







 本文介绍了如何使用TensorFlow实现AutoEncoder,通过编码将高维数据如MNIST压缩,并通过解码过程尝试恢复原数据。文章讨论了模型结构,包括编码器和解码器的设计,以及Sigmoid激活函数的应用。实验结果显示,AutoEncoder能够较好地复原数据,并且在2维空间中对数据进行了有效的聚类可视化。
本文介绍了如何使用TensorFlow实现AutoEncoder,通过编码将高维数据如MNIST压缩,并通过解码过程尝试恢复原数据。文章讨论了模型结构,包括编码器和解码器的设计,以及Sigmoid激活函数的应用。实验结果显示,AutoEncoder能够较好地复原数据,并且在2维空间中对数据进行了有效的聚类可视化。
一、概述
AutoEncoder大致是一个将数据的高维特征进行压缩降维编码,再经过相反的解码过程的一种学习方法。学习过程中通过解码得到的最终结果与原数据进行比较,通过修正权重偏置参数降低损失函数,不断提高对原数据的复原能力。学习完成后,前半段的编码过程得到结果即可代表原数据的低维“特征值”。通过学习得到的自编码器模型可以实现将高维数据压缩至所期望的维度,原理与PCA相似。
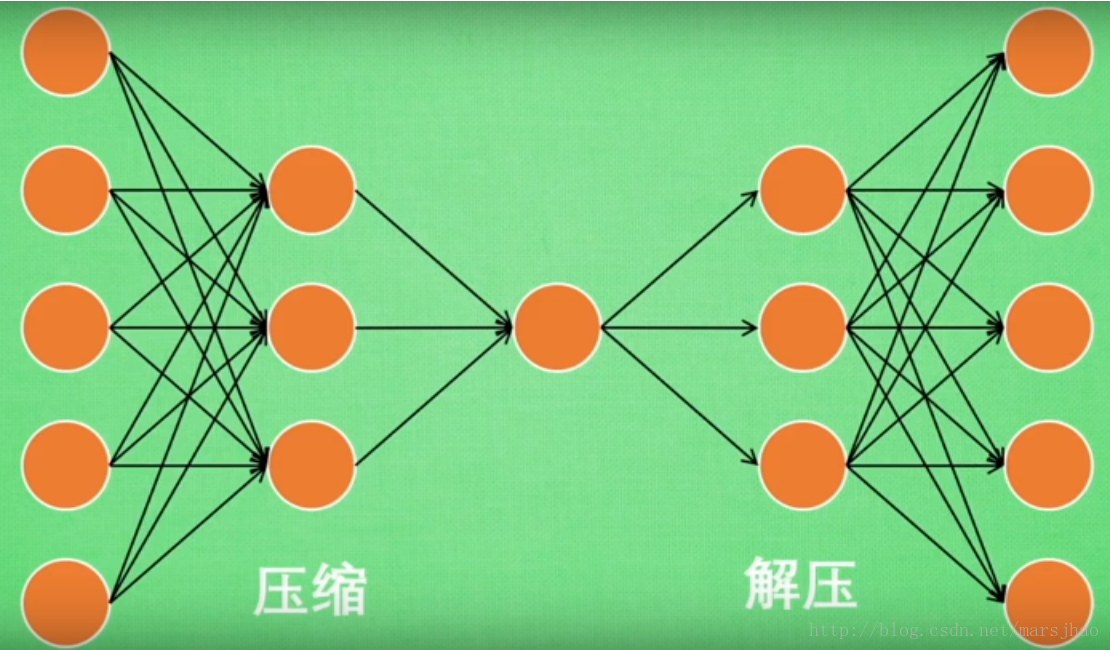
二、模型实现
1. AutoEncoder
首先在MNIST数据集上,实现特征压缩和特征解压并可视化比较解压后的数据与原数据的对照。
先看代码:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 导入MNIST数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=False)
learning_rate = 0.01
training_epochs = 10
batch_size = 256
display_step = 1
examples_to_show = 10
n_input = 784
# tf Graph input (only pictures)
X = tf.placeholder("float", [None, n_input])
# 用字典的方式存储各隐藏层的参数
n_hidden_1 = 256 # 第一编码层神经元个数
n_hidden_2 = 128 # 第二编码层神经元个数
# 权重和偏置的变化在编码层和解码层顺序是相逆的
# 权重参数矩阵维度是每层的 输入*输出,偏置参数维度取决于输出层的单元数
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input])),
}
# 每一层结构都是 xW + b
# 构建编码器
def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









