







 本教程涵盖网络爬虫的基础知识,包括Requests库的使用,如GET方法、异常处理、HTTP协议,以及遵守Robots协议。还提供5个实战案例,涉及京东、亚马逊商品信息爬取,搜索引擎关键词提交,网络图片下载和IP地址归属地查询。
本教程涵盖网络爬虫的基础知识,包括Requests库的使用,如GET方法、异常处理、HTTP协议,以及遵守Robots协议。还提供5个实战案例,涉及京东、亚马逊商品信息爬取,搜索引擎关键词提交,网络图片下载和IP地址归属地查询。
【第〇周】网络爬虫之前奏
课程推荐阅读文章:关于反爬虫,看这一篇就够了
网络爬虫”课程内容导学
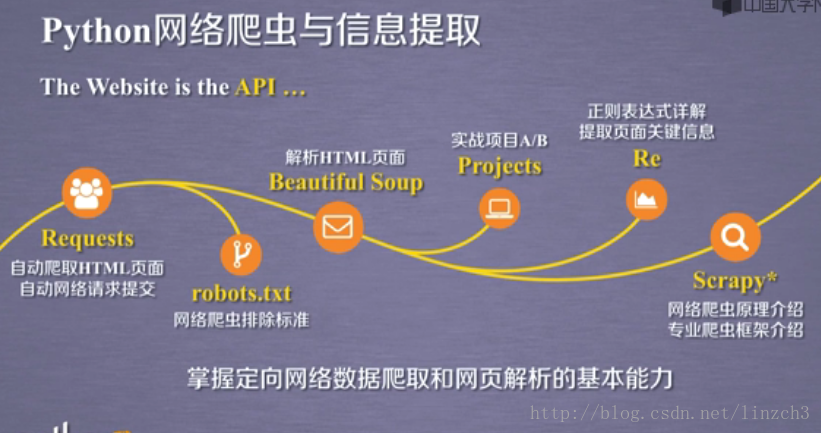

【第一周】网络爬虫之规则
1.Requests库入门
Requests库英文文档:Requests: HTTP for Humans
Requests库中文文档:Requests: 让 HTTP 服务人类
注意:中文文档的内容要稍微比英文文档的更新得慢一些,参考时需要关注两种文档对应的Requests库版本。(对于比较简单的使用方法,我们看中文的就行了)
Requests库的7个主要方法:

注:这7的方法的后面6个都是由requests.request()函数封装的。
get方法的使用
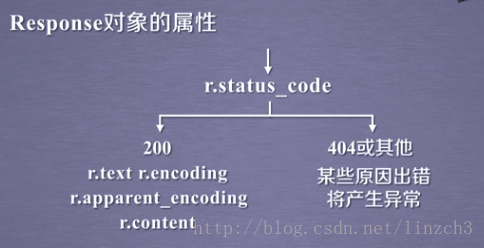
对于代码r=requests.get(url),r为函数返回的Response 对象,该对象包含爬虫返回的内容。
Response 对象的属性:

这5个属性的使用流程:
例子:
>>> import requests
>>> r=requests.get('http://www.baidu.com')
>>> r.status_code
200
>>> r.text
'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>ç\x99¾åº¦ä¸\x80ä¸\x8bï¼\x8cä½\xa0å°±ç\x9f¥é\x81\x93</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=ç\x99¾åº¦ä¸\x80ä¸\x8b class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ\x96°é\x97»</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>å\x9c°å\x9b¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§\x86é¢\x91</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å\x90§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>ç\x99»å½\x95</a> </noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj_login" class="lb">ç\x99»å½\x95</a>\');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æ\x9b´å¤\x9a产å\x93\x81</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å\x85³äº\x8eç\x99¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









