







转载请注明原文地址:http://blog.csdn.net/mxm691292118/article/details/50996938
我把Android重难点和读书笔记都整理在github上:https://github.com/miomin/AndroidDifficulty
如果你觉得对你有帮助的话,希望可以star/follow一下哟,我会持续保持更新。
一、JVM内存分块
每一个进程会对应一个JVM实例,JVM在执行Java程序时,会将该进程获取到的内存划分成不同的数据块,这些区域有各自不同的用途和生命周期,参考《深入理解JVM虚拟机》,总结出以下结论:
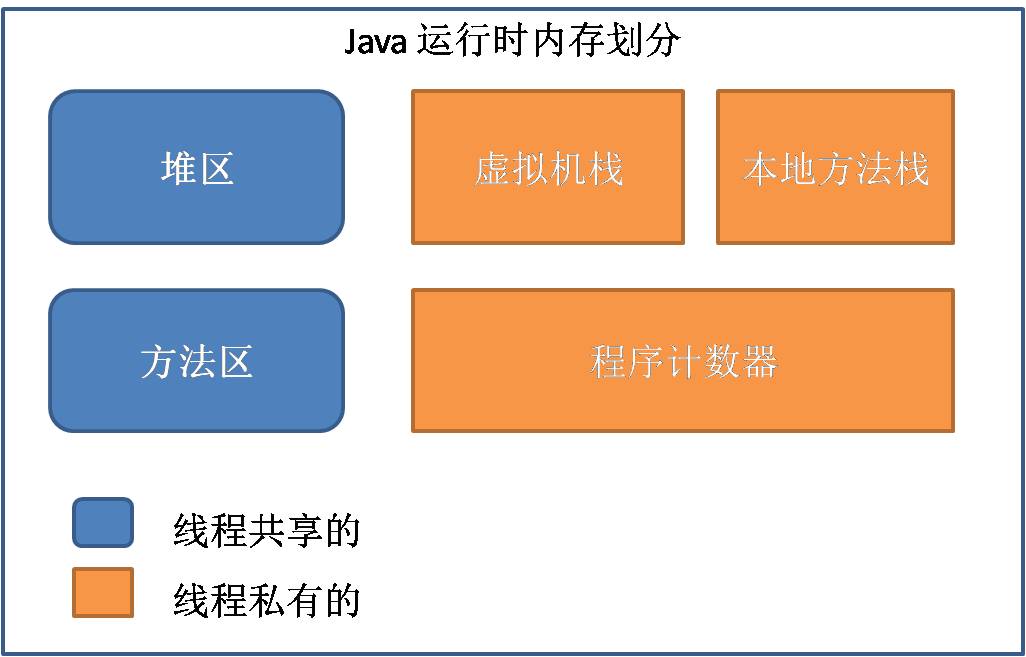
- (1)PC:每个线程有独立的PC,PC的值指向程序即将执行的下一条指令的地址。
- (2)JVM Stack:每个线程都拥有一个,每个方法在执行时都会创建一个栈帧,存储所有的局部变量,返回地址等等。(局部变量的对象的引用存在Stack中,对象实例存在Java Heap中)
- (3)Native Method Stack:与Java虚拟机栈提供的服务一致,但是是为Native方法服务。
- (4)Java Heap:所有线程共享,存储类的所有成员变量(成员变量的对象的引用和实例都在Java Heap中)。Java Heap是GC的主要区域。
- (5)静态存储区(方法区):所有线程共享,存储已经被JVM加载的Class的信息、常量、static变量、编译成的字节码。
(6)Native Heap/直接内存区:直接内存区不是 JVM 管理的内存区域的一部分,而是其之外的。NIO就是使用Native函数库直接分配Native heap的内存,通过一个存储在Java heap中的DirectByteBuffer对象作为对该块Native heap内存的引用进行操作,提高流畅度,避免Java heap和Native heap中来回复制数据。Native heap的分配不受Java heap大小的限制,但是收到本机总内存的限制。(在Android3.0之前,Bitmap存储在Native heap中,Android3.0之后,存储在Java heap中)
在Android2.x中,Native heap会分配到每个JVM实例;在Andorid3.0以后,所有进程共享同一个Native heap,大小只受机器总内存(包括RAM以及SWAP区或者分页文件)的大小的影响。
特别注意:String和Integer、Long等特殊类型,具有不可变性,编译时就会分配内存,是存储在常量池中(常量池是方法区的一部分)。
String源代码:
public final class String implements Serializable, Comparable<String>, CharSequence {
private static final char REPLACEMENT_CHAR = (char) 0xfffd;
......
}- Integer源代码:
public final class Integer extends Number implements Comparable<Integer> {
/**
* The int value represented by this Integer
*/
private final int value;
......
}- 可以看到,String和Integer内部的值实际都是存储在一个final变量中,所以内存是分配在常量池。由于这个特性,String是不可变的,用String做字符串拼接操作,会留下副本,产生新的对象。
二、new一个对象的过程
- (1)先检查该对象代表的类有没有被加载过,如果没有,必须先进行类的加载过程
- (2)从Java堆中划分一块内存出来给对象使用
- (3)先后执行static代码块(先父后子)
- (4)执行构造代码块(先父后子)
- (4)递归的调用Class的构造器,从Object到该对象的父类的构造函数(析构相反)
- (5)对对象中的成员显示初始化(被分配的内存全部赋值为0,或者默认值)
三、垃圾收集
虽说JVM的GC是自动化的,但是为了排查各种内存溢出、内存泄露的问题,需要对GC技术做进一步了解。《深入理解JVM虚拟机》书中提到,垃圾回收应该思考三件事情:
下面就这些问题做一些思路上的整理,我们这里主要讨论的对象是Java Heap。
1、如何判断对象已死
(1)引用计数法
- 这是大部分教科书给出的答案,给对象添加一个计数器,每当在一个地方引用它,就将引用+1,引用失时,就将引用-1;GC的对象就是引用为0的对象。
但是引用计数法有一个缺点,当对象之间被循环引用的时候,就算是没有实际用途的对象,也不会被回收掉。
(下面说道的可达性算法就可以很好地解决这个缺陷)
(2)可达性分析算法
- 可达性算法的原理是通过一些GC Roots实现,在内存中不能找到GC Roots的通路的对象,就是需要被回收的对象。
- 一般来说,考虑选取static变量,老年代对象,栈帧中引用类型的变量。
2、引用类型
在JDK1.2之后,Java对引用类型进行扩充,分为强引用(Strong)、软引用(Soft)、弱引用(Weak)、虚引用(Phantom),下面逐一分析。
- 强引用(Strong Reference):普遍存在的引用,使用Object object = new Object()的方式new出来的对象就是强引用。
- 软引用(Soft Reference):在内存即将不够用时,垃圾收集器会将软引用的对象回收掉。
- 弱引用(Weak Reference):当触发了一次GC操作时,不管内存是否够用,都会回收掉弱引用的对象。
- 虚引用(Phantom Reference):是否存在虚引用,不影响其生命周期,相当于没有被引用。使用虚引用的原因是为了在该对象被回收时收到通知。
3、GC算法
(1)标记清除法(Mark-Sweep):分为标记和清除两个阶段。
- 标记阶段:标记所有可以访问的对象(也就是被引用的对象)
- 清除阶段:扫描所有对象,将未标记的对象进行释放
- 缺点:效率不高,而且容易产生内存碎片。
- 用途:老生代垃圾收集
(2)节点拷贝法(Copying collection):在程序运行时分配两个heap,当一个heap用完时,触发GC,将存活的对象从运行时heap拷贝到用于GC的heap。释放掉残留在运行时heap中的对象,然后将两个heap互换角色。
- 优点:不会产生内存碎片
- 缺点:可用内存缩小为原来的一半
- 用途:回收新生代对象
- 改进:一般来说,会把新生代划分成一块Eden和两块较小的Survivor(HotSpot虚拟机默认每块Survivor为Eden的1/8),每次只使用Eden和其中一块Survivor存放存活的对象。(这部分的详细讲解在我的另一篇博文《深入浅出JVM垃圾收集》中)
(3)标记整理法(Mark-Compact):
- 用途:回收老年代对象
- 优点:无内存碎片
- 算法过程与“标记-清除”法一样,但是后续会让存活对象向内存的一端移动,然后清理边界以外的内存,不会产生内存碎片。
(4)分代收集算法(Generational Collection):















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









