







SPSS——基本的统计概念
总体和样本
总体和个体
研究对象的全体成为总体,一般地把我们关心的随机变量X成为总体。组成总体的每个单元称为个体。个体也可理解为总体X的取值
简单随机抽样
为了使抽样具有充分的代表性,要求
- 每个个体被抽到的机会均等
- 每次抽取都是独立的(共抽取n次)
通常的抽样都是无放回的,当总体很大的时,可以满足独立性
样本
总体是指考察的对象的全体, 个体是总体中的每一个考察的对象, 样本是总体中所抽取的一部分个体, 而样本容量则是指样本中个体的数目。
在总体中抽取n个个体,成为总体上的一个样本,记为(X1, X2, …, Xn),其中每次抽样Xi(i=1,2,3..,n)也都是随机变量,共n个随机变量,加上括号,表示样本是一个整体
独立同分布
在概率统计理论中,如果变量序列或者其他随机变量有相同的概率分布,并且互相独立,那么这些随机变量是独立同分布。
随机变量X1和X2独立,是指X1的取值不影响X2的取值,X2的取值也不影响X1的取值.随机变量X1和X2同分布,意味着X1和X2具有相同的分布形状和相同的分布参数,对离散随机变量具有相同的分布律,对连续随机变量具有相同的概率密度函数,有着相同的分布函数,相同的期望、方差。反之,若随机变量X1和X2是同类型分布,且分布参数完全相同,则X1和X2完全一定同分布!
如实验条件保持不变,一系列的抛硬币的正反面结果是独立同分布。
随机变量
随机变量(random variable)表示随机试验各种结果的实值单值函数。
一个随机试验可能结果(称为基本事件)的全体组成一个基本空间Ω。随机变量X是定义在基本空间Ω上的取值为实数的函数,即基本空间Ω中每一个点,也就是每个基本事件都有实轴上的点与之对应。例如,随机投掷一枚硬币,可能的结果有正面朝上 ,反面朝上两种 ,若定义X为投掷一枚硬币时朝上的面 , 则X为一随机变量,当正面朝上时,X取值1;当反面朝上时,X取值0。又如,掷一颗骰子,它的所有可能结果是出现1点、2点、3点、4点、5点和6点 ,若定义X为掷一颗骰子时出现的点数,则X为一随机变量,出现1,2,3,4,5,6点时X分别取值1,2,3,4,5,6。

统计量
统计量是含有样本X1, X2, …, Xn的一个数学表达式,并且表达式中不包含未知参数,因此可以在得到样本后计算出它的数值。
在抽样之前,统计量的值无法确定,抽样测试后,可以观察到它的取值,因此统计量是随机变量,是由样本派生出来的随机变量。
样本均值
均值描述的是样本集合的中间点,它告诉我们的信息是很有限的
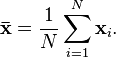
样本标准差
标准差给我们描述的则是样本集合的各个样本点到均值的距离之平均。以这两个集合为例,[0,8,12,20]和[8,9,11,12],两个集合的均值都是10,但显然两个集合差别是很大的,计算两者的标准差,前者是8.3,后者是1.8,显然后者较为集中,故其标准差小一些,标准差描述的就是这种“散布度”。之所以除以n-1而不是除以n,是因为这样能使我们以较小的样本集更好的逼近总体的标准差,即统计上所谓的“无偏估计
我们知道,样本量越大越能反映真实的情况,而算数均值却完全忽略了这个问题,对此统计学上早有考虑,在统计学中样本的均差多是除以自由度(n-1),它是意思是样本能自由选择的程度。当选到只剩一个时,它不可能再有自由了,所以自由度是n-1。
n-1中的-1就是为了在考虑样本标准差自由度上做的一个调配系数,既定为1,,假设计算的标准差所对应的数据列只有1个数据,则1-1=0,不存在标准差,,以此证明-1为调配系数,,所及请记住一般算标准差是,,都是算样本数据的标准差,即:(n-1分之 各个数据与平均数差值的平方和)的2次方根。
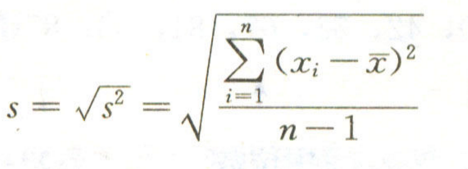
样本方差
方差则仅仅是标准差的平方。
即样本方差计算公式里分母为n-1的目的是为了让方差的估计是无偏的。无偏的估计(unbiased estimator)比有偏估计(biased estimator)更好是符合直觉的
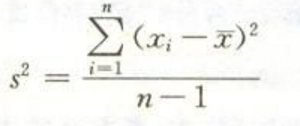
















 7309
7309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









