







环境搭建可参考:win10下使用eclipse开发hadoop环境搭建
本文对于在windows下使用eclipse远程连接hadoop进行开发的所遇到的问题进行了总结,并给出了相应的解决方案,以此为记,也希望能对有相同问题的后来者有所帮助。
使用反编译工具,反编译hadoop所给的统计单词数的示例程序hadoop-examples.jar,代码如下:
package mrtest;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, WordCount.class.getSimpleName());
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
this.result.set(sum);
context.write(key, this.result);
}
}
static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
在hadoop上运行该程序前先填写运行的配置参数:右键-》Run As-》Run Configurations-》Arguments;在Program arguments里填入输入输出目录:
hdfs://master:8020/usr/hadoop/wordCount/input
hdfs://master:8020/usr/hadoop/wordCount/output
如下图所示。
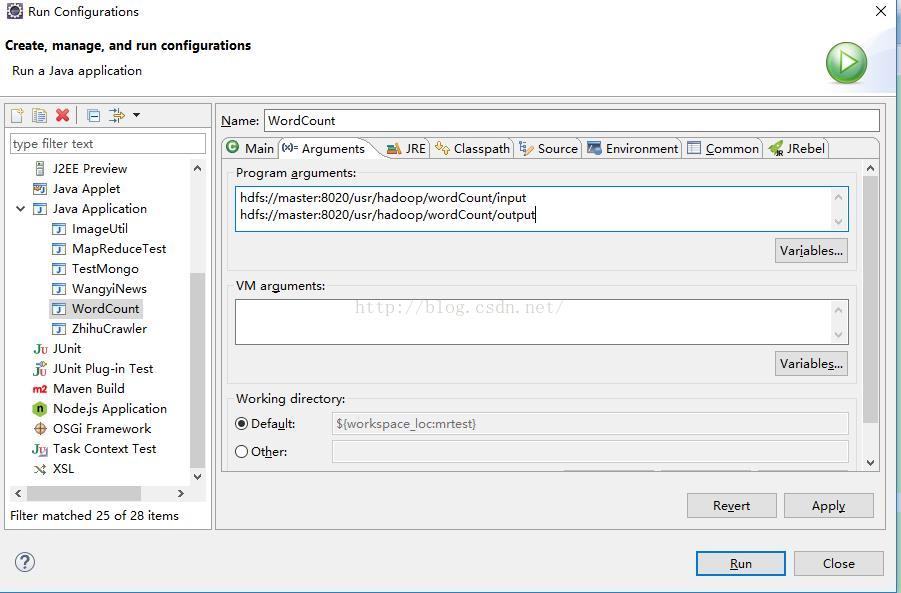
注意:根据自己实际情况填写,地址端口不对,都会报拒绝连接的异常,切记。在输入目录下上传自己需要处理的文件,譬如xxx.txt等。输出目录不能有,hadoop会自动生成,否则会报已存在。
上述步骤正确可以运行程序了,有可能会遇到以下两个主要异常,没有异常的略过。
(1)
Exception in thread “main”java.lang.NullPointerException
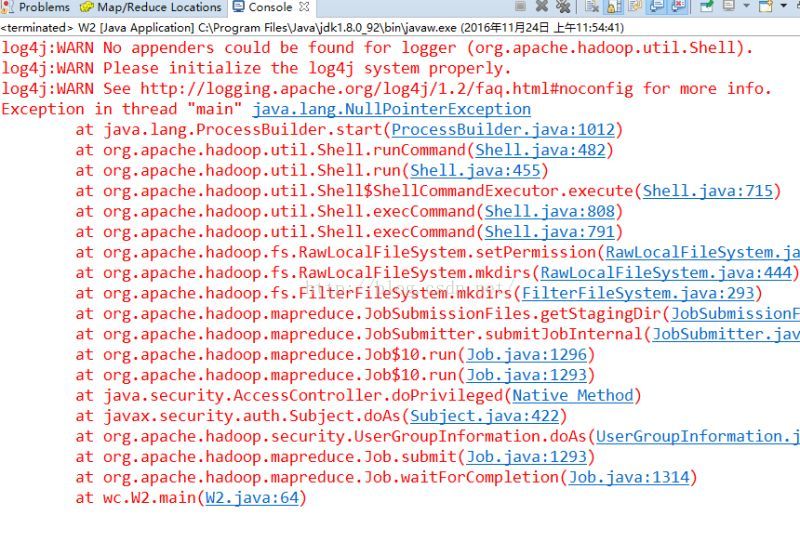
解决办法:此异常是windows下运行hadoop程序需要插件,下载以下几个插件:
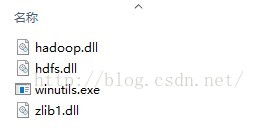
将下载的插件放入本地hadoop安装目录的bin文件夹下,并将%hadoop_home%/bin添加进入环境变量,重启电脑,再次运行程序,将发现该异常已经消失。
备注:如果还不行,将hadoop.dll放入C:\Windows\System32目录下,重启电脑测试。
(2)
Exception in thread "main"java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
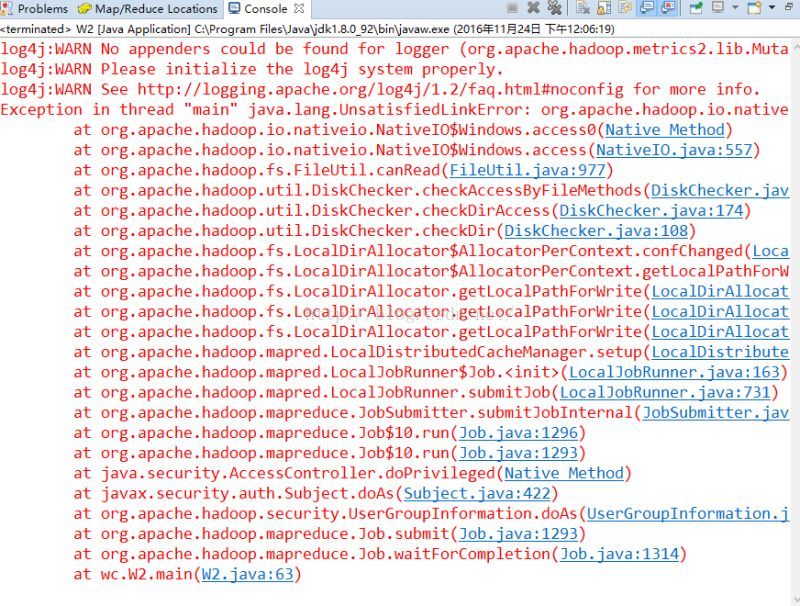
点击异常查看NativeIO.java:557行,如下:
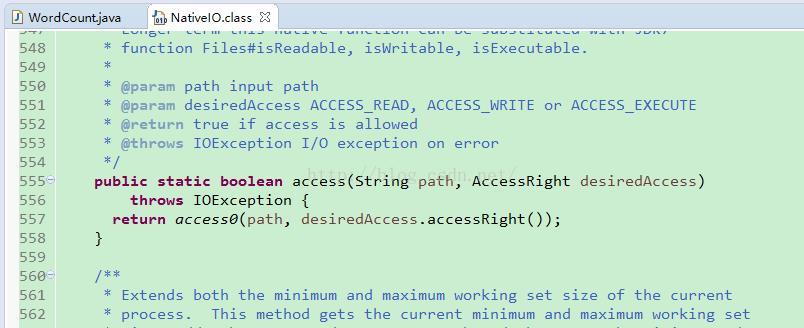
在windows下又访问检测,我们只需要将557行改为 return true; 即可。
下载hadoop源码,解压,在路径 hadoop-2.6.0-src\hadoop-common-project\hadoop-common\src\main\java\org\apache\hadoop\io\nativeio 下找到 NativeIO.java 文件,按照上述修改557行为返回 true 。
在项目的根目录下添加包名:org.apache.hadoop.io.nativeio,并将修改后的文件复制到该包下。如图所示:
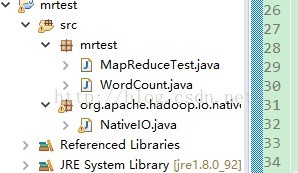
至此,该异常解决。
祝顺利。
附:所需资源下载
 hadoop2.6.0源码和eclipse插件
hadoop2.6.0源码和eclipse插件
 windows下hadoop2.6.0远程开发所用插件
windows下hadoop2.6.0远程开发所用插件














 1659
1659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









