







3.多变量线性回归 (Linear Regression with multiple variable)
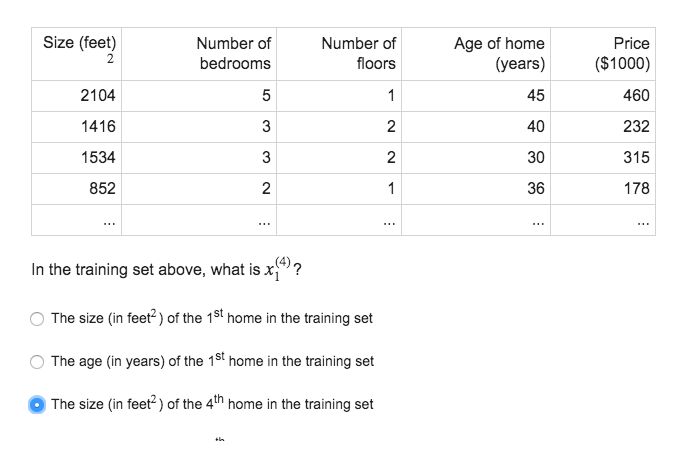
3.1 多维特征(Multiple Features)
- n 代表特征的数量
- x(i) 代表第 i 个训练实例,是特征矩阵中的第 i 行,是一个向量(vector)。
- x(i)j 代表特征矩阵中第 i 行的第 j 个特征,也就是第 i 个训练实例的第 j 个特征。
多维线性方程:
hθ=θ0+θ1x+θ2x+...+θnx
这个公式中有 n+1 个参数和 n 个变量,为了使得公式能够简化一些,引入
x0
=1, 所以参数
θ
和训练样本
X
都是n+1 纬的向量
X=⎛⎝⎜⎜⎜⎜x0x1⋮xn⎞⎠⎟⎟⎟⎟
多维线性方程 简化为:
hθ=θTX
3.2 多变量梯度下降(Gradient descent for multiple variables)
cost function :
J(θ)=12m∑1m(hθ(x(i))−y(i))2
在 Octave 中,写作: J = sum((X * theta - y).^2)/(2*m);梯度下降公式:
θj:=θj−α∂∂θjJ(θ0,θ1)=θj−α1m∑1m((hθ(x(i))−y(i))⋅x(i)j)
在 Octave 中,写作:
theta=theta−alpha/m∗X′∗(X∗theta−y);

3.3 特征缩放(feature scaling)
以房价问题为例,假设我们使用两个特征,房屋的尺寸和房间的数量,尺寸的值为 0- 2000 平方英尺,而房间数量的值则是 0-5,绘制代价函数的等高线图,看出图像会显得很扁,梯度下降算法下降的慢,而且可能来回震荡才能收敛。

mean normalization
解决的方法是尝试将所有特征的尺度都尽量归一化到-1 到 1 之间。最简单的方法是令
xi−μi
代替
xi
,使得特征的平均值接近0(
x0
除外) :
其中  μn 是平均值, sn 是标准差 sn 或特征范围 max(xi)−min(xi)

3.4 学习率(Learning rate)
- 确保梯度下降working correctly
绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。下降说明正常
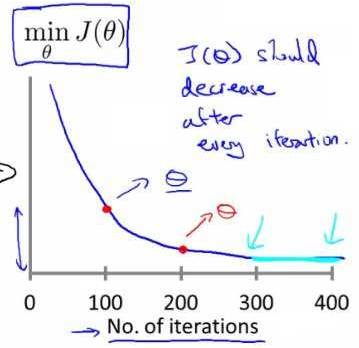
若增大或来回波动,可能是 α 过大

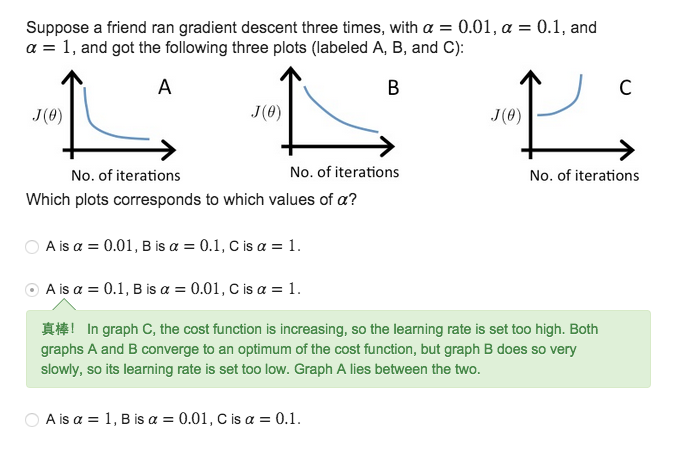
2.如何选取
α
先在10倍之间取,找到合适的区间后,在其中再细化为3倍左右(log)
We recommend trying values of the learning rate α on a log-scale, at multiplicative steps of about 3 times the previous value
α=…,0.001,0.01,0.1,1,…
α=…,0.001,0.03,0.01,0.03,0.1,0.3,1,…
3.5 多项式回归(Features and Polynomial Regression)
房价预测问题
已知x1=frontage(临街宽度),x2=depth(纵向深度),则
hθ=θ0+θ1x1+θ2x2
若用 x=frontage*depth=area(面积),则
hθ=θ0+θ1x
会得到更有意义的回归方程
线性回归并不适用于所有数据,有时我们需要曲线来适应我们的数据,比如一个二次方模型或三次方模型(考虑到二次方程的话总会到最高点后随着size↑,price↓,不合常理;因此选用三次方程进行拟合更合适。):
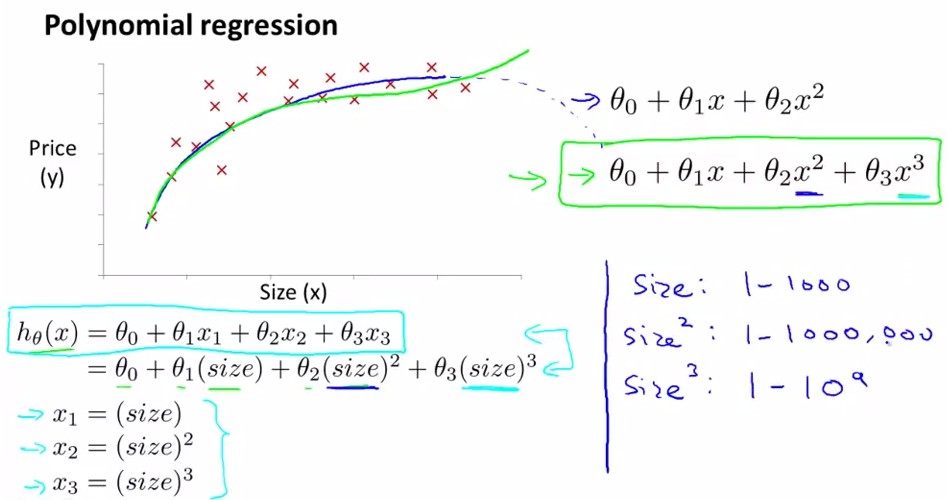
或采用第二个式子:
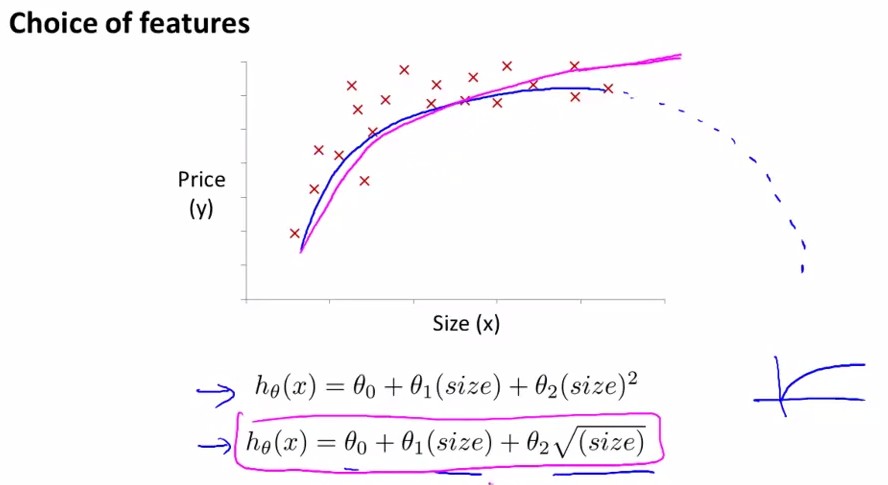
特征归一化很重要,使得不同feature之间有可比性

3.6 正规方程(Normal Equation)
之前用梯度下降算法,但是对于某些线性回归问题,正规方程方法更好。
要找到使cost function
J(θ)
最小的θ,就是找到使得导数取0时的参数θ:
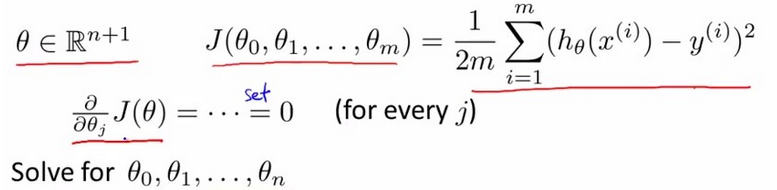
X是m×(n+1)的矩阵,y是m×1的矩阵,正规方程(Normal Equation):
θ=(XTX)−1XTy
在 Octave 中,正规方程写作:
pinv(X′∗X)∗X′∗y
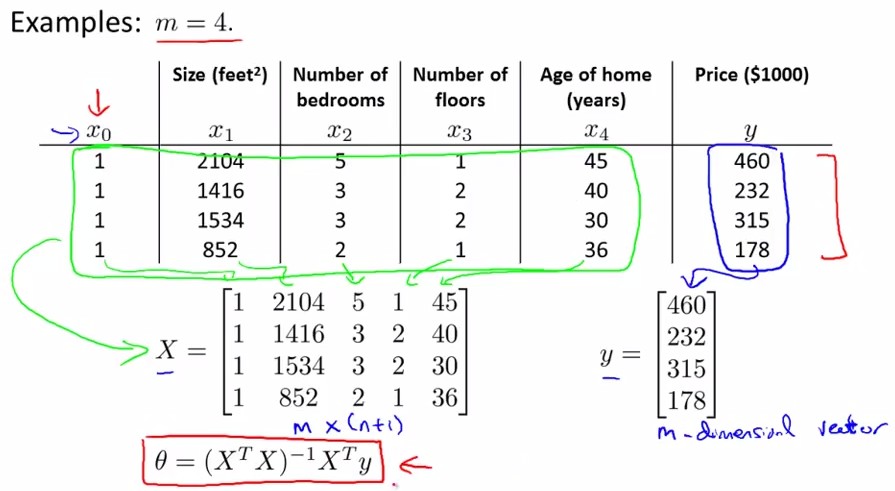
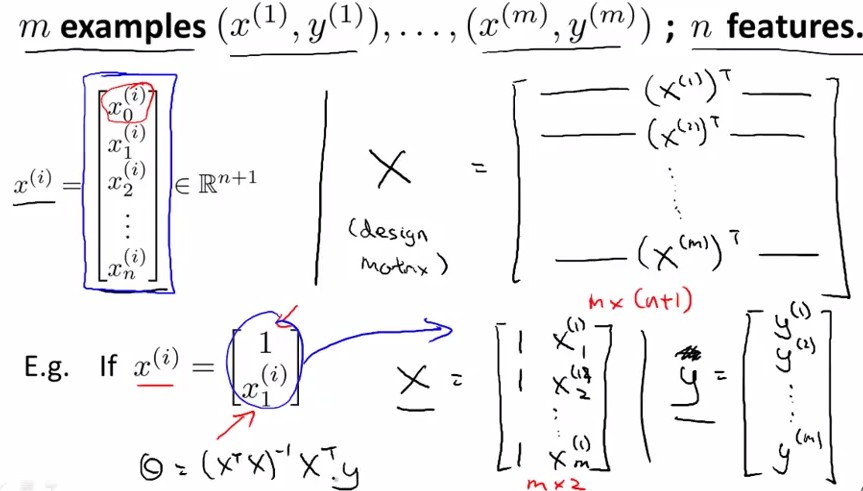
注:对于那些不可逆的矩阵(通常是因为特征之间不独立,或特征数量大于训练集的数量),正规方程方法是不能用的。
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率α | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量n大时也能较好适用 | 如果特征数量n较大则运算代价大,因为 (XTX)−1 的计算时间复杂度为 O(n3)(当 n < 10000 时还是可以接受的) |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
| 需要特征值归一化 | 不需要 |
3.7 练习



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









