




 本文探讨了Easy Ensemble和Balance Cascade两种机器学习算法。Easy Ensemble通过从多数类抽样并结合少数类构建训练集,训练Adaboost分类器。预测阶段,它使用所有弱分类器的预测结果和权重向量计算,而非简单的多数表决。相比之下,Balance Cascade算法类似,但通过调整分类器阈值控制错误的多数类样本比例,以确保在多次迭代后多数类样本数量减少至等于少数类。
本文探讨了Easy Ensemble和Balance Cascade两种机器学习算法。Easy Ensemble通过从多数类抽样并结合少数类构建训练集,训练Adaboost分类器。预测阶段,它使用所有弱分类器的预测结果和权重向量计算,而非简单的多数表决。相比之下,Balance Cascade算法类似,但通过调整分类器阈值控制错误的多数类样本比例,以确保在多次迭代后多数类样本数量减少至等于少数类。
看了一下easy ensemble 算法的matlab代码,发现之前的理解有问题

从上面的伪代码可以看出,easy ensemble每次从多数类中抽样出和少数类数目差不多的样本,然后和少数类样本组合作为训练集。在这个训练集上学习一个adaboost分类器。
最后预测的时候,是使用之前学习到的所有adaboost中的弱分类器(就是每颗决策树)的预测结果向量(每个树给的结果组成一个向量)和对应的权重向量做内积,然后减去阈值,根据差的符号确定样本的类别。
之前我的理解是根据每个adaboost的预测结果做多数表决,比如10个adaboost,有6个adaboost预测为少数类,那么这个样本就是少数类。显然,easy ensemble不是这样来实现的。
balance cascade算法的算法框架如下:
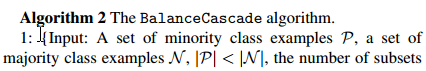

可以看出balance cascade算法和easy ensemble还是挺像的,差别就在第7步和第8步。
第6步,算法训练出一个分类器,然后在第7步调整分类器 Hi 的阈值 θi 以保证分类器
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 20
20

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









