







2.1 清楚标注错误的数据
如果我们发现我们的数据有一些标记错误的例子,我们该怎么办?我们首先来考虑训练集,事实证明,深度学习算法,对于训练集中的随机误差是相当鲁棒的,只要我们的标记出错的例子,只要这些错误例子离随机误差不太远,误差足够随机,那么放着这些误差不管可能也没问题,而不需要花太多时间修复他们。
深度学习算法对随机误差很鲁棒,但是对系统性的误差就没那么鲁棒了,我们做标记的人一直把白色的狗标记为猫,那么就成问题了,因为我们的分类器学习之后,会把所有的白色的狗都分类为猫,但是随机误差或者近视随机误差,对于大多数算法来说,不成问题。
2.2 快速搭建第一个系统并进行迭代
(1)快速设立开发集和测试集还有目标,这样就决定了我们的目标所在
(2)马上搭好一个机器学习的系统原型,然后找到训练集训练一下,看看效果,在开发集,测试集,看我们的评估指标的表现如何。
(3)成功建立系统之后,马上用到之前说的偏差方差分析,以及误差分析。
说这三点是想强调,我们最开始不必急于完成一个复杂的系统,而是弄清出我们的目标是什么,然后搭建系统的简单原型。
2.3 在不同的划分上进行训练并测试
我们先前讲过,尽量选择训练集,开发集,测试集来自同一分布,但是实在没有这么多数据来自同一分布怎么办呢。
我们用下面这个例子来讲解。
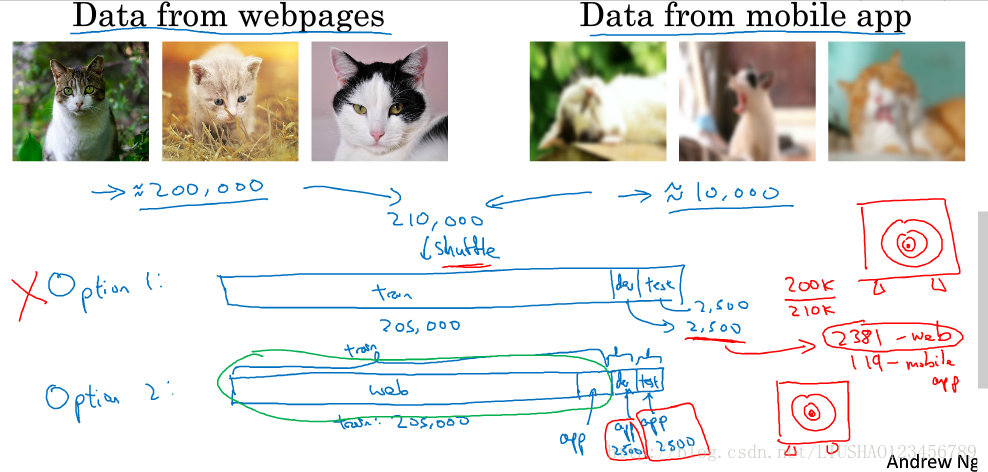
假设有200k张照片来自网页,10k张張片来自手机app,我们训练这些数据,并像用户推荐照片。我们正常的做法可能就是将这些照片进行洗牌操作,然后选择205k的照片作为训练集,2.5k照片最为开发集,2.5k照片作为测试集,其实这种划分训练集,开发集,测试集的做法是错误的。因为 没有弄清楚我们的目标。
我们正确的做法应该是将从网页上下载的200k再加上从手机app下载的5k照片作为训练集,然后将从手机app的2.5k照片作为开发集,其余的从手机app下载的2.5k照片作为测试集。这时数据来自不同分布的划分方法。
特定场景下的语音识别训练集,开发集,测试集的例子亦是如此划分。
2.4 不匹配数据的偏差和方差
当我们的训练集来自和我们的开发集以及测试集不同的分布时,分析偏差和方差的方式就不一样了。
我们继续以猫分类器为例,要进行误差分析,我们通常要看训练误差,也要看开发集的误差,假设训练误差为1%,开发误差为10%。我们知道,如果他们来自同一分布,我们会认为这是高方差问题,只需要进行正则化就好。来自不同分布,此时就有可能存在两个问题。第一,可能算法只见过训练集数据,没见过开发集数据。第二,开发集数据来自不同的分布,而且因为我们同时改变两件事情,很难确认这9%的误差,有多少是因为算法没见过开发集中的数据而导致的,这是问题方差部分。
为了弄清哪个因素影响更大,定义一组新的数据是有意义的,我们称之为训练-开发集,所以这是一个新的数据子集,我们应该从训练集的数据里挖出来但不会用来训练我们的网络。这个训练-开发集来自于随机打散的训练集,此时,训练集和训练-开发集来自同一分布。此时,我们可以看看分类器在训练集上的误差,再看看分类器在训练-开发集上的误差,以及开发集上的误差。假设训练集的误差为1%,训练开发集的误差为9%,那此时我们认为的确存在高方差问题。如果训练集误差为1%,训练-开发集误差为1.5%,那我们可以判断出现的问题可能是因为算法只见过训练集数据,而没有见过开发集数据而造成的。我们称之为因为数据不匹配而造成的。
2.5 迁移学习
深度学习最强大的理念之一就是有的时候,神经网络可以从一个任务中学习知识,并将这些知识应用到另一个独立的任务中。这就是迁移学习。举个例子,也许我们已经训练好了一个神经网络,这个神经网络能够识像猫一样的图像,然后使用该神经网络所学到的知识或者部分知识取帮助我们更好的阅读X射线扫描图。我们来讲讲迁移学习是如何做的。如下图所示:
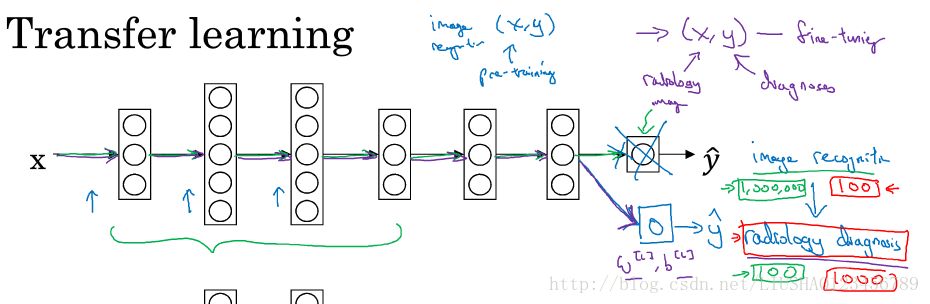
假设上图是一个识别猫的神经网络,现在我们要用这个神经网络来帮助我们阅读X射线扫描图。我们只需要在最后输出层做些改动,我们将最后的输出层删掉,以及该层的权重参数重新进行随机初始化,然后让它在放射诊断数据源上训练。
这里存在一个经验规则,即如果我们有一个小数据集就只训练输出层前的最后一层。
如果我们重新训练神经网络中的所有参数,那么这个在图像识别数据初期训练阶段称为预训练。
为什么迁移学习会有效果?因为有很多低层次特征比如像边缘检测,曲线检测从非常大的图像识别数据库中习得这些能力,可能有助于我们的学习算法在放射科诊断中做得更好。
迁移学习什么时候有意义?迁移学习起作用的场合是迁移来源问题有很多数据,迁移目标问题没有那么多数据。
下面是迁移学习的一些总结。

2.6 多任务学习
在迁移学习中,我们的步骤是串行的,在多任务学习中,我们是同时开始学习的,也就是说试图让单个神经网络同时做几件事情,然后希望这里每个任务都能帮助其他所有任务。
多任务学习用的逻辑回归,它与sofamax回归的主要区别在于,softmax将单个样本,而多任务学习中这张图可以有很多不同的标签。
下面是一个多任务学习的例子。
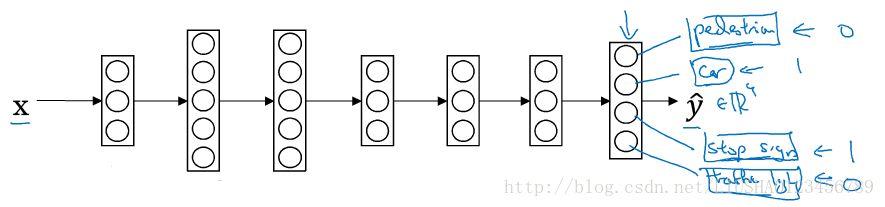
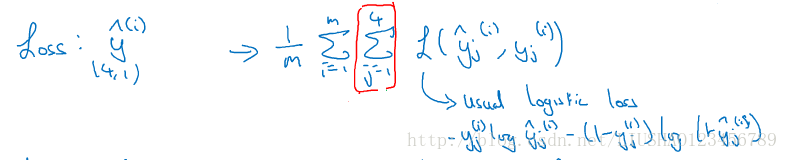
该神经网络要同时处理四个任务,行人,汽车,信号灯以及停车标志。此时,他的输出就相当于一个四维向量,此时它的成本函数也就是多任务学习的成本函数如下:
2.7 端到端的学习
端到端的学习是深度学习最令人振奋的最新动态之一。简而言之:比方说以前有一些数据处理系统或者学习系统,他们需要多个阶段的处理,那么端到端学习就是忽略所有这些不同的阶段,用单个神经网络直接进行代替。以语音识别为例,如下:

从上图可知,输入目标X比如说一段音频,然后把它映射到一个输出y,传统上是语音识别需要很多阶段的处理,首先我们会提取一些特征,比如说用MFCC算法,提取低层次特征之后,利用机器学习算法在音频片段中找到音位,然后再转化为词向量,最后转化为手写的文本形式。端到端学习就是过滤到中间的一系列操作,直接将音频转化为文本形式。
事实证明:端到端深度学习的挑战之一是,我们可能需要大量的数据,如果数据量不够的话,那么传统的流水线方式效果还要更好,但是当我们拥有足够多的数据时,端到端学习就突然开始很厉害了。下面是端到端的一些优缺点:















 1300
1300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









