









概述:
通过前面两篇博客的学习,我们学习了Hadoop的伪分布式部署和完全分布式部署。这一篇文章就来介绍一下Hadoop的第一个程序WordCount。以及在运行代码的过程中遇到的问题。
笔者开发环境:
Linux: CentOS 6.6(Final) x64
Windows: Win7 64位
JDK: java version "1.7.0_75"
OpenJDK Runtime Environment (rhel-2.5.4.0.el6_6-x86_64 u75-b13)
OpenJDK 64-Bit Server VM (build 24.75-b04, mixed mode)
SSH: OpenSSH_5.3p1, OpenSSL 1.0.1e-fips 11 Feb 2013
Hadoop: hadoop-1.2.1
Eclipse: Release 4.2.0
这边使用Linux和Window两个系统来开发的目的在于,我的Cygwin还没安装好。。。而Linux上的Hadoop安装和部署很方便,又感觉Winows上Eclipse比Linux上的Eclipse用着舒服。
下面的代码和一些遇到的问题,以及对于这上问题的解决方案。
主代码(WordCount.java):
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount1.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行过程及说明:
1.将我们在Windows上开发的Java程序打成jar包,上传到Linux上。
2.执行命令java -jar wordcount1.jar /home/moon/coding/tmp/wordcount /home/moon/coding/tmp/wordres

3.正常运行的情况下,会出现如下输出:
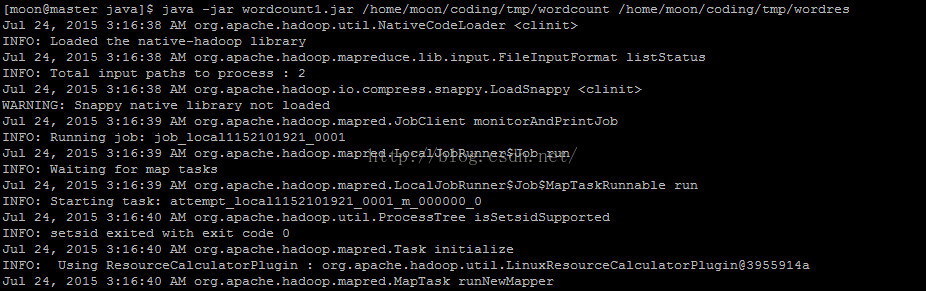
4.进行输出目录,查看结果:
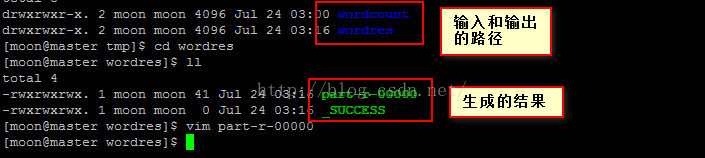
5.输出文件的结果信息:
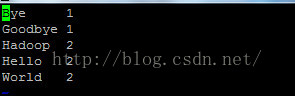
遇到的问题:
1.各种ClassNotFound异常
这里对于ClassNotFound的异常比较好解决。只要导入一些相应的jar包就可以了。我在Eclipse中导入的jar如下:

这些在你下载的Hadoop-x.x.x-bin的文件夹中都是有的。
2.Unable to load native-hadoop library for your platform
经过一各种ClassNotFound异常的解决之后,出现了上面的这个异常。这个异常不是缺少jar包引起的。而是我们的系统环境没有把我们的jar和之前部署的Hadoop目录结合起来,只要在系统中配置一下hadoop的本地库的实际路径即可。如下:Hadoop本地库的实际路径:$HADOOP_HOME/lib/native/Linux-amd64-64/
解决方法一:
在启动JVM时,在java命令中添加java.library.path属性即可,如下:
-Djava.library.path=$HADOOP_HOME/lib/native/Linux-amd64-64/
解决方法二:
使用LD_LIBRARY_PATH系统变量也能解决此问题,如下:
export HADOOP_HOME = /home/moon/hadoop-1.2.1
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/Linux-amd64-64/















 2662
2662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









