







最近看opencv中adaboost训练强分类器源码,记录下自己对adaboost训练强分类器的原理理解。
adaboost训练强分类器的基本流程:
1、初始化训练样本的类别与权重分布。
2、迭代循环训练弱分类器。
3、将每次循环训练成的弱分类器与已经存在的弱分类器组成的强分类器。
4、根据当前强分类器计算正样本置信度,根据传入参数minhitrate来取得强分类器阈值。
5、用当前强分类器与上步计算得到阈值,分类负样本,如果分类的最大检率小于maxfalsealarm。跳出循环,强分类器训练完成。
下面结合一般的adaboost的算法原理、opencv源码、记录下我对adaboost的算法流程的详细理解:
给定一个训练数据集 ,其中
属于标记样本是正样本还是负样本的标记集合{-1,+1},一般-1表示负样本,+1表示正样本。在人脸分类器的训练中,
是计算出来的正样本人脸图片与负样本非人脸图片的某个haar特征的集合。Adaboost的目的就是从训练数据集T中学习一系列弱分类器(特征表述+特征阈值),然后将这些弱分类器组合成一个强分类器(弱分类器+阈值)来尽可能准确的分类xi以达到能够分类一个新的样本
是正样本还是负样本。
在opencv中函数训练强分类器的函数是:icvCreateCARTStageClassifier。这里要特别说明下,在opencv中为训练强分类器提供了四种方法分别是Discrete AdaBoost(DAB)、Real AdaBoost(RAB)、Logit Boost(LB)和Gentle AdaBoost(GAB)算法。我们通常使用的较多的都是GAB训练算法,也是最简单的,这里是几种训练算法的区别介绍::http://www.cnblogs.com/jcchen1987/p/4581651.html
这里就DAB算法逻辑做一个介绍::::::::::::::::::
1、首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值:1/N。
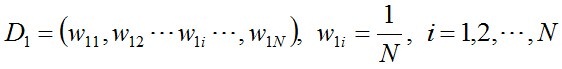
opencv源码是在函数cvBooWstStartTraining中对训练的样本数据集进行权重的初始化,以及标识每个样本来初始化数据集
2、进入循环,进行多轮迭代,把每次迭代记做m
A、通过函数 cvTrimWeights来剔除小权值的样本:对实际存在的样本按权重的大小排序,找到权重高于总权重的weightfraction倍的样本保留下来,用来训练接下来的弱分类器。
B、使用前面一步保留下来的权值分布为Dm样本集学习训练,得到一个弱分类器,在函数cvCreateCARTClassifier中实现,记公式如下:
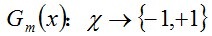
具体如何训练弱分类,见前面几个博客笔记:cvCreateCARTClassifier
C、用上步训练出来的弱分类器Gm(x)计算每个样本的分类置信度(具体调用的是函数icvEvalCARTHaarClassifier这里源码中用的是函数指针有点难找到,具体可以看下面我贴出的代码中的注释),将计算出来的每个样本的置信度传入cvBoostNextWeakClassifier函数计算该弱分类器Gm(X)在数据集上的分类误差em,这里四种不同的分类器训练方法有不同的计算方式,其中DAB的计算方法如下,在函数icvBoostNextWeakClassifierDAB中实现:
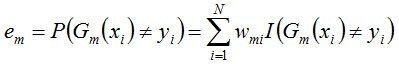
D、在上述函数icvBoostNextWeakClassifierDAB中紧接着用公式
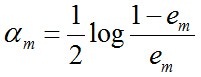
计算了当前弱分类器Gm(X)在当前强分类器中的重要程序,这个公式意味着分类误差率越小的弱分类器在强分类器中的权重越高,作用越大。
E、在函数icvBoostNextWeakClassifierDAB中接着遍历所有样本,更新训练样本的数据集的权值分布得到Dm+1用于下轮迭代来训练弱分类器,公式如下:
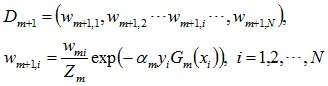
其中:Zm是一个规一化因子:
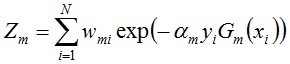
通俗的说就是:遍历每个样本更新其权重Wm+1,i=Wm,i*exp(…) , 同时累加每个样本计算得到的权重Wm+1,i得到Zm,然后规一化下。通过公式可以看出当Gm(xi)分类这个样本正确时,则计算得到的Wm+1,i比Wm,i大,反之,Wm+1,i比Wm,i小,这样就实现了将本次分类正确的样本权值减小,本次分类错误的样本权值增大,这样在下次训练弱分类器里更多的聚焦于本次被分错的样本。
F、从函数icvBoostNextWeakClassifierDAB返回后,得到了当前弱分类器的权重。将该弱分类器以如下公式的方式加入到当前强分类器中:
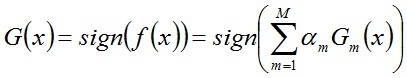
G、紧接着,在函数icvCreateCARTStageClassifier中分开处理正负样本,遍历所有正样本,用当前强分类器中已经训练出来的弱分类器来计算每个正样本的置信度,累加得到置信度累加和,将这些每个样本的置信度累加和排序,根据minhitrate来计算当前强分类器的阈值threshold。
H、再遍历所有负样本,用当前强分类器中已经训练出来的弱分类器来计算每个负样本的置信度累加和,再用前面计算得到的threshold来判断每个负样本的类别,统计负样本的分类总数,得到负样本的误检率falsealarm,如果误检率小于输入的参数maxfalsealarm,则跳出迭代循环,当前强分类器训练完成!!!!
下面上源码和注释(结合代码与原理更容易理解)::::
static
CvIntHaarClassifier* icvCreateCARTStageClassifier( CvHaarTrainingData* data, // 全部训练样本
CvMat* sampleIdx, // 实际训练样本序列
CvIntHaarFeatures* haarFeatures,// 全部HAAR特征
float minhitrate,// 最小正检率(用于确定强分类器阈值)
float maxfalsealarm,// 最大误检率(用于确定是否收敛)
int symmetric,// HAAR是否对称
float weightfraction,// 样本剔除比例(用于剔除小权值样本)
int numsplits,// 每个弱分类器特征个数(一般为1)
CvBoostType boosttype,// adaboost类型
CvStumpError stumperror,// Discrete AdaBoost中的阈值计算方式
int maxsplits ) // 弱分类器最大个数
{
#ifdef CV_COL_ARRANGEMENT
int flags = CV_COL_SAMPLE;
#else
int flags = CV_ROW_SAMPLE;
#endif
CvStageHaarClassifier* stage = NULL;// 强分类器
CvBoostTrainer* trainer;// 临时训练器,用于更新 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









