







一、线性回归
用线性回归找到最佳拟合直线
回归的目的是预测数值型数据,根据输入写出一个目标值的计算公式,这个公式就是回归方程(regression equation),变量前的系数(比如一元一次方程)称为回归系数(regression weights)。求这些回归系数的过程就是回归。
假设输入数据存放在矩阵 X 中,回归系数存放在向量 w 中,那么对于数据 X1 的预测结果可以用 Y1=XT1w 得出。我们需要找到使误差最小的 w ,但是如果使用误差之间的累加的话,那么正负误差将会抵消,起不到效果,所以采用平方误差。如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这部分数据是由tap分隔,并且最后一个值是目标值。接下来计算回归系数:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
该函数首先读入
x
和
y
数组,然后将它们转换成矩阵,之后根据公式计算平方误差,注意,需要对
XTX
求逆,此时需要判断它的行列式是否为0,行列式等于0的矩阵无法求逆,可以直接使用linalg.det() 来计算行列式。好了,我们来看看效果,首先读入数据:
- 1
- 1
我们先看看前两条数据:
- 1
- 2
- 1
- 2
第一个值总是等于1.0,也就是
x0
,假定偏移量是一个常数,第二个值是
x1
。
现在看看计算回归系数函数效果:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
现在得到了回归系数,那么我们可以通过回归方程进行预测yHat:
- 1
- 2
- 3
- 1
- 2
- 3
为方便观察,我们画出数据集散点图:
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
现在绘制最佳拟合直线,那么需要画出预测值yHat,如果直线上数据点次序混乱,绘图时将会出现问题,所以要将点按照升序排序:
- 1
- 2
- 3
- 4
- 5

- 1
- 2
- 3
- 4
- 5
我们来看看效果:
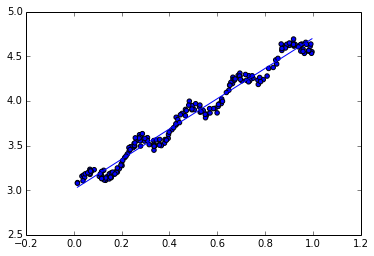
最佳拟合直线方法将数据视为直线进行建模,但图中的数据集似乎还有更好的拟合方式。
二、局部线性回归
主要看k的选择,因为每个k值下算出的回归系数值已满足最小均方误差了。
线性回归可能出现欠拟合的现象,如上图所示,因为它求的是具有最小均方误差的无偏差估计。所以有些方法允许在估计中引入一些偏差,从而降低预测的均方误差。其中一个方法就是使用局部加权线性回归(Locally Weighted Linear Regression,LWLR),我们给待测点附近的每个点赋予一定的权重,是用此方法解出的回归系数如下:
theta
=(XTWX)−1XTWy
LWLR使用“核”来对附近的点赋予更高的权重,核的类型可以自由选择,最常用的核就是高斯核,高斯核对应的权重如下:
import numpy as np
import matplotlib.pyplot as plt
def loadDataSet(fileName): #general function to parse tab -delimited floats
numFeat = len(open(fileName).readline().split('\t')) - 1 #get number of fields
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)#xij,i为特征,j为样本
labelMat.append(float(curLine[-1]))
return dataMat,labelMat
#局部加权回归
def lwlr(testPoint,xArr,yArr,k=1.0):#
xMat = np.mat(xArr); yMat = np.mat(yArr).T
m = np.shape(xMat)[0]
weights = np.mat(np.eye((m)))#创建对角矩阵:eye()返回一个对角线元素为1,其他元素为0的二维数组。 以给每个数据点赋予权重
for j in range(m): #next 2 lines create weights matrix
diffMat = testPoint - xMat[j,:] #
weights[j,j] = np.exp(diffMat*diffMat.T/(-2.0*k**2))
xTx = xMat.T * (weights * xMat)
if np.linalg.det(xTx) == 0.0:
print("This matrix is singular, cannot do inverse")
return
ws = xTx.I * (xMat.T * (weights * yMat))
return testPoint * ws
def lwlrTest(testArr,xArr,yArr,k=1.0): #测试lwlr函数:loops over all the data points and applies lwlr to each one
m = np.shape(testArr)[0]
yHat = np.zeros(m)
for i in range(m):
yHat[i] = lwlr(testArr[i],xArr,yArr,k)
return yHat
def lwlrTestPlot(xArr,yArr,k=1.0): #same thing as lwlrTest except it sorts X first
yHat = np.zeros(np.shape(yArr)) #easier for plotting
xCopy = np.mat(xArr)
xCopy.sort(0)
for i in range(np.shape(xArr)[0]):
yHat[i] = lwlr(xCopy[i],xArr,yArr,k)
return yHat,xCopy
def rssError(yArr,yHatArr): #yArr and yHatArr both need to be arrays
return ((yArr-yHatArr)**2).sum()
xArr,yArr=loadDataSet(r'C:\Users\qingmu\Desktop\数据组\收藏资料\machinelearninginaction\Ch08\新建文本文档.txt')
yHat=lwlrTest(xArr,xArr,yArr,0.1)
xMat=np.mat(xArr)rssError=
strInd=xMat[:,1].argsort(0)
xSort=xMat[strInd][:,0,:]
fig=plt.figure()
ax=fig.add_subplot(111)
ax.plot(xSort[:,1],yHat[strInd])
ax.scatter(xMat[:,1].flatten().A[0], np.mat(yArr).T.flatten().A[0], s = 2, c = 'red')
plt.show()
k=0.1

k=0.01
k=0.003


练习:
拟合交易指数和支付金额。
第一种情况:
xArr,yArr=loadDataSet(r'C:\Users\qingmu\Desktop\数据组\收藏资料\machinelearninginaction\Ch08\新建文本文档.txt')
yHat=lwlrTest(xArr,xArr,yArr,0.1)
xMat=np.mat(xArr)
strInd=xMat[:,0].argsort(0)
xSort=xMat[strInd][:,0,:]
fig=plt.figure()
ax=fig.add_subplot(111)
ax.plot(xSort[:,0],yHat[strInd])
ax.scatter(xMat[:,0].flatten().A[0], np.mat(yArr).T.flatten().A[0], s = 2, c = 'red')
plt.show()
k=0.1

k=0.01

k=0.003
















 2434
2434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









