






1.AdaBoost算法
1.1AdaBoost算法基本原理
AdaBoost,全称为Adaptive Boosting(自适应增强),是一种基于 boosting 策略的集成学习方法。它由 Yoav Freund 和 Robert Schapire 在 1997 年提出,旨在通过结合多个弱分类器的决策来构建一个强分类器。AdaBoost的关键思想是针对同一训练集训练不同的分类器,然后把这些分类器组合起来,以提高整体性能。AdaBoost算法的核心是在每一轮迭代中改变训练样本的权重,使得前一个分类器错误分类的样本在后续的分类器中获得更高的权重。通常,AdaBoost使用决策树作为弱学习器,尤其是深度为1的决策树(即决策树桩)。
1.2弱分类器决策树的工作原理
决策树是一种树形结构算法,用于分类和回归任务,其中每个内部节点代表一个属性上的决策规则,每个分支代表该规则的一个结果,而每个叶节点则表示一个类别或回归预测值。构建决策树的过程从数据集的根节点开始,通过递归地选择最佳属性来分割数据,直到满足某个预设的停止条件,如达到最大深度、节点下的数据量小于阈值或数据无法进一步有效分割。选择分割属性时,通常依据信息增益、增益率或基尼不纯度等标准,以确定哪个属性在分割时能最大程度增加节点的“纯度”或减少不确定性。尽管决策树易于理解和实施,且能处理各种数据类型,但它们也容易过拟合,且对数据的小变动可能敏感,导致生成的树结构有较大差异。不过在通过AdaBoost算法的加权多数投票机制,结合多个这样的决策树桩可以达到很强的预测性能。
决策树模型实例流程图
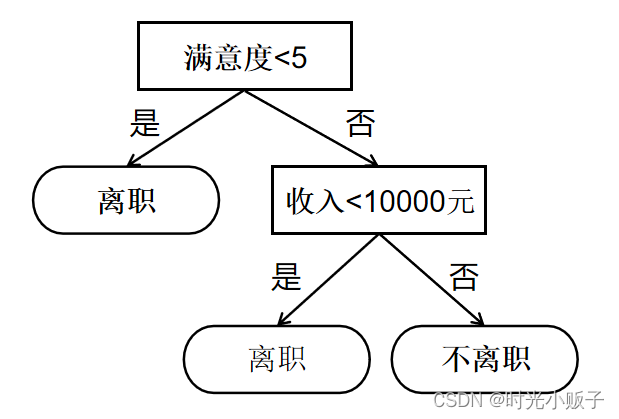
上图为一个简单的决策树模型实例,正方形代表判断模块,椭圆代表终止模块,表示已经得出结论,可以终止运行,左右箭头叫做分支。
本实验的Adaboost弱分类器——单层决策树模型实例流程图
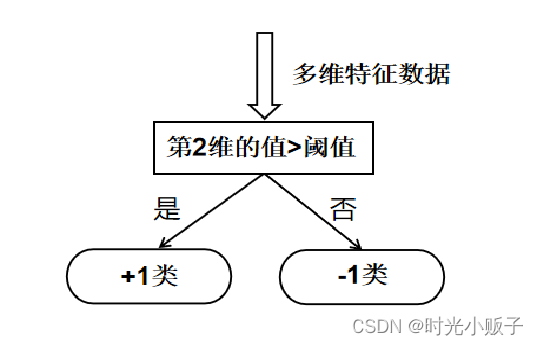
上图为Adaboost算法所选的弱分类器单层决策树,单层决策树只有一个决策点(与CART树类似),通过阈值将数据二分。
2.AdaBoost算法工作流程
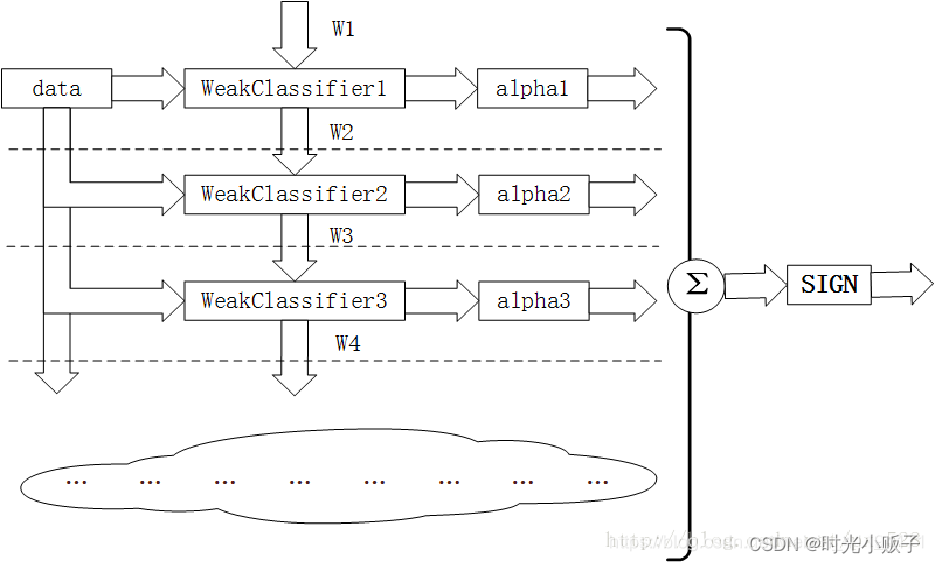
上图是展示了Adaboost算法的基本原理,通过将多个弱分类器结合到一起形成一个强大的集成模型,以提高整体性能。
具体说来,整个Adaboost 迭代算法工作流程可以分为3步。
1、初始化训练数据权值。 如果有N个样本,初始化训练数据(每个样本)的权值分布。每一个训练样本,初始化时赋予同样的权值w=1/N。
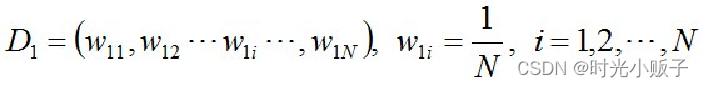 D1表示,第一次迭代每个样本的权值。W11表示,第1次迭代时的第一个样本的权值。N为样本总数。
D1表示,第一次迭代每个样本的权值。W11表示,第1次迭代时的第一个样本的权值。N为样本总数。
2、训练弱分类器。
a)使用具有权值分布Dm(m=1,2,3…N)的训练样本集进行学习,得到新的弱分类器。 ,该式子表示,第m次迭代时的弱分类器,将样本x要么分类成-1,要么分类成1。
b) 计算Gm(x)在训练数据集上的分类误差率,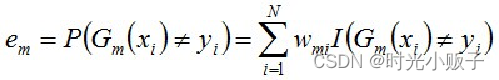 由上述式子可知,Gm(x)在训练数据集上的误差率em就是被Gm(x)误分类样本的权值之和。
由上述式子可知,Gm(x)在训练数据集上的误差率em就是被Gm(x)误分类样本的权值之和。
c) 计算Gm(x)的系数alpha,alpha m表示弱分类器权重,e表示数据误差率 ,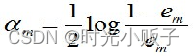 上述式子可知,em <= 1/2时,am >= 0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。
上述式子可知,em <= 1/2时,am >= 0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。
d)更新训练数据权值(目的:得到样本的新的权值分布),用于下一轮迭代, 
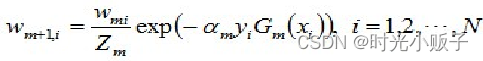 使得误分样本的权值增大,正确分类样本的权值减小。因此AdaBoost方法能“重点关注”或“聚焦于”那些较难分对的样本上其中,Zm是规范化因子,使得Dm+1成为一个概率分布:
使得误分样本的权值增大,正确分类样本的权值减小。因此AdaBoost方法能“重点关注”或“聚焦于”那些较难分对的样本上其中,Zm是规范化因子,使得Dm+1成为一个概率分布: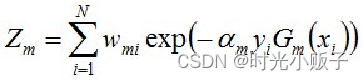
3、组合弱分类器 首先定义 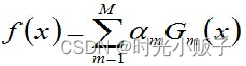 ,然后,加个sign函数,该函数用于求数值的正负。数值大于0,为1。小于0,为-1。等于0,为0。得到最终的强分类器G(x),
,然后,加个sign函数,该函数用于求数值的正负。数值大于0,为1。小于0,为-1。等于0,为0。得到最终的强分类器G(x),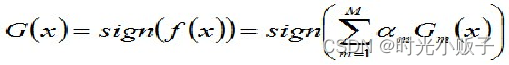 ,其中M是迭代次数,αm是第m个分类器的权重,Gm(x)是第m个分类器对样x的预测。
,其中M是迭代次数,αm是第m个分类器的权重,Gm(x)是第m个分类器对样x的预测。
3.Wine数据集
Wine数据集是一个常用的机器学习数据集,包含了来自意大利三个不同葡萄酒区域的葡萄酒的化学成分数据。Wine数据集含有178个样本和13个特征变量,每个样本都对应一个葡萄酒样本,并且标注了这个样本属于哪一种葡萄酒类别。在原始的数据集中,葡萄酒共分为三种类型,分别为类别1:Barolo、类别2:Grignolino、类别3:Barbera。Wine数据集因其小而清晰的结构,可以作为一个理想的数据集,因此它广泛用于多种机器学习方法的验证,本实验中利用它来验证基于随机森林的AdaBoost分类算法的测试。13个特征变量分别为酒精(Alcohol)、苹果酸(Malic acid)、灰(Ash)、灰的碱性(Alcalinity of ash)、镁(Magnesium)、总酚类(Total phenols)、类黄酮(Flavanoids)、非黄烷类酚类(Nonflavanoid phenols)、原花青素(Proanthocyanins)、颜色强度(Color intensity)、色调(Hue)、稀释酒的OD280/OD315比值(OD280/OD315 of diluted wines)、脯氨酸(Proline)。
4.实践
4.1导入Wine数据集及查看数据集相关信息
from sklearn.datasets import load_wine
# 加载Wine数据集
data = load_wine()
# 查看特征变量
print("Feature Variables:")
print(data.feature_names)
# 分析数据集样本总数
print("Total number of samples:", data.data.shape[0])
# 分析特征变量总数
print("Total number of feature variables:", data.data.shape[1])
# 查看数据集前5条数据
print("First 5 data samples:")
for i in range(5):
print("Sample", i+1, ":", data.data[i])直接从python的scikit-learn 库导入Wine 数据集,加载数据集,同时查看数据集的前五条数据
4.2划分数据集及相关预处理操作
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 加载Wine数据集
data = load_wine()
# 查看特征变量
print("Feature Variables:")
print(data.feature_names)
# 分析数据集样本总数
print("Total number of samples:", data.data.shape[0])
# 分析特征变量总数
print("Total number of feature variables:", data.data.shape[1])
# 查看数据集前5条数据
print("First 5 data samples:")
for i in range(5):
print("Sample", i+1, ":", data.data[i])
X = data.data
y = data.target
# 数据预处理:标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
4.3选择决策树作为基础分类器并进行模型训练与测试
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
# 加载Wine数据集
data = load_wine()
# 查看特征变量
print("Feature Variables:")
print(data.feature_names)
# 分析数据集样本总数
print("Total number of samples:", data.data.shape[0])
# 分析特征变量总数
print("Total number of feature variables:", data.data.shape[1])
# 查看数据集前5条数据
print("First 5 data samples:")
for i in range(5):
print("Sample", i+1, ":", data.data[i])
X = data.data
y = data.target
# 数据预处理:标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 实例化AdaBoostClassifier
# 使用决策树作为基础分类器
base_estimator = DecisionTreeClassifier(max_depth=1)
ada_clf = AdaBoostClassifier(base_estimator=base_estimator, n_estimators=50, learning_rate=1.0, random_state=42)
# 训练模型
ada_clf.fit(X_train, y_train)
# 预测测试集
y_pred = ada_clf.predict(X_test)n_estimators=50,训练50个弱分类器
4.5模型评估
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Classification Report:")
print(classification_report(y_test, y_pred))
# 计算混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
# 可视化混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt="d", cmap="Blues", xticklabels=data.target_names, yticklabels=data.target_names)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Confusion Matrix')
plt.show()可视化结果
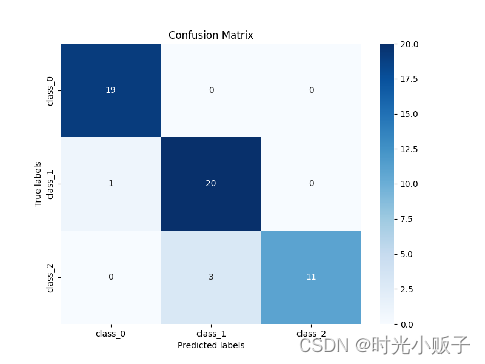
为了对模型分类性能展示更详尽的视角,输出了关于验证集的混淆矩阵,在混淆矩阵中,行表示真实的类别,列表示预测的类别。由图可见模型对Barolo(Class 0)的识别准确率非常高,没有发生任何误分类,对Grignolino (Class1)预测也相当准确,只有一个样本被误分类,对Barbera(Class 2)的分类中有一定的误差,3个样本被错误地归类为Grignolino(Class 1),这可能表明在特征上Class 2和Class 1之间可能有一些相似性,导致模型在这两个类别之间的区分上不是非常清晰。

50个弱分类器的决策树桩 (Decision Stump)
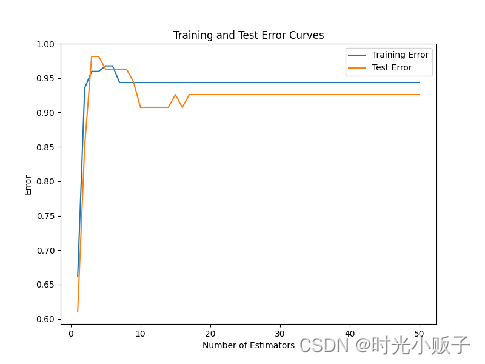
训练集和测试集的误差曲线图
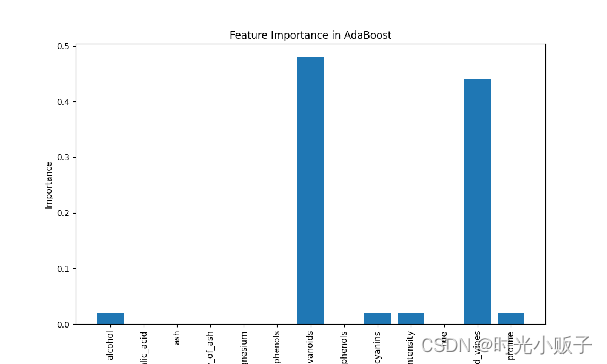
特征重要性图
5.完整代码展示
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier, plot_tree
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg') # 或 'Agg' 如果在非交互式环境中运行
# 加载Wine数据集
data = load_wine()
# 查看特征变量
print("Feature Variables:")
print(data.feature_names)
# 分析数据集样本总数
print("Total number of samples:", data.data.shape[0])
# 分析特征变量总数
print("Total number of feature variables:", data.data.shape[1])
# 查看数据集前5条数据
print("First 5 data samples:")
for i in range(5):
print("Sample", i+1, ":", data.data[i])
X = data.data
y = data.target
# # 将数据集转换为 DataFrame 并保存为 CSV 文件
# df = pd.DataFrame(data=X, columns=data.feature_names)
# df['target'] = y
# df.to_csv(r'C:\Users\xiaofanzi\Desktop\xingpas\wine_dataset.csv', index=False)
# print("Wine 数据集已保存为 wine_dataset.csv")
# 数据预处理:标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 实例化AdaBoostClassifier
# 使用决策树作为基础分类器
base_estimator = DecisionTreeClassifier(max_depth=1)
#ada_clf = AdaBoostClassifier(base_estimator=base_estimator, n_estimators=50, learning_rate=1.0, random_state=42)
ada_clf = AdaBoostClassifier(estimator=base_estimator, n_estimators=50, learning_rate=1.0, random_state=42)
# 训练模型
ada_clf.fit(X_train, y_train)
# 预测测试集
y_pred = ada_clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Classification Report:")
print(classification_report(y_test, y_pred))
# 计算混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
# 可视化混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt="d", cmap="Blues", xticklabels=data.target_names, yticklabels=data.target_names)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Confusion Matrix')
plt.show()
# 绘制决策树桩 (Decision Stump) 图
plt.figure(figsize=(10, 6))
for i, estimator in enumerate(ada_clf.estimators_):
plt.subplot(5, 10, i + 1)
plot_tree(estimator, filled=True)
plt.title(f"Stump {i+1}")
plt.suptitle("Decision Stumps in AdaBoost")
plt.show()
# # 绘制训练/测试误差曲线 (Training/Test Error Curve)
# train_scores = ada_clf.train_score_
# test_scores = ada_clf.score(X_test, y_test)
train_scores = list(ada_clf.staged_score(X_train, y_train))
test_scores = list(ada_clf.staged_score(X_test, y_test))
plt.figure(figsize=(8, 6))
plt.plot(range(1, len(train_scores) + 1), train_scores, label='Training Error')
plt.plot(range(1, len(test_scores) + 1), test_scores, label='Test Error')
plt.xlabel('Number of Estimators')
plt.ylabel('Error')
plt.title('Training and Test Error Curves')
plt.legend()
plt.show()
# 绘制特征重要性 (Feature Importance) 图
feature_importances = ada_clf.feature_importances_
plt.figure(figsize=(10, 6))
plt.bar(range(len(feature_importances)), feature_importances)
plt.xticks(range(len(feature_importances)), data.feature_names, rotation=90)
plt.xlabel('Features')
plt.ylabel('Importance')
plt.title('Feature Importance in AdaBoost')
plt.show()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









