







字符(char)与字节(byte)的语义差别
python中要计算str包含多少个字符,可以用len()函数:
$ len('ABC')
3
$ len('中文')
2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
$ len(b'ABC')
3
$ len(b'\xe4\xb8\xad\xe6\x96\x87')
6
$ len('中文'.encode('utf-8'))
6
可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,常遇到char和bytes的互相转换。为了避免乱码,应当始终坚持使用UTF-8编码对str和bytes进行转换。
ASCII 与UTF-8
ASCII
美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一共规定了128个字符的编码,比如空格”SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
The first 32 of ASCII character table are non-printing characters.
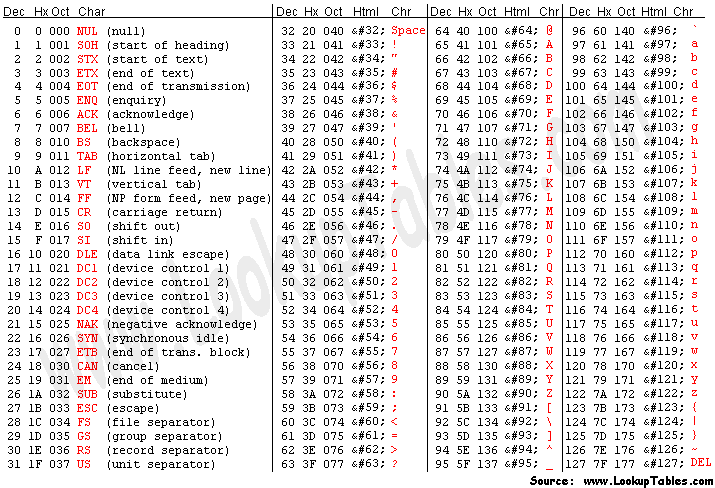
Extended ASCII Codes
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种Unicode的实现方式。UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 (十六进制) | UTF-8编码方式(二进制)
——————–+—————-+—————————–
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
以汉字”严”为例,演示如何实现UTF-8编码。
已知”严”的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此”严”的UTF-8编码需要三个字节,即格式是”1110xxxx 10xxxxxx 10xxxxxx”。然后,从”严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,”严”的UTF-8编码是”11100100 10111000 10100101”,转换成十六进制就是E4B8A5。
以UTF-8编码方式计算字符串中的字符数
int CalcUTF8Chars(const std::string& S)
{
int Count = 0;
if (S.empty())
return 0;
//S.length(),returns the length of the string, in terms of bytes.
for (size_t i = 0; i != S.length(); i++){
if ((S[i] & 0xC0) != 0x80) {
Count++;
}
}
return Count;
}
Calculate the number of UTF8 characters ,这个函数在含有Emogi(字符表情)的字符串,存入数组等情况有用处。















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









