









Scrapy, a fast high-level web crawling & scraping framework for Python
CSDN博客首页如下,包括:推荐、资讯、人工智能等栏目
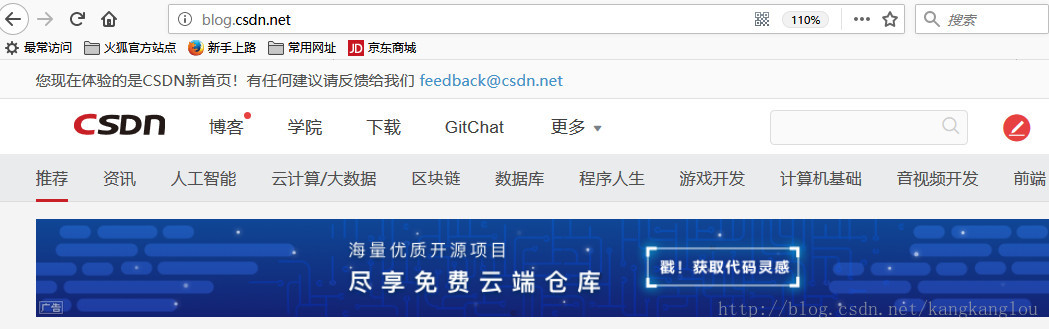
每一个栏目下有不同的推荐文章列表,我们使用Scrapy来读取这些栏目的推荐文章列表
定义爬虫如下
class QuotesSpider(scrapy.Spider):
name = "csdn"
def start_requests(self):
urls = [
'http://blog.csdn.net'
]
tag = getattr(self, 'tag', None)
print("tag is %s" % tag)
for url in urls:
print("do request on %s" % url)
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# page = response.url.split("/")[-2]
# filename = 'data/quotes-%s.html' % page
# with open(filename, 'wb') as f:
# f.write(response.body)
# self.log('Saved file %s' % filename)
for ul in response.css(".nav_com ul li"):
yield {
'nav_text': ul.css("a::text").extract_first(),
'nav_href': ul.css("a::attr(href)").extract_first(),
}
yield response.follow(ul.css("a::attr(href)").extract_first(), callback=self.get_article_list)
# for a in response.css(".list_con"):
# yield {
# 'article_title': a.css("a::text").extract_first(),
# 'article_href': a.css("a::attr(href)").extract_first()
# }
# next_page = response.css('.nav_com ul li a::attr(href)')[2].extract()
# if next_page is not None:
# print("next_page %s" % next_page)
# yield response.follow(next_page, callback=self.parse)
@staticmethod
def get_article_list(response):
for a in response.css(".list_con"):
yield {
'article_title': a.css("a::text").extract_first(),
'article_href': a.css("a::attr(href)").extract_first()
}
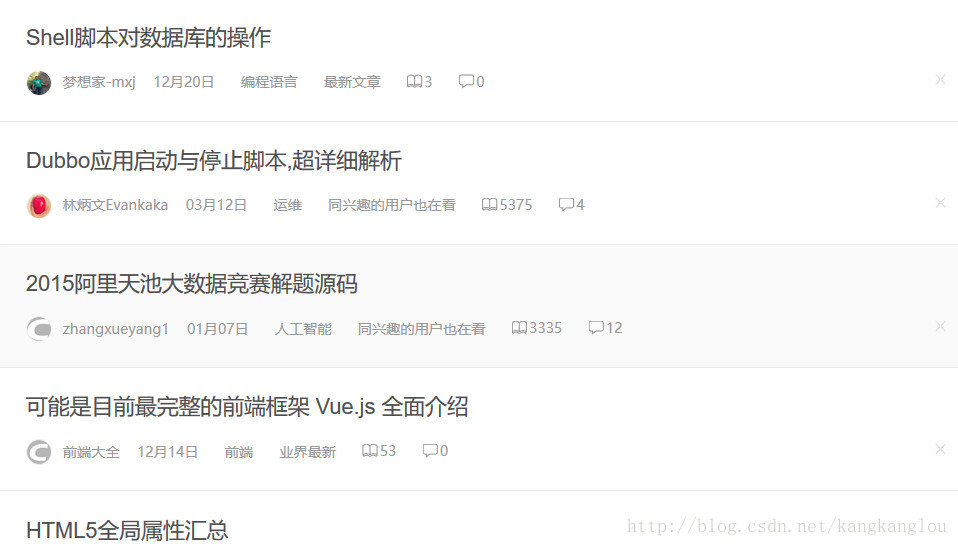
爬取结果如下















 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









