










转载请注明出处:http://blog.csdn.net/l1028386804/article/details/45748111
一、安装系统
虚拟软件 : VMware workstation 10
系统: Centos 6.4 32bit
Master IP : 192.168.56.131
Slave IP : 192.168.56.132
User & pass: hadoop
注:一台充当master(namenode),一台充当slave(datanode)。这是最小的集群(除伪分布式)
二、关闭防火墙
master和slave分别关闭防火墙(要在root用户下)

三、修改hostname
永久性修改:

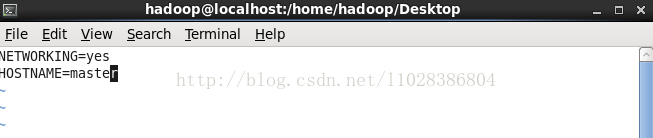
验证
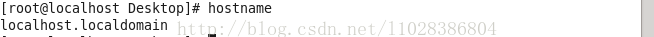
没显示修改过的名称,因为重启后才会生效
暂时性:

现在不重启的系统已经生效了,但是命令行头还是显示localhost,重开一个终端就生效了

slave的操作同上,只不过master改成slave就可以了。
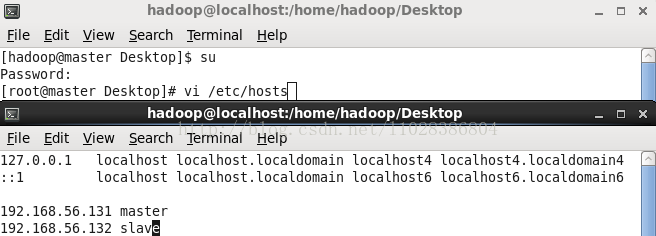
四、修改host文件
host文件是一个地址映射文件(不清楚找度娘)
分别在master和slave的host文件中写入master和slave的主机名与IP地址的映射
slave同上
五、设置SSH免密码登录
免密码登录是hadoop通信需要
具体原理找度娘
这里使用Hadoop专用账户:hadoop;
具体步骤:
1. 执行命令ssh-keygen -t rsa之后一路回 车,查看刚生成的无密码钥对: cd ~/.ssh 后执行 ll
2.把 id_rsa.pub 追加到授权的 key 里面去。 执行命令 cat ~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys
3.修改权限: 执行 chmod 600~/.ssh/authorized_keys
4.执行 vi/etc/ssh/sshd_config去掉下列内容的#号注释符


vi修改后重启SSH服务

5.将公 钥复制到所有的 slave机器上 :scp ~/.ssh/id_rsa.pub 192.168.56.132 :~/ 然后 输入 yes ,最后输入 slave 机器的密码

6.在 slave机器上 创建 .ssh 文件夹 :mkdir ~/.ssh 然后 执行 chmod 700 ~/.ssh (若文件夹以存在 则不需要创建)

7.追加到授权文件 authorized_keys执行命令 :cat ~/id_rsa.pub >> ~/.ssh/authorized_keys 然后 执行 chmod 600 ~/.ssh/authorized_keys
8.在slave上重复第四步
9.测试

六、安装JDK
1.下载JDK(本次使用jdk1.6_45)
2.上传到/usr/java/目录下
3.改变Jdk执行权限
4.执行安装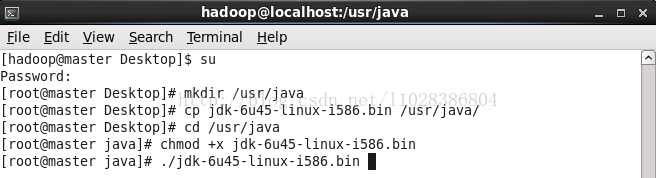
5.配置环境变量

添加:
exportJAVA_HOME=/usr/java/jdk1.6.0_45
exportCLASSPATH=.:$JAVA_HOME/lib/tools.jar:/lib/dt.jar
export PATH=$JAVA_HOME/bin:$PATH6.使修改立即生效
7.测试

七、Hadoop安装
1.在/home/hadoop/下创建文件夹cloud,下载hadoop-2.2.0.tar.gz到该目录下
2.解压
3.配置环境变量并使其立即生效
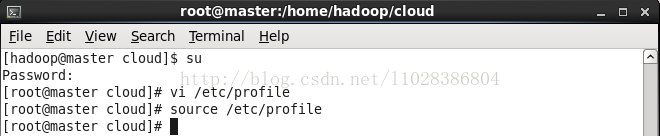
添加:
exportHADOOP_DEV_HOME=/home/hadoop/cloud/hadoop-2.2.0
exportPATH=$PATH:$HADOOP_DEV_HOME/bin
exportPATH=$PATH:$HADOOP_DEV_HOME/sbin
exportHADOOP_MAPARED_HOME=${HADOOP_DEV_HOME}
exportHADOOP_COMMON_HOME=${HADOOP_DEV_HOME}
exportHADOOP_HDFS_HOME=${HADOOP_DEV_HOME}
exportYARN_HOME=${HADOOP_DEV_HOME}
exportHADOOP_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop4.测试
5.修改Haoop配置文件
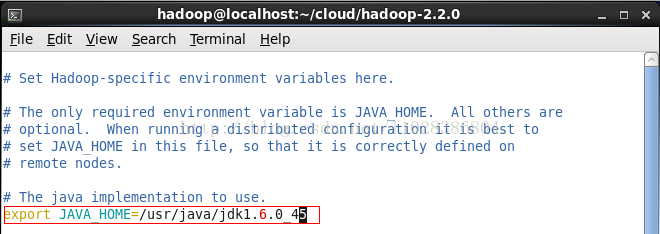
5.1 修改 hadoop-env.sh 配置文件,设置 jdk 所在的路径
5.2修改core-site.xml配置文件(创建文件夹/home/hadoop/cloud/tmp/hadoop2.2.0)

在<configration>中添加
<property>
<name>fs.default.name</name>
<value>hdfs://master:8020</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/cloud/tmp/hadoop2.2.0</value>
</property>
5.3修改yarn-site.xml配置文件
在 <configration> 中 添加:<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
5.4生成mapred-site.xml配置文件

5.5修改mapred-site.xml配置文件(注意/hadoop和/opt的创建和权限问题)
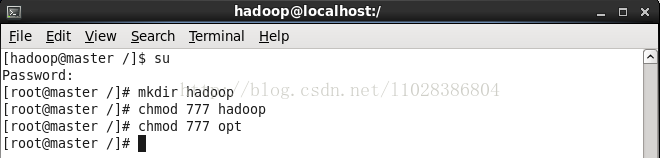
在<configration>中添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>file:/hadoop/mapred/system/</value>
<final>true</final>
</property>
<property>
<name>mapred.local.dir</name>
<value>file:/opt/cloud/hadoop_space/mapred/local</value>
<final>true</final>
</property>
5.6修改hdfs-site.xml配置文件
在 <configration> 中添加:<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/cloud/hadoop_space/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/cloud/hadoop_space/dfs/data</value>
<description>Determines where on the local
filesystem an DFS data node should store its blocks.
If this is a comma-delimited list of directories,
then data will be stored in all named
Directories, typically on different devices.
Directories that do not exist are ignored.
</description>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
注:这里的dfs.replication是数据的备份数,现在只有一台datanode,所以为1,如果有多台的时候可以给适当的值,默认是3。
5.6修改slaves文件
将slaves文件中的localhost改为slave
5.7 拷贝 hadoop2.2.0 整个文件夹到 slave 中
(这时候应该不需要输入slave的密码就可以远程拷贝)
5.8在slave上配置hadoop环境变量、创建/home/hadoop/cloud/tmp/hadoop2.2.0、/hadoop和/opt权限
5.9 在 master 上面格式化一下 HDFS
当看到
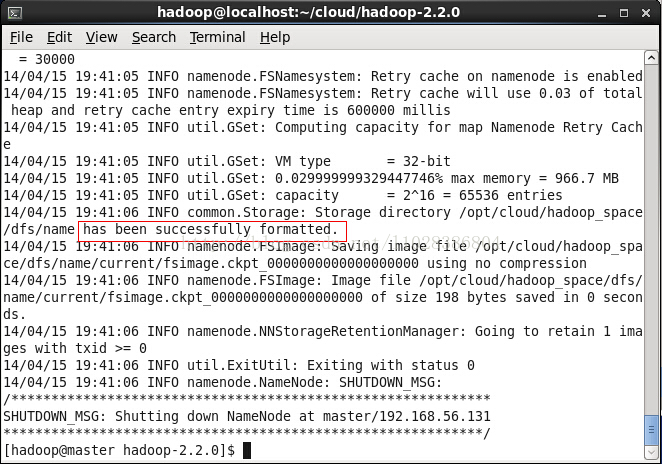
就成功了!
八、测试
启动:
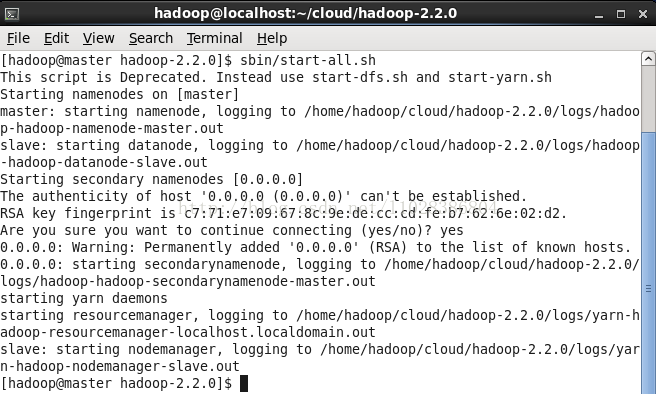
测试1:
查看运行的进程,但是经常出现下面的情况,度娘说什么跟jdk路径有关什么的,我重启了一下虚拟机就好了

master上

slave上
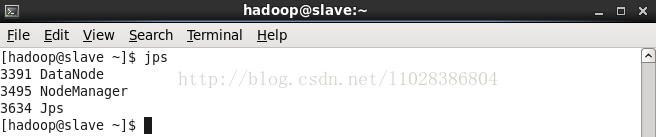
测试2:
使用浏览器查看集群状态
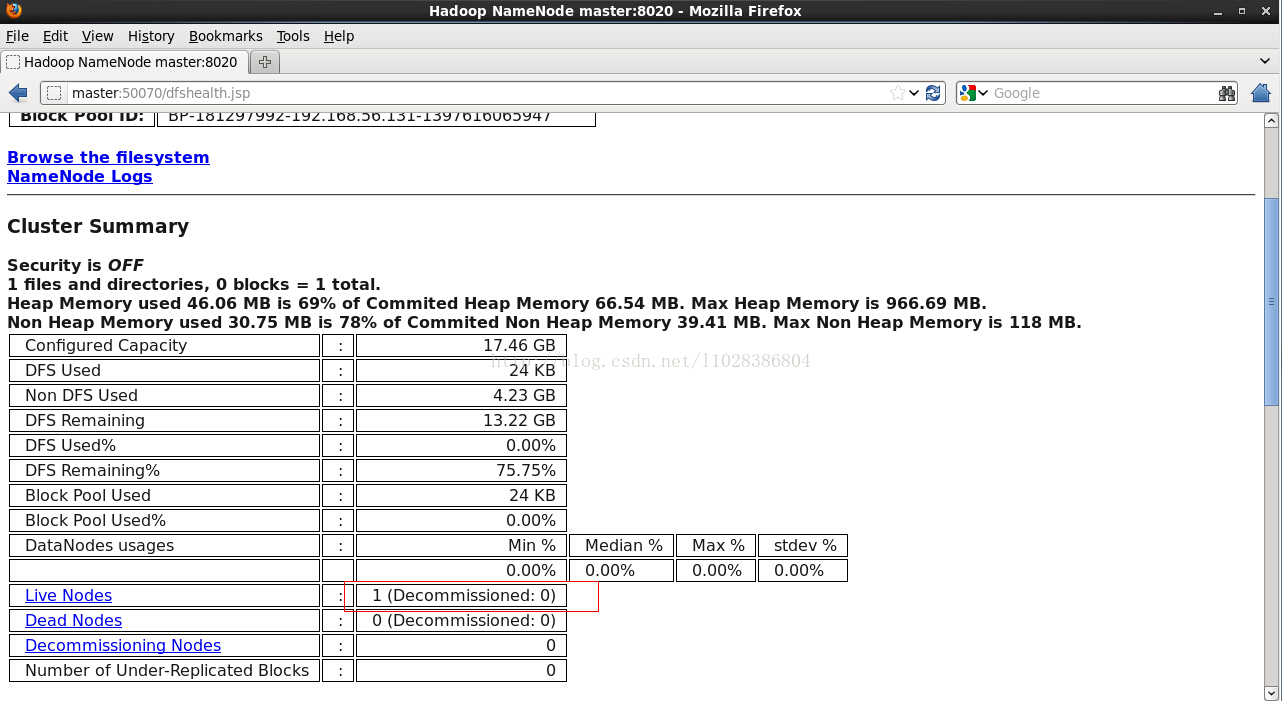
可以看到有一个活的节点;
Browse the filesystem:
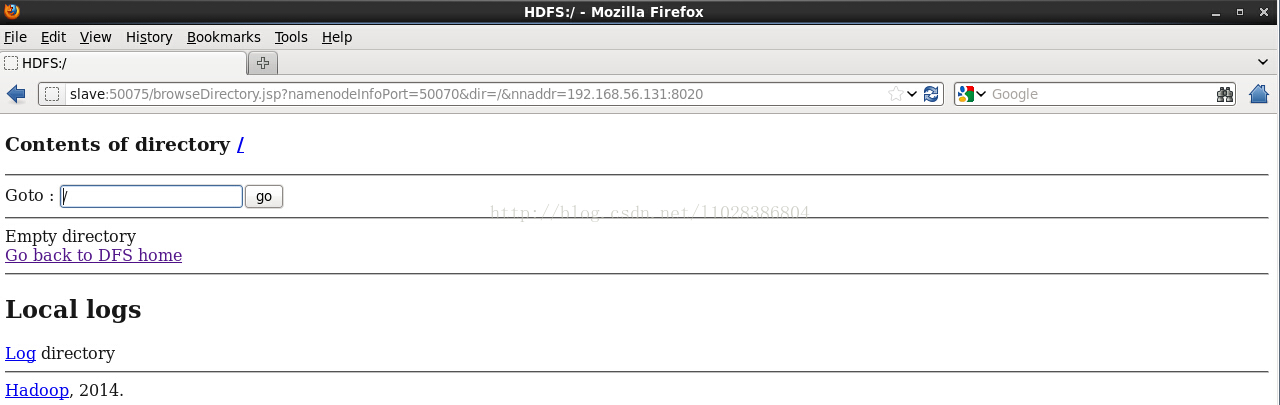
测试3:
运行wordcount程序
先随意上传一个文件到HDFS


查看结果
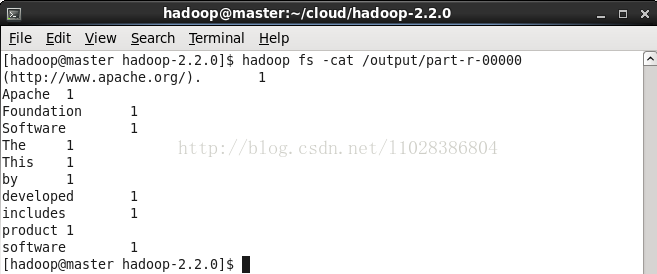
















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











