







循环神经网络(Recurrent Neural Networks)
RNNs的目的是用来处理序列数据,在传统的神经网络模型中,网络结构是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的,但是这种网络对很多问题搜无能为力,例如,预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中的单词不是独立存在的,RNNs之所以称为循环神经网络,即一个序列当前的输入和前面的输出是有关系的,并且隐藏层的输入不但包括输入层的输入还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理,但在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关。
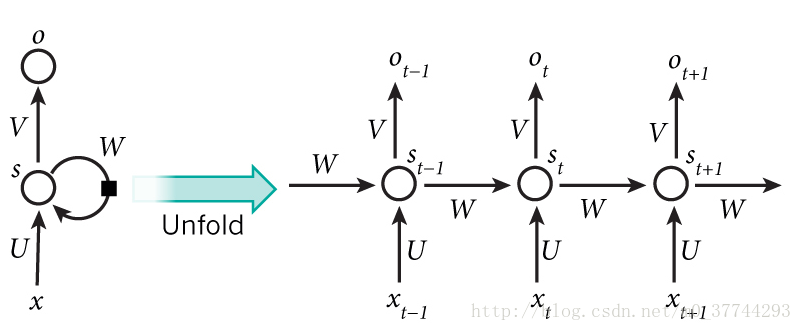
RNNs包含输入单元,输入集标记为 x0,x1,...,xt,xt+1,... ,而输出单元的输出集为 y0,y1,...,yt,yt+1,... ,RNNs还包含隐藏单元,将其输出集标记为 s0,s1,...st,st+1,... ,在上图中,有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流动的信息流从隐藏单元到达输出单元,并且隐藏层的输入还包括上一隐藏层单元的输出,即隐藏层内的节点可以自连也可以互连,在某些情况下,RNNs也可以引导信息从输出单元返回隐藏单元。
xt
表示
t
,
st
为隐藏层的第
t
步的状态,它是网络的记忆单元,
ot
是第
t
步的输出,
需要注意的是:
你可以认为隐藏层状态
st
是网络的记忆单元,
st
包含了前面所有步的隐藏层状态。而输出层的输出
ot
只与当前步的
st
有关,在实践中,为了降低网络的复杂度,往往
st
只包含前面若干步而不是所有步的隐藏层状态;
在传统神经网络中,每一个网络层的参数是不共享的。而在RNNs中,每输入一步,每一层各自都共享参数
U,V,W
。其反应在RNNs中的每一步都在做相同的事,只是输入不同,因此大大地降低了网络中需要学习的参数;解释一下,传统神经网络的参数是不共享的,并不是表示对于每个输入有不同的参数,而是将RNN是进行展开,这样变成了多层的网络,如果这是一个多层的传统神经网络,那么
xt
到
st
之间的
U
矩阵与
上图中每一步都会有输出,但是每一步都要有输出并不是必须的。比如,我们需要预测一条语句所表达的情绪,我们仅仅需要关系最后一个单词输入后的输出,而不需要知道每个单词输入后的输出。同理,每步都需要输入也不是必须的。RNNs的关键之处在于隐藏层,隐藏层能够捕捉序列的信息。
RNNs能干什么?
语言模型与文本生成:机器翻译是将一种源语言语句变成意思相同的另一种源语言语句,如将英语语句变成同样意思的中文语句。
机器翻译:机器翻译是将一种源语言语句变成意思相同的另一种源语言语句,如将英语语句变成同样意思的中文语句。
语音识别:语音识别是指给一段声波的声音信号,预测该声波对应的某种指定源语言的语句以及该语句的概率值。
图像描述生成
RNNs的训练
训练同样使用BP误差反向传播算法,不过和传统的神经网络有所区别,在RNNs中,将其网络展开,参数














 1754
1754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









