









机器学习(十八)异常检测
本文由 @lonelyrains出品,转载请注明出处。
文章链接: http://blog.csdn.net/lonelyrains/article/details/49861491
问题提出
实际生产过程中,出产投入使用之前,经常会评价某些参数是否有异常,然后再判断是否要重新检测。评价并不是简单的根据特定参数的阈值来的,而是根据宏观上产出群体的所有参数分布得出的。
比如生成飞机引擎,震动和热量参数,对所有出产的引擎进行测试,得到如下分布:
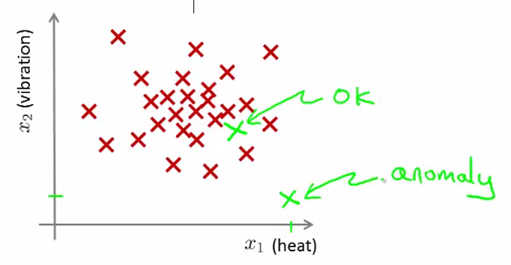
为了评价这种差异,定性分析如下:

高斯分布
从上面的直观感受、定性分析可知越接近中心区域的越不可能是异常。为了定量分析,引入高斯分布。即认为所有的参数符合高斯分布。数学表达为: X∽N(μ,σ2) 。其中 μ 为均值, σ2 为方差。
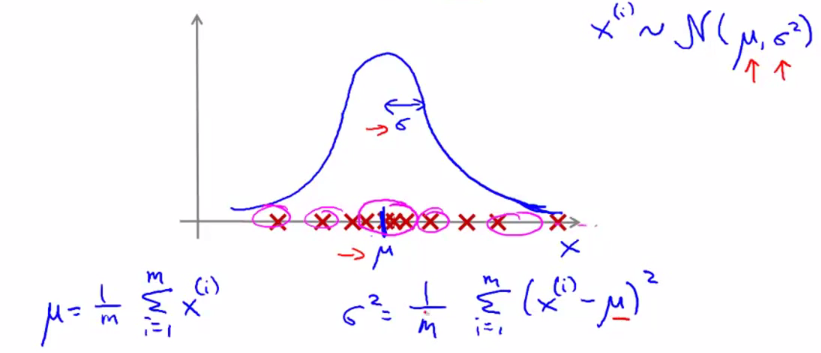
高斯分布的异常检测算法

开发和评估一个异常检测系统

异常检测和有监督学习对比
- 特性区别
| 异常检测 | 有监督学习 |
| 正样本比较少 | 正样本充足 |
| 异常类型很多,且不可预测 | 待检测的正样本与已检测过的相似 |
- 使用场景区别
| 异常检测 | 有监督学习 |
| 欺骗检测 | 垃圾邮件分类 |
| 制造业质检 | 天气预测 |
| 动力环境监测 | 癌症分类 |
| …. | …. |
选择用什么属性
调整属性,以满足高斯分布。如下图,先得到所有样本某一属性
x1
的直方图,然后对
x1
取对数:
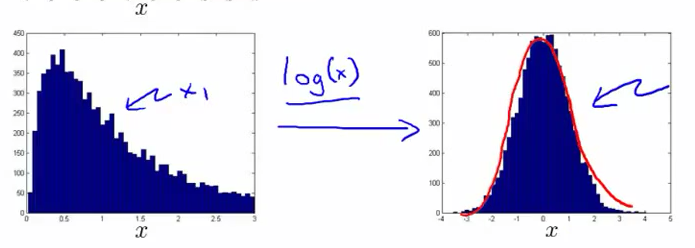
多变量高斯分布
直接用与样本中心点的距离来评价是否异常有时候不准确,如下图:
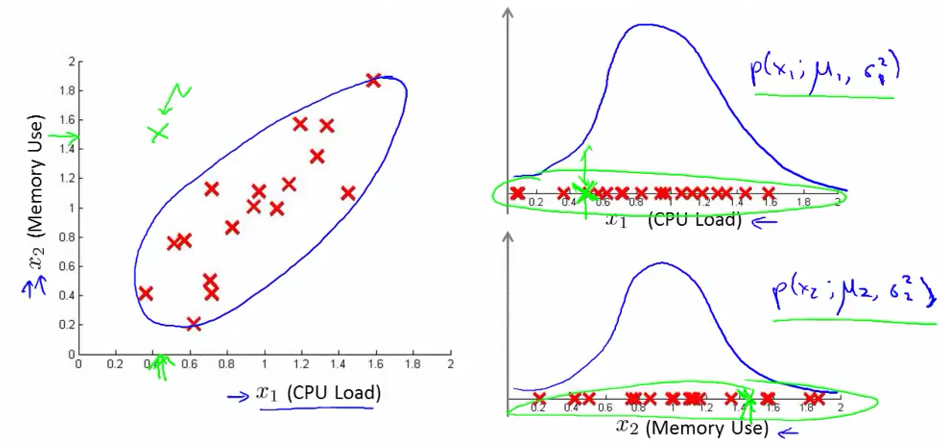
图中绿色的点距离样本中心比较近,其中右边两个图为样本在两维度的投影。但是直观感觉也是应该检测出的异常点。为了应对这种情形,引入了多变量高斯分布。
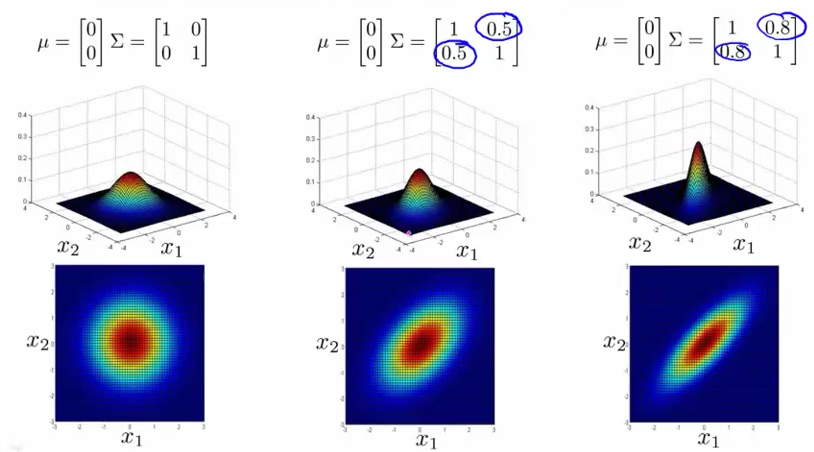
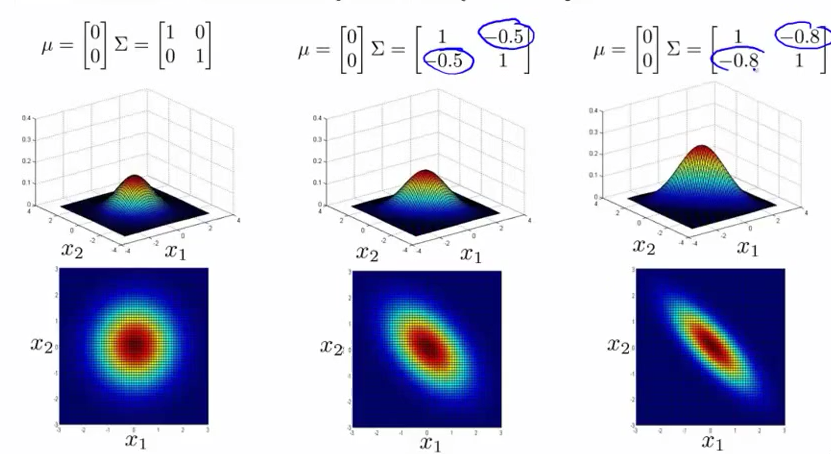
多变量高斯分布,对应不同的均值 μ 和协方差 Σ 特性如下图:

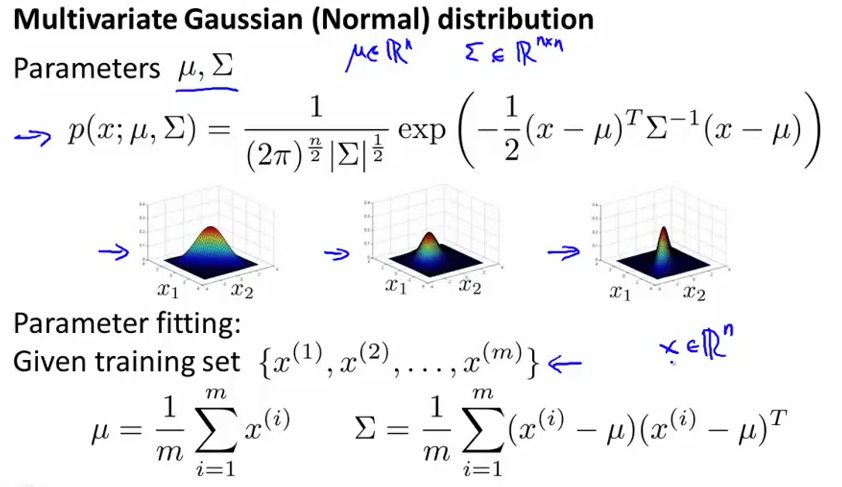
多变量高斯分布的概率公式:
| 多变量连乘模型 | 多变量高斯模型 |
| 需要手工设置新属性以求相关属性参数比例不对的,比如 CPUloadmemory | 自动获取关联属性表现 |
| 计算简单 | 计算耗时,需要计算 Σ−1 |
| 即使属性数
n
很大,而样本数 | 必须 n<m ,否则 Σ−1 无解 |
—————
- F1−score 的特性是p、q都很大时,值才比较高;反之,如果有一个比较小,值就比较小。很适合对正样本比较小的系统进行评估,而不仅仅是用正确率。p、q都为1时,为了使 F1−score 的值也为1,所以乘了2。 ↩

















 39
39

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









