







 本文详细介绍了Hadoop2.7.2在Ubuntu14.04操作系统上的安装和配置步骤,包括JDK的设置、SSH的安装以及Hadoop的配置和启动。在配置完成后,通过`jps`命令检查进程状态,确认Hadoop成功启动。
本文详细介绍了Hadoop2.7.2在Ubuntu14.04操作系统上的安装和配置步骤,包括JDK的设置、SSH的安装以及Hadoop的配置和启动。在配置完成后,通过`jps`命令检查进程状态,确认Hadoop成功启动。
林炳文Evankaka原创作品。转载请注明出处http://blog.csdn.net/evankaka
摘要:本文主要讲了Hadoop2.7.2在Ubuntu14.04上的安装与配置过程
一、JDK
1、安装JDK比较简单,不懂可以看这里: http://blog.csdn.net/evankaka/article/details/50463782
2、设置环境变量
gedit
环境变量分为用户变量和系统变量。
用户变量配置文件:~/.bashrc(在当前用户主目录下的隐藏文件,可以通过`ls -a`查看到)
系统环境配置文件:/etc/profile
用户变量和系统变量的配置方法一样,本文以配置用户变量为例。
编辑配置文件.bashrc:
vi .bashrc
在文件末尾追加:#set java environment
export JAVA_HOME=/usr/java/jdk/jdk1.8.0_65
export JRE_HOME=/usr/java/jdk/jdk1.8.0_65/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH3环境变量生效
source ~/.bashrc4验证
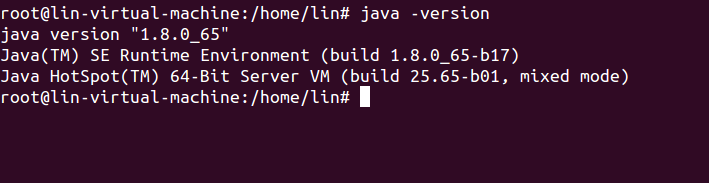
验证Java是否安装成功。
java -version
二、安装SSH
由于Hadoop用ssh通信,作为一个安全通信协议,使用时需要密码,因此我们要设置成免密码登录(除非你的手真的非常痒,每次都喜欢输入密码,一两台机器还可以,要是几十上百台呢?没密码担心安全问题?自己去看openssh吧,记得要弄懂里面的加密算法哦。)首先在安装服务
sudo apt-get 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









