







基础知识
G(V,E):变量关系图
V:顶点or节点,表示随机变量
E:边or弧
两个节点邻接:两个节点之间存在边,记为Xi
路径:若对每个i,都有Xi-1
几种概率图模型:
- 朴素贝叶斯分类器(NBs:Naive Bayes)
- 最大熵模型(MEM:Maximum Entropy Model)
- 隐马尔可夫模型(HMM:Hidden Markov Models)
- 最大熵马尔可夫模型(MEMM:Maximum Entropy Markov Model)
- 马尔可夫随机场(MRF:Markov Random Fields)
- 条件随机场(CRF:Conditional Random Fields)
1.NBs
贝叶斯定理
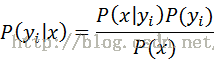
一般来说,x已给出,P(x)也是一个定值(虽然不知道准确的数据,但因为是恒值,可以忽略),只需关注分子P(x|yi)P(yi)。P(yi)是类别yi的先验概率,P(x|yi)是x对类别yi的条件概率。
贝叶斯定理说明了可以用先验概率P(yi)来估算后验概率P(x|yi)。
贝叶斯分类器
贝叶斯网络(Bayesian Network)
概率图示意
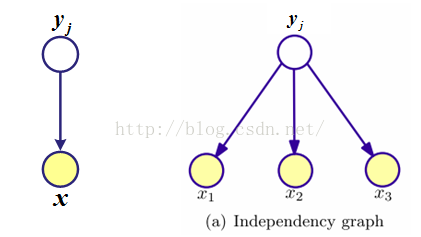
每个节点的条件概率分布表示为:P(当前节点|它的父节点)。
联合分布为: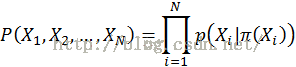
举例:
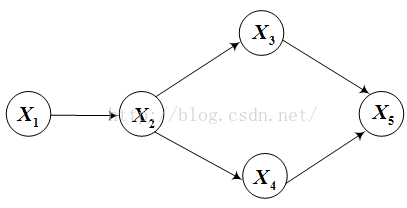
联合分布为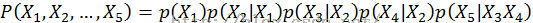
2.MEM
概率图示意
最大熵推导过程省略,直接给出最后的模型公式——指数形式
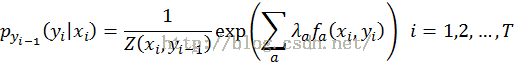
其中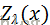 是归一化因子
是归一化因子
是归一化因子
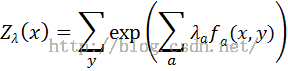
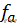 表示特征函数;
表示特征函数;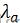 表示特征函数的权重
,可由训练样本估计得到,
大的非负数值表示了优先选择的特征,大的负值对应不太可能生的特征。
表示特征函数的权重
,可由训练样本估计得到,
大的非负数值表示了优先选择的特征,大的负值对应不太可能生的特征。
3.HMM
概率示意图
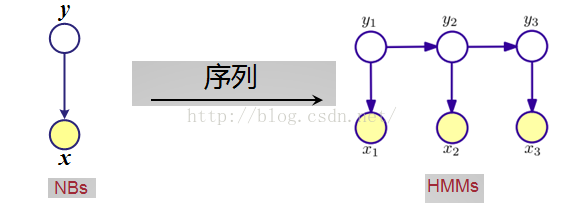
状态序列和观察序列的联合概率
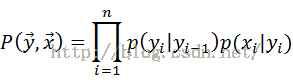
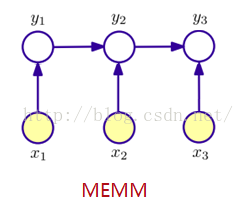
4.MEMM
概率图示意
状态yi
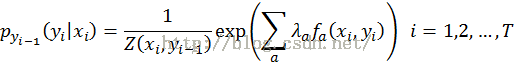
5.MRF
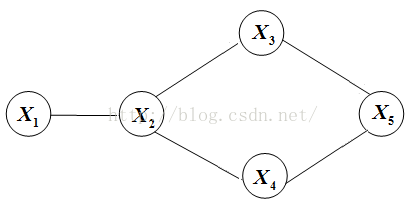

其中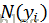 表示与yi有边相连的节点。
表示与yi有边相连的节点。
表示与yi有边相连的节点。
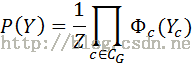
其中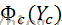 表示一个团(clique)Yc的势能,以上公式也可以具体写成
表示一个团(clique)Yc的势能,以上公式也可以具体写成
表示一个团(clique)Yc的势能,以上公式也可以具体写成
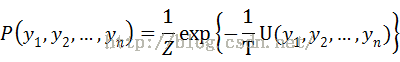
其中Z是归一化因子,是对分子的所有ys
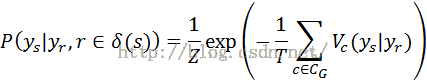
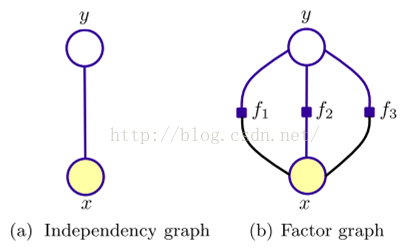
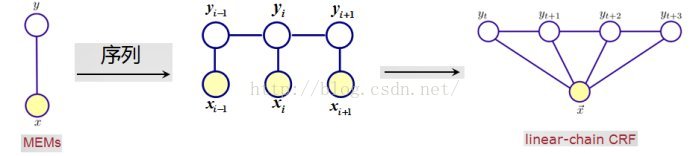
6.CRF
一阶链式CRF示意图(不同于隐马尔科夫链,条件随机场中的xi
令
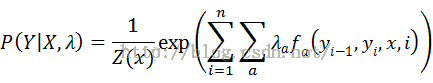
其中归一化因子
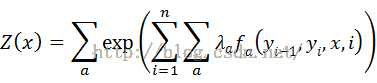
以上的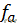 是状态函数
是状态函数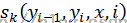 和转移函数
和转移函数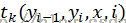 的统一表达形式。
的统一表达形式。
是状态函数和转移函数的统一表达形式。
几种比较
条件随机场和隐马尔科夫链的关系和比较
- 不同点:观察值xi不单纯地依赖于当前状态yi,可能还与前后状态有关;
- 相同点:条件随机场保留了状态序列的马尔科夫链属性——状态序列中的某一个状态只与之前的状态有关,而与其他状态无关。(比如句法分析中的句子成分)
MRF和CRF的关系和比较















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









