







 本文介绍了深度学习的基础,起源于神经网络,深入讲解了神经元的工作原理和激活函数的重要作用。激活函数如sigmoid、tanh、ReLU和Softplus用于引入非线性,解决线性函数在数据拟合上的局限性。此外,文章还探讨了目标函数、梯度下降法和反向传播算法在训练神经网络中的应用,以及深度学习中多层神经网络的挑战和解决方案。
本文介绍了深度学习的基础,起源于神经网络,深入讲解了神经元的工作原理和激活函数的重要作用。激活函数如sigmoid、tanh、ReLU和Softplus用于引入非线性,解决线性函数在数据拟合上的局限性。此外,文章还探讨了目标函数、梯度下降法和反向传播算法在训练神经网络中的应用,以及深度学习中多层神经网络的挑战和解决方案。
AI技术研究的兴起,伴随着两种最直观的思维技巧,即遗传算法与神经网络,这是对生物学研究最直观的技术抽象。深度学习的前身就是神经网络,这个80年代灵光乍现的技术,在那一波人工智能的大潮驱使下,带着人们对于未来AI时代的憧憬,迅速蔓延,一时风头无两,和今天深度学习的火热几乎如出一辙。
某乎友的观点给出了这两种技术的鲜明对比,如同麻汁与芝麻酱,换汤不换药,所谓深度在于把二两变成了三斤,给出的官方解释是深度学习只是依赖于大数据和更好的硬件,除此再无区别。
当然也有不同观点,但不管如何,这并不是我们要讨论的话题,只要捋清来龙去脉,请读者自己站队。
• 神经网络
生物学家对人体大脑研究发现,人脑存在860亿个神经元,复杂的神经元通过生物电驱动,实现消息的加工和处理,神经元是怎么处理信息的呢?通过神经元结构来进行说明:
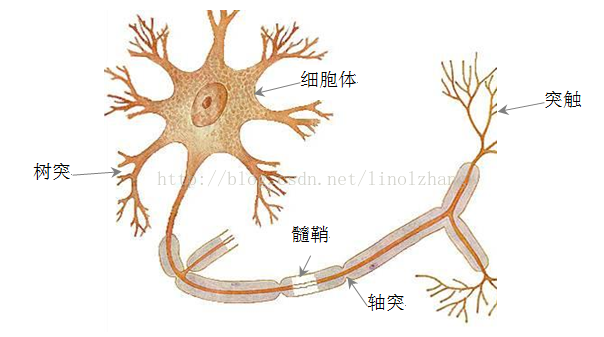
1)神经元作为信息处理的基本结构,主要构件是树突,细胞体和轴突,树突及细胞体接收外部刺激信号(由其他神经元传递);
2)轴突的作用过程是信号处理的过程,这个过程不完全是一种线性的处理过程,而是存在一种潜在的拟合方法,实现信号的放大或者抑制,也有可能出现信号消失,因此这种处理过程带有较大的随机性;
3)突触 实现信号的向下传递,当前面的信号处理后仍然存在时,将信号传递到相连接的神经元;
4)由于每个神经元对其他神经元产生的刺激或者抑制,最初的信号得到加工,这个加工过程非常复杂,路径也很深,有人把这个过程称为一个“图灵机”。
基于生物神经学的研究,神经网络的概念诞生,被抽象成数学符号,描述为以加权平均形式,而信号加工处理过程被简化为单向网络,如下图所示:
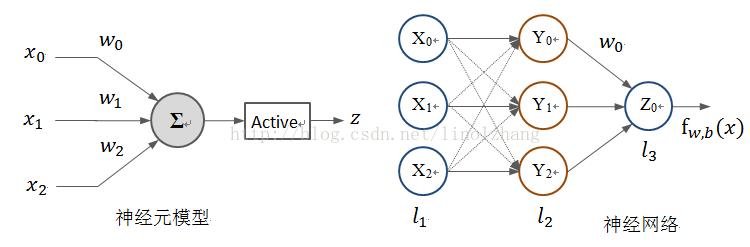
左图是1943年McCulloch和Pitts抽象出来的一种人工神经元模型,称为“M-P神经元模型”,分为信息归集(加权求和)和 随机处理(激活函数)两个部分,“加权求和”对接收信息进行触发响应,而“激活函数”旨在模拟信号衰减、抑制的随机过程。
多个神经元按照层次划分,严格定义输入输出,这就是神经网络的雏形,虽然这与实际情况仍有较大差异。
目前你已经了解一个基本的神经网络模型,那这里面我们需要求解的是什么呢?对,是参数。直接给出公式: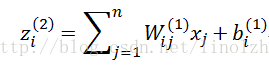
第二层的输出 由第一层的输入 加权计算得到, 是加权后的一个非线性变换,我们将其描述为激活函数,这是我们接下来要讲的一个重要概念。
• 激活函数
机器学习里面数据拟合有一个关键问题,模型越复杂,所能描述的信息量越丰富,其可分性也就越好。
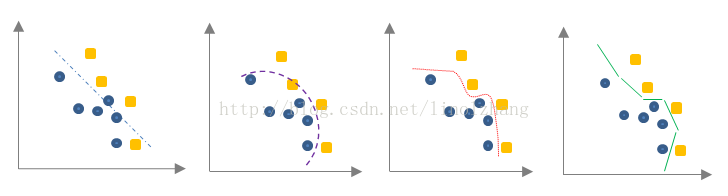
从这个图上,我们能够看到一个很明显的结论,线性函数对于数据的实用性最差,想要描述问题,我们有两种方法:
1)原来线性的加权平均过程变为更高次幂函数;
2)分段拟合。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









