







并行思想
考虑如下问题:在一个数据量很大的一个数组中,如何快速有效的对所有数据进行累加?
最原始的想法:利用多线程思想,将数组等分成若干份(例如4份),对于每一份数据中创建一个多线程进行累加,最后将4份数据的和相加求得结果。
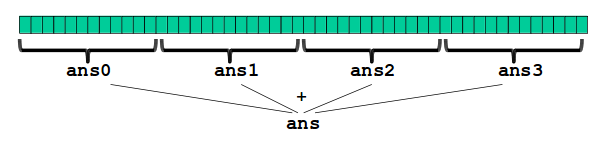
我们可以写出如下原始代码:
class SumThread extends java.lang.Thread {
int lo, hi;
int[] arr; // arguments
int ans = 0; // result
SumThread(int[] a, int l, int h) {
lo=l; hi=h; arr=a;
}
public void run() { //override must have this type
for(int i=lo; i < hi; i++)
ans += arr[i];
}
}
class MainThread{
public static void main(String[] args){
int[] arr = new int[100];
for(int i = 0; i<100;i++)
arr[i] = i;
System.out.println(sum(arr));
}
static int sum(int[] arr){// can be a static method
int len = arr.length;
int ans = 0;
SumThread[] ts = new SumThread[4];
for(int i=0; i < 4; i++){// do parallel computations
ts[i] = new SumThread(arr,i*len/4,(i+1)*len/4);
ts[i].start();
}
for(int i=0; i < 4; i++) { // combine results
try{
ts[i].join(); // wait for helper to finish!
ans += ts[i].ans;
}
catch(InterruptedException e)
{
System.out.println("11");
}
}
return ans;
}
}lo, hi, arr在主线程中创建,可以在helper线程中读取;ans在helper线程中被创建,也可以在主线程中被读取。
对上述代码稍作改进,按每一个处理器运行一个线程,允许根据可用处理器个数设置线程个数:(以后代码中省略try-catch,但是在实际运行中必须加上,否则会报InterruptedException错误)
int sum(int[] arr, int numTs){
int ans = 0;
SumThread[] ts = new SumThread[numTs];
for(int i=0; i < numTs; i++){
ts[i] = new SumThread(arr,(i*arr.length)/numTs, ((i+1)*arr.length)/numTs);
ts[i].start();
}
for(int i=0; i < numTs; i++) {
ts[i].join();
ans += ts[i].ans;
}
return ans;
}如果可以分配有足够多的线程,是不是有更好的方法呢?考虑使用 分治法,我们可以按二叉树的形式来分配线程
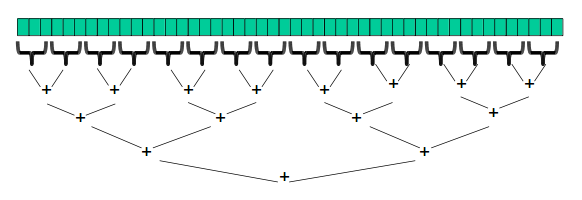
class SumThread extends java.lang.Thread {
int lo; int hi; int[] arr; // arguments
int ans = 0; // result
SumThread(int[] a, int l, int h) { … }
public void run(){ // override
if(hi – lo < SEQUENTIAL_CUTOFF)
for(int i=lo; i < hi; i++)
ans += arr[i];
else {
SumThread left = new SumThread(arr,lo,(hi+lo)/2);
SumThread right= new SumThread(arr,(hi+lo)/2,hi);
left.start();
right.start();
left.join(); // don’t move this up a line – why?
right.join();
ans = left.ans + right.ans;
}
}
}
int sum(int[] arr){
SumThread t = new SumThread(arr,0,arr.length);
t.run();
return t.ans;
}那么有没有更好的方法来利用有限的处理器呢?我们观察到,很多进程仅仅是用来分配两个子进程,之后在等待两个子进程完成后将两个结果相加,因此我们可以将该进程充当其中一个子进程继续向下执行,那么就会大大减少进程的等待时间。
| |
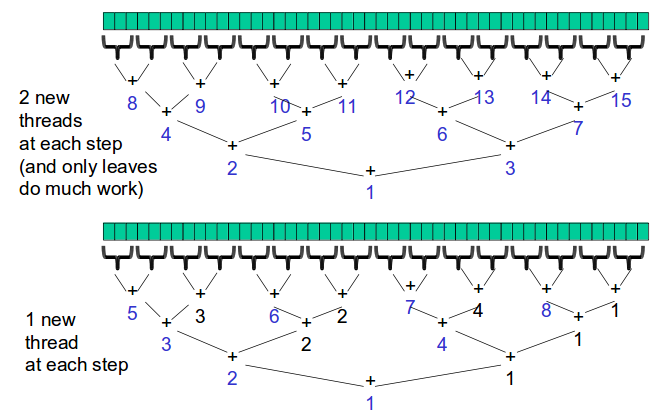
对比前两种的方法我们可以看到,之前一种方法需要15个处理器,而改进之后仅需要8个处理器,减少了近一半的处理器需求。
接下来,我们引入fork/join框架的内容对代码再一步优化,该框架正是针对这类分治问题而设计的。使用该框架注意一下原则:
| 不要继承自Thread | 继承自RecursiveTask<V> |
| 不要重载run方法 | 重载compute方法 |
| 不需要返回ans | 从compute中返回一个V |
| 不用调用start | 调用fork |
| 不要仅仅只是调用join | 使用join的返回值 |
| 不用调用run来使用上面的优化 | 调用compute来优化 |
| 不要在最上层直接调用run | 创建一个pool然后使用invoke |
运用fork/Join框架并优化后的最终代码如下所示:
class SumArray extends RecursiveTask<Integer> {
int lo; int hi; int[] arr; // arguments
SumArray(int[] a, int l, int h) { … }
protected Integer compute(){// return answer
if(hi – lo < SEQUENTIAL_CUTOFF) {
int ans = 0;
for(int i=lo; i < hi; i++)
ans += arr[i];
return ans;
} else {
SumArray left = new SumArray(arr,lo,(hi+lo)/2);
SumArray right= new SumArray(arr,(hi+lo)/2,hi);
left.fork();
int rightAns = right.compute();
int leftAns = left.join();
return leftAns + rightAns;
}
}
}
static final ForkJoinPool fjPool = new ForkJoinPool();
int sum(int[] arr){
return fjPool.invoke(new SumArray(arr,0,arr.length));
}














 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









