









MapReduce程序分为三部分: map reduce driver
这里先放出最经典的wordcount程序源码:
public class WordCount extends Configured implements Tool{
//map
public static class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable>{
private Text MapoutputKey=new Text();
private final static IntWritable MapoutputValue=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//得到value
String lineValue=value.toString();
//split
StringTokenizer stringTokenizer=new StringTokenizer(lineValue);
//迭代取出数据
while(stringTokenizer.hasMoreTokens()){
//得到输入的value
String wordValue=stringTokenizer.nextToken();
MapoutputKey.set(wordValue);
//输出
context.write(MapoutputKey, MapoutputValue);
}
}
}
//reduce
public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable outputValue=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int sum=0;
for(IntWritable value:values){
sum+=value.get();
}
outputValue.set(sum);
//输出
context.write(key, outputValue);
}
}
//driver
public int run(String[] args) throws Exception{
//得到配置信息
Configuration configurable=getConf();
//创建Job
Job job=Job.getInstance(configurable,this.getClass().getSimpleName());
//运行jar
job.setJarByClass(this.getClass());
//设置job
//1. input
Path inPath=new Path(args[0]);
FileInputFormat.addInputPath(job, inPath);
//2.map
job.setMapperClass(WordCountMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//3.reduce
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//4.output
Path outPath=new Path(args[1]);
FileOutputFormat.setOutputPath(job, outPath);
//提交job
boolean completion = job.waitForCompletion(true);
return completion ? 0 : 1;
}
public static void main(String[] args) throws Exception{
//得到配置信息
Configuration configurable=new Configuration();
//int status=new WordCount().run(args);
int status=ToolRunner.run(configurable, new WordCount(), args);
System.exit(status);
}
}
这个wordcount程序可以在本地或者yarn上运行,首先要在eclipse中打成jar包,当然上边的代码要想直接运行,需要在maven中加入hadoop的jar包坐标,然后自动下载到本地仓库才可以,打包好后就跟hadoop中自带的wordcount程序运行过程一样,这里不进行细说,如果打包到运行测试有问题可以在文章末尾留言
wordcount执行流程:
input---->map-----reduce------output
input:
会文件按行分割形成<key,value>对,如下图所示:
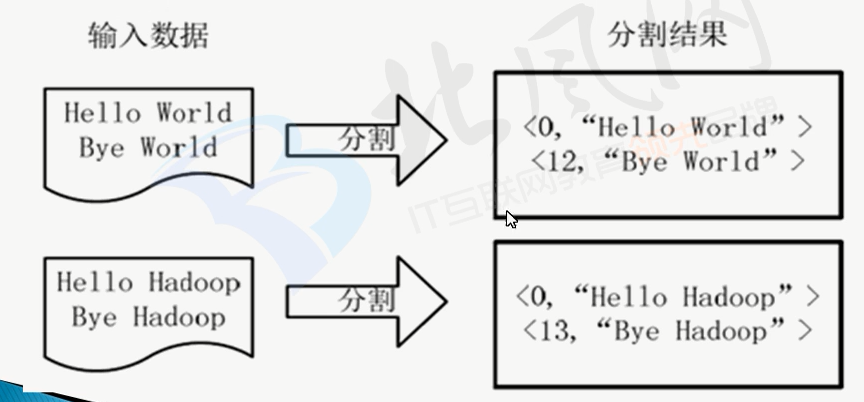
这一步由Mapreduce框架自动完成,其中key是偏移量,包含了回车所占的字符数,value是这一行的数据
map:
将分割好的<key,value>对交给用户定义的map方法处理,形成新的<key,value>对,如下图所示:
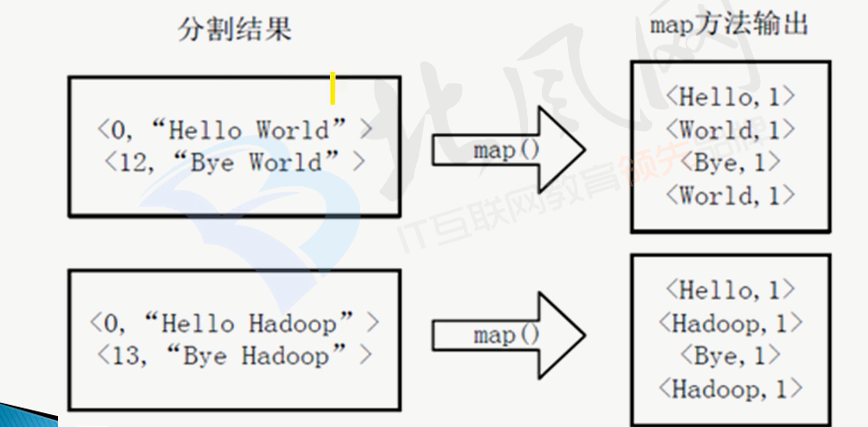
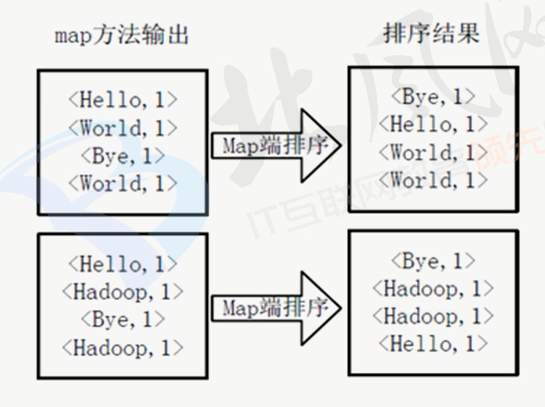
得到map方法输出的<key,value>对后,Mapper会将他们按照key值进行排序,得到Mapper的最终输出结果,如下图:
reduce:
Reducer先对从Mapper接受的<key,value>对进行shuffle处理,如下图:

然后再交给用户自定义的reduce方法进行合并处理,再得到新的<key,value>对,如下图:
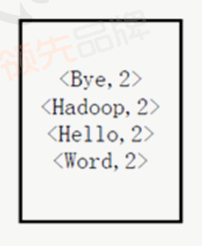
最后将这个<key,value>对作为wordcount的结果输出
中,















 2759
2759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









