







我的爬虫以京东女装的外套为例进行,抓取更大的分类可以再进行修改。
scrapy的安装,建工程什么的我就不说了,工程结构如图
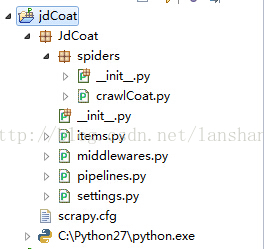
crawlCoat内容如下:
# -*- coding: utf-8 -*-
from JdCoat.items import JdcoatItem
from scrapy.http import Request
from scrapy.selector import Selector
from scrapy.contrib.linkextractors.lxmlhtml import LxmlLinkExtractor
from scrapy.contrib.spiders import Rule, CrawlSpider
class JdCrawl(CrawlSpider):
name = "crawlcoat"
allowed_domins = ["jd.com"]
start_urls = [
"http://list.jd.com/list.html?cat=1315,1343,9712",#外套
# "http://list.jd.com/list.html?cat=1315,1343,9717"#长裤
]
#这里主要是抽取产品的url和下一页的url,并分别调用各自的回调函数,默认调用parse,也就是直接请求网页不做相关处理
#还有一个方法是,不写rule,直接重写parse方法,方法里分别获取产品url和下一页url,也很好用
rules = [
Rule(LxmlLinkExtractor(allow="/\d{10}.html"), callback="parseItemurl",),
Rule(LxmlLinkExtractor(allow=("/list.html\?cat=1315%2C1343%2C9712&page=\d+&JL=6_0_0"), restrict_xpaths=("//a[@class='next']")),
follow=True)
] def parseItemurl(self,response):
itemurl = response.xpath("//div[@id='choose-color']/div[2]/div")
i = 1
for url in itemurl.xpath("a/@href").extract():
item = JdcoatItem()
item['color'] = response.xpath("//div[@id='choose-color'] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1302
1302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









