






1.论文介绍
对于以前的hash算法,是把特征学习和hashcode的学习分开来进行的,有的是先使用手工特征或者学习到的特征,然后在进行hashcode的学习。两个过程分裂开来进行学习的。每次学习只是整个目标的一部分,这样会陷入到局部最优解当中。所以作者针对这里面存在的问题,提出了deep hashing network的算法,主要解决的问题在于一下几个方面:
1).通过CNN来学习特征,而不是使用传统的手工特征或者一般的机器学习得到的特征。
2).通过在基本CNN网络的最后一层添加一个hash全连接层,来生成最终的hashcode
3).使用同时输入两张图片并且加上标签,通过学习过程当中使用交叉熵这种损失,限制学习到的hashcode在同类图片当中更加的接近。即原始空间和海明空间的相似性尽可能的保持。
4).通过限制同类图片的量化损失,来提高hashcode的质量。
作者按着上述的几个方面提出他的目标函数,以及学习的方法。
2.符号表示
2.1相似检索中的表示:
对于一个含有
N
张图片当中
作者正是通过输入一对图片来学习图片的hashcode,对于 S={sij} 的构成可以通过训练数据集来生成。训练的时候输入是: (xi,xj,sij)
其次学习hashcode的目标就是:学习到一个函数
f:x↦h∈{−1,1}K ,即 h=f(x)
2.2.模型表示
作者在训练的过程当中使用到了AlexNet,下面介绍AlexNet的表示。
AlexNet总共有八层,其中前五层(
conv1−conv5
)表示的是卷积层,后面的三层
fd6−fc8
表示的是全连接层。对于全连接层有
其中: zl 是 xi 在第 l 层的表示,
下面是作者训练过程当中的网络结构图:
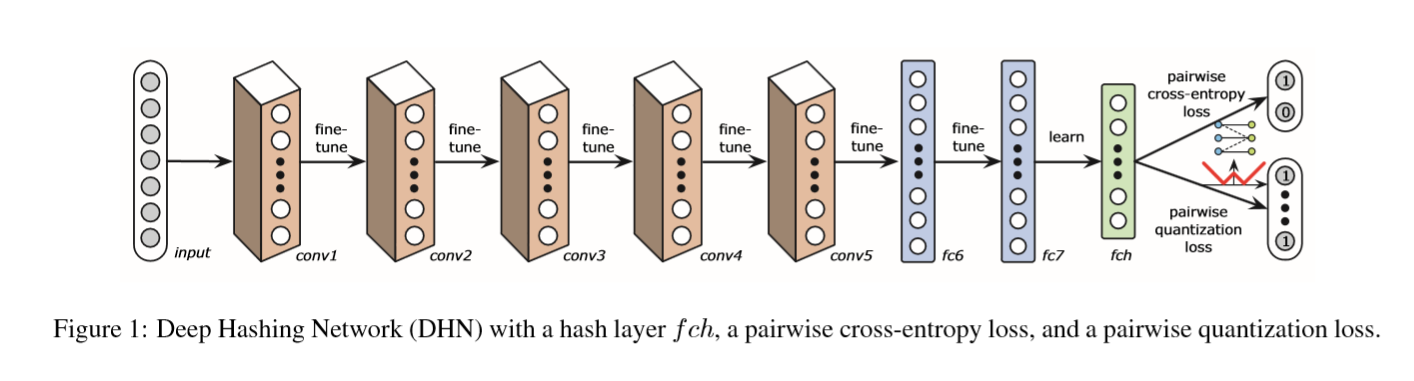
作者把在不同空间中图片一致相似性,以及空间转换的量化误差结合在一起来学习。作者把这两个方面包含在一个贝叶斯框架当中来进行学习。
对于两个hashcode,
hi,hj
可以得到他们之间的内积和海明距离之间的关系
对于给定的带有标签的集合 S={sij} 以及对于学习到的hashcode
H=[h1,h2⋯,hN] ,根据贝叶斯定理可以得如下的公式:
其中 p(S|H) 是似然函数, p(H) 是先验,对于任何的一对图片的hashcode以及标签可以得到, p(sij|hi,hj) 条件概率可以转化为内积空间中来进行计算
其中sigmoid函数 σ(x)=11+e−x,hi=zli
这个是作者后面进行训练的整体框架。
下面对于具体的每一项进行解析:
作者提出来hashcode的先验, p(hi) 表示一个hashcode的先验
加入先验的,以及量化误差,可以得到如下的目标函数:
L 表示的是交叉熵损失
Θ={Wl,bl} 表示参数的集合
根据前面可以用内积空间表示相似度,来定义交叉熵损失函数。
同时量化损失
其中 1∈RK 所有元素都为1的 K 维向量。对于上面的
得到:
这样就可以对目标函数进行求导和反向传播算法了。
最后一步的量化过程实际是 h=sign(zl) ,其中 sign
2.3学习算法
对于上面提到的整个训练过程的目标函数,进行特化到每对图片输入上有如下的局部目标函数:
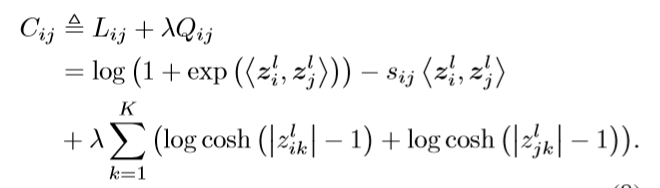
在反向传播的过程当中,需要对于上述一对图片训练损失进行求导数,对于网络的参数进行求导数可以得到
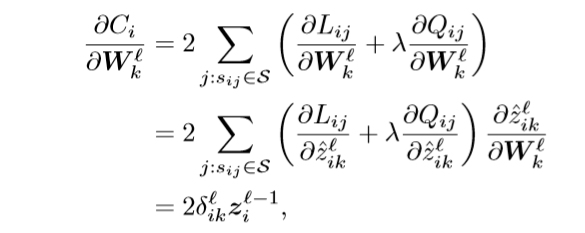
其中
z~li=Wlzl−1i+bl
是第
l
层的激活函数之前的输出,
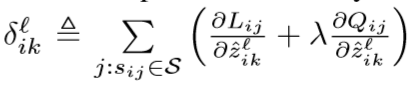
表示第
但是对于最后一层
l=8
导数的计算,可以直接使用输出结果
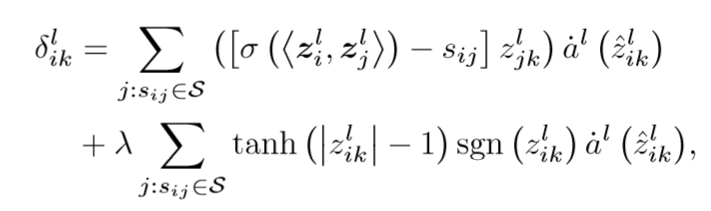
对于其他层可以使用
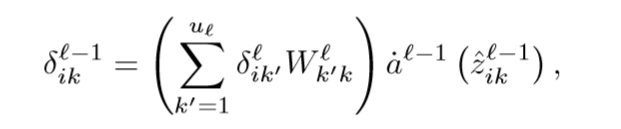
来计算偏导数的值。
这样就可以通过BP算法进行训练了。
下面就是实验部分
3.实验以及结果
3.1实验的数据集:NUS-WIDE,CIFAR-10, Flickr三个数据集
NUS-WIDE: 195,834 图片,实验过程当中resize为 256×256,随机1000张测式4000张训练,相似集合的构建为同一类图片,不同类图片认为是不相似,只要两张图片有一个语义标签一致就认为是相似的图片。
CIFAR-10: 60000张/类,总共10类,大小为32×32,100张/类测式,500张/类进行训练,
Flickr:25,000张图片,每张有38个标签,实验过程当中resize为 256×256
下面是MAP值,在不同hashcode 长度的情况下的对比
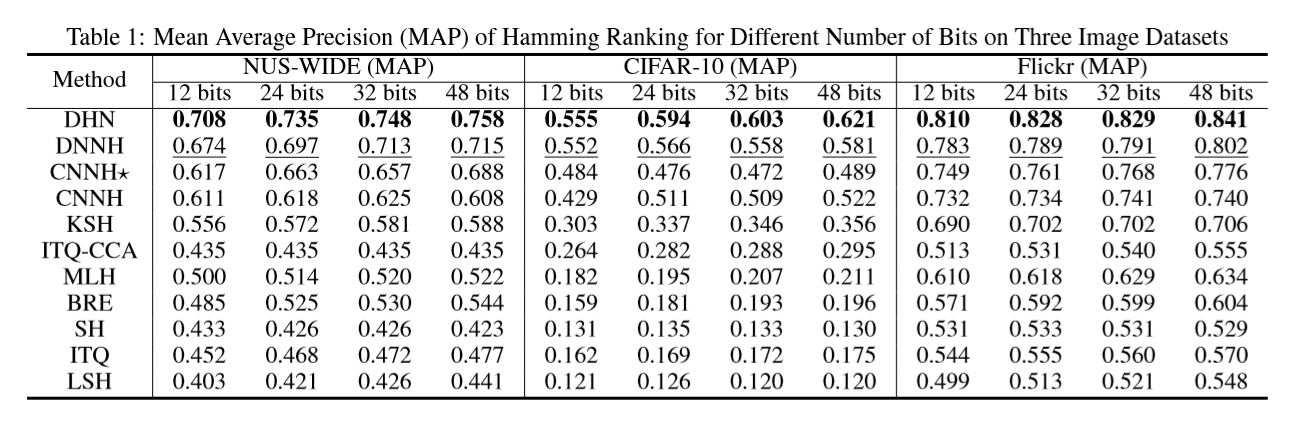
对于其他的方法输入的特征有:
NUS_WIDE 使用500D的视觉字典
CIFAR-10:使用512D的GIST特征。
Flickr:使用SIFT和GIST的特征的结合。
作者的方法使用CNN的特征。
网络的设置:参考AlexNet的具体设置。
从上面的表格当中可以看出来,作者提出来的方法对于使用传统手工特征进行hashcode学习的方法,具有相对明显的优势。
对于其他使用CNN或者深度神经网络的方法也具有一定的优势。
下面从准确率和召回率的曲线来分析下实验的结果:
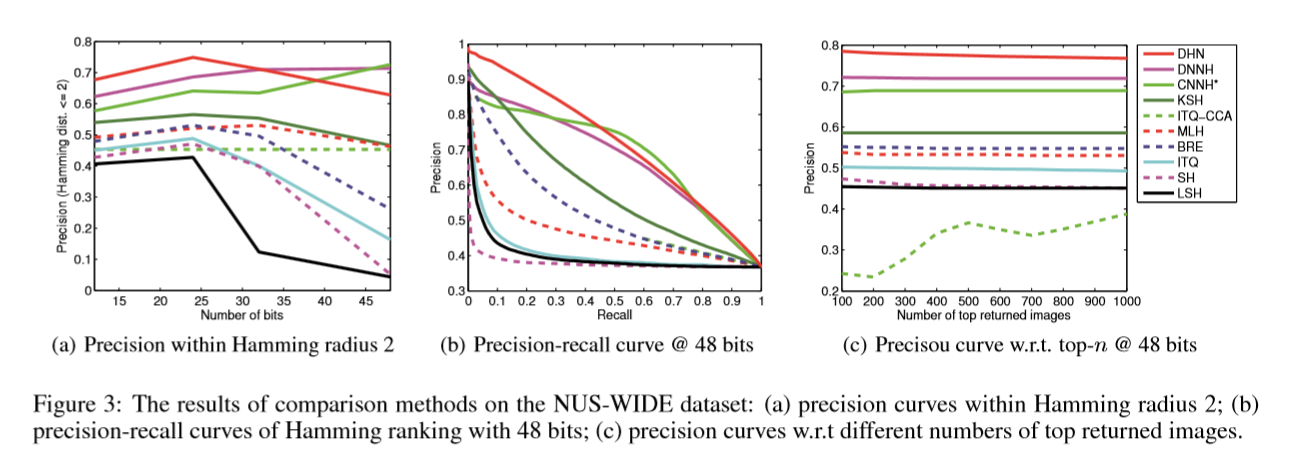
上面这张图在NUS_WIDE上面的结果,海明半径r=2,后面两张图是hashcode 长度为48结果。
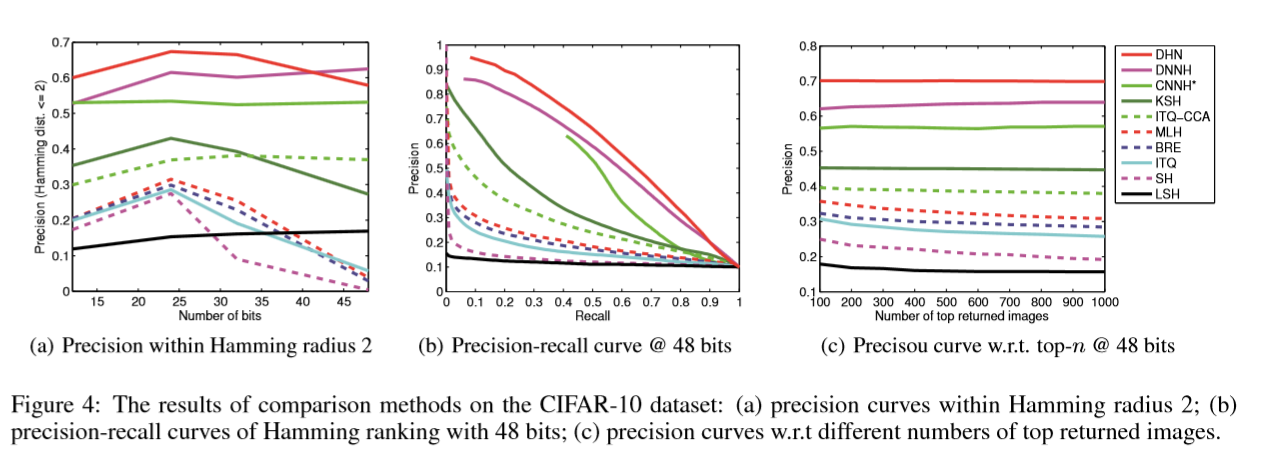
上面的图分别是在radius=2的准确率和hashcode的长度之间的关系。
第二个图是hashcode为48,的准确率和召回率的曲线图。
第三张是hashcode为48的,top-n的准确率。
4.总结
做这提出来,基于深度学习的贝叶斯学习hashcode的框架。并且提出同时输入一对图片及标签,优化具有交叉熵损失和量化损失的方法,来学习hashcode,通过实验可以说明做这提出来的方法相比于之前的方法具有一定得提升。














 2924
2924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









