
_id #分类id四、抓取说明
由于非小号网站在首页提供了显示全部数字货币的功能,所以我们没有必要分页抓取,偷个懒:
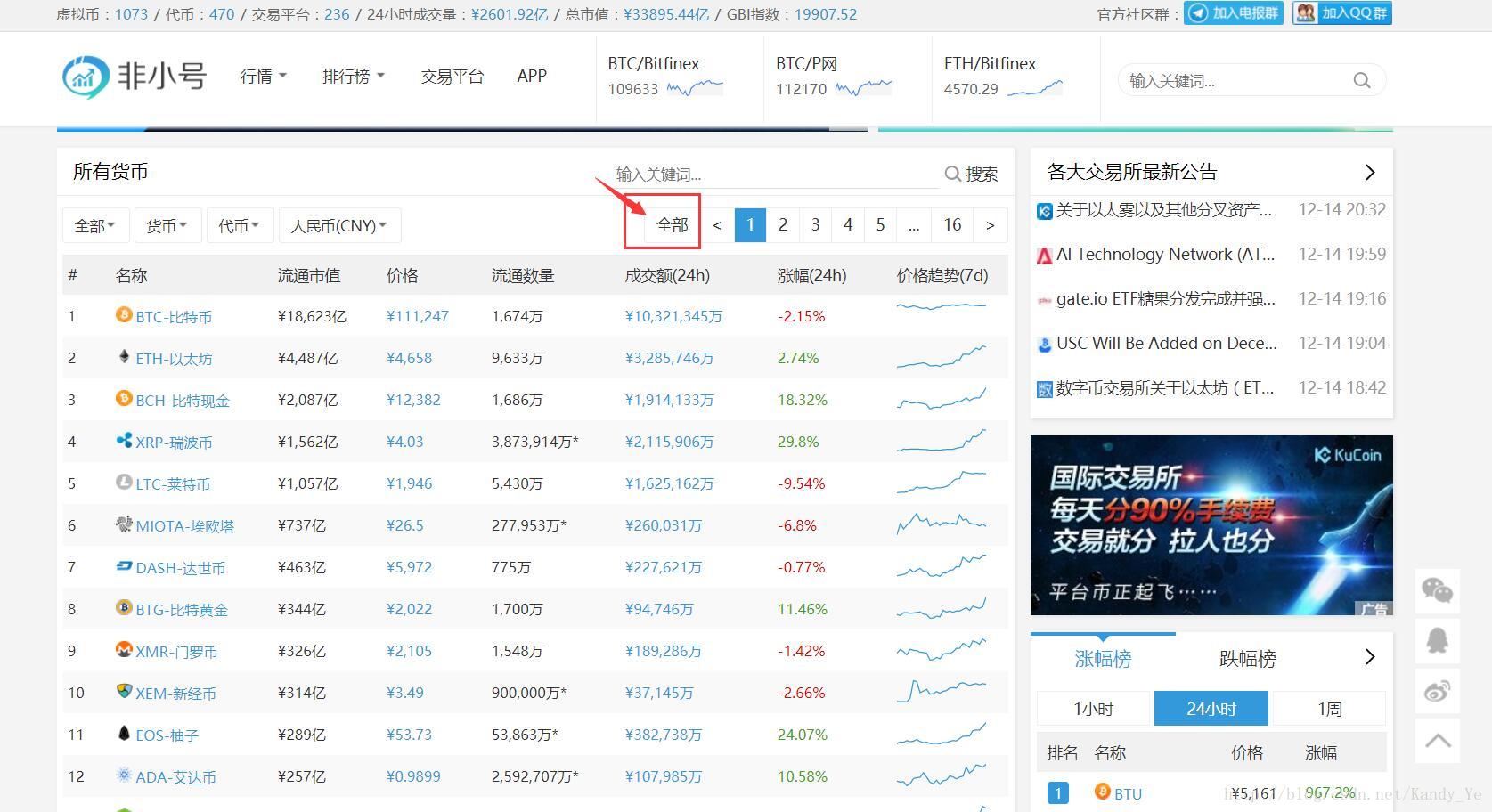
后面的抓取直接使用显示全部数字货币的链接:
http://www.feixiaohao.com/all/1. 新建项目
在你的工作目录里面新建一个scrapy的项目,使用如下命令:
scrapy startproject coins目录结构如下:
c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









