






本文要阅读的论文来自数据挖掘领域的顶级会议KDD-2016.
论文介绍了一种Graph representation方法 得益于CNN以及Seq2seq等模型,深度学习在图像和自然语言处理等领域有很好的应用。然而在涉及到图(有向图,无向图)结构的应用比如社交网络,如何去对图建模,仍旧是一个问题。该论文提供了一种很好的建模思路。作者受到word2vec的启发,提出了node2vec 一种对于图中的节点使用向量建模的方法。在本文的最后,我会列出一些我所知的Graph representation相关的论文。
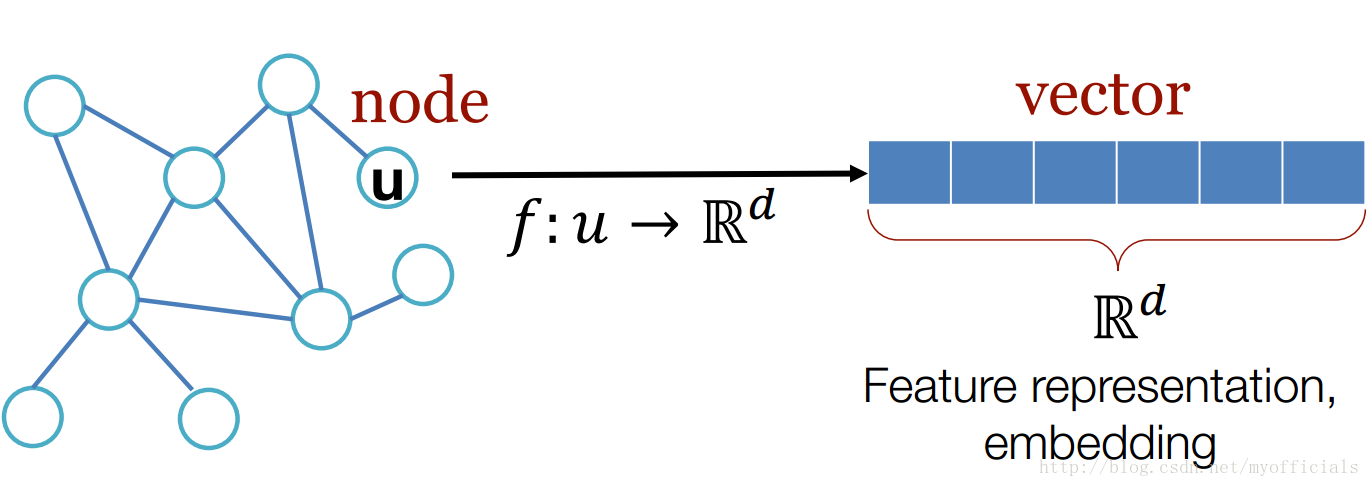
node2vec: Scalable Feature Learning for Networks
论文arXiv地址为:https://arxiv.org/abs/1607.00653
作者提供的博客地址为:http://snap.stanford.edu/node2vec/
源代码GitHub地址:https://github.com/snap-stanford/snap/tree/master/examples/node2vec
作者直接使用了word2vec中的skip-gram作为基础模型,本文不会去说word2vec模型,把相关资料列举下
- google两篇关于word2vec的论文:
[1]Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013.
[2]Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013. - google word2vec 项目地址:https://code.google.com/p/word2vec/
除此之外,github上有许多word2vec的开源代码,网上有很多word2vec的详细的资料。
Node2vec的主要工作以及创新点就是如何去把一张图来当作一篇文本,把图中的节点表示成文本中的token。然后调用现成的word2vec模型来生成向量。而图不同于文本的特点是,文本是一个线性的序列,图是一个复杂的结构。
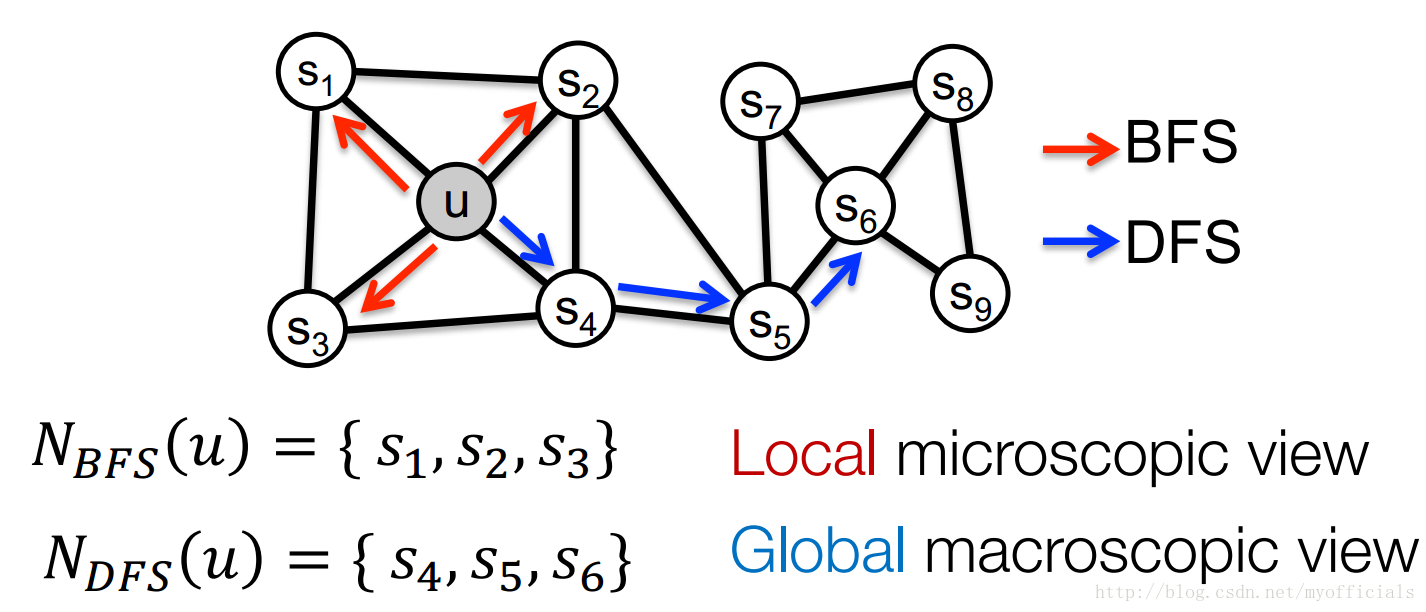
在这篇论文之前有人提出了Deepwalk的方法,这种方法基于BFS和DFS的方法来进行随机游走,为node2vec提供了很好的思路。node2vec结合BFS和DFS的方法来对图中的节点进行采样,如图所示。BFS 采样得到的是Local microscopic view, 而DFS得到的是Global macrooscopoc view。
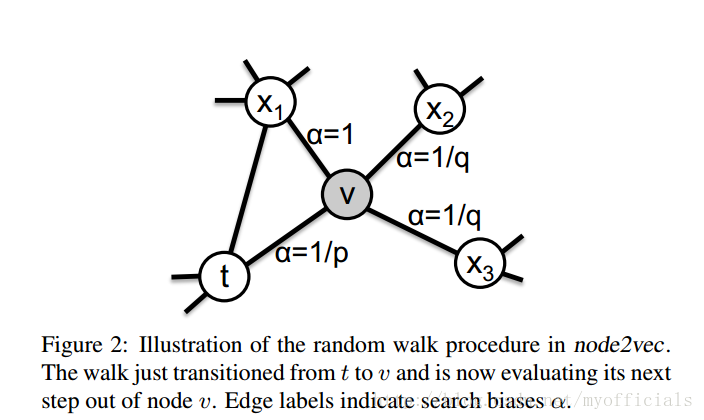
作者在Deepwalk的基础上提出了自己的启发式的方法2nd-order random walks,具体而言定义了Random Walks以及两个超参数。记开始节点为
c0=u
,随机游走选择下一个节点的公式为:
即若图E存在边
(v,x)
,则以概率
πvxZ
选择下一节点x,其中
πvx
是非正则化的v到x的转移概率,
Z
是正则化常数。 论文说道比较简单的
2nd-order random walks对
πvx=wvx
进行改进为
π=αpq(t,x)⋅wv,x
,其中
对于参数 p 和
- Return parameter
p
:
Return back to the previous node - In-out parameter
q :
Moving outwards (DFS) vs. inwards (BFS)
Intuitively, q is the “ratio” of BFS vs. DFS
其实很简单,如图
当下一个节点x 与前一个节点 t 和当前节点v 等距时, α=1 ; 当下一个节点 x 是上一个节点时,α=1p ;在其他情况下, α=1q .
到目前为止,用于构建“文本”的2nd-order random walks已经介绍完了。接下来,我们对核心代码进行下解读。
源码主要用到了两个个python库:
import networkx as nx
from gensim.models import Word2Vecnetworkx用来从文本中读取图(包括有向图和无向图), gensim中的word2vec用来对2nd-order random walks产生的”文本“,生成node2vec。
如下是main函数中的内容:
def main(args):
'''
Pipeline for representational learning for all nodes in a graph.
'''
nx_G = read_graph() #从文本中读取图
G = node2vec.Graph(nx_G, args.directed, args.p, args.q)#args.directed bool型用来标识
#(有向图,无向图), args.p,args.q分别是参数p和q, 这一步是生成一个图对象
G.preprocess_transition_probs()#生成每个节点的转移概率向量
walks = G.simulate_walks(args.num_walks, args.walk_length)#随机游走
learn_embeddings(walks)#walks是随机游走生成的多个节点序列,被当做文本输入,调用Word2Vec模型,生成向量learn_embeddings函数如下:
def learn_embeddings(walks):
'''
Learn embeddings by optimizing the Skipgram objective using SGD.
'''
walks = [map(str, walk) for walk in walks]
model = Word2Vec(walks, size=args.dimensions, window=args.window_size, min_count=0, sg=1, workers=args.workers, iter=args.iter)#Word2Vec是gensim.models.Word2vec具体参考gensim的API
model.save_word2vec_format(args.output)
returnsimulate_walks函数:
def simulate_walks(self, num_walks, walk_length):#num_walks每个节点作为开始节点的次数
#walk_length每次游走生成的节点序列的长度
'''
Repeatedly simulate random walks from each node.
'''
G = self.G
walks = []
nodes = list(G.nodes())
print 'Walk iteration:'
for walk_iter in range(num_walks):
print str(walk_iter+1), '/', str(num_walks)
random.shuffle(nodes)
for node in nodes:
walks.append(self.node2vec_walk(walk_length=walk_length, start_node=node))
#node2vec_walk为一次随机游走,用于生成一次随机游走的序列
return walksnode2vec_walk函数:
def node2vec_walk(self, walk_length, start_node):
'''
Simulate a random walk starting from start node.
'''
G = self.G
alias_nodes = self.alias_nodes
alias_edges = self.alias_edges
walk = [start_node]
while len(walk) < walk_length:#序列长度为walk_length
cur = walk[-1]#current node
cur_nbrs = sorted(G.neighbors(cur))#neihbor nodes of current node
if len(cur_nbrs) > 0:
if len(walk) == 1:
walk.append(cur_nbrs[alias_draw(alias_nodes[cur][0], alias_nodes[cur][1])])
'''
alias_draw(alias_nodes[cur][0], alias_nodes[cur][1])]函数是以论文中转移概率公式P来选择下一个节点,返回值是下一个节点的index。这部分用到的函数alias_draw以及它调用的alias_setup函数是一种概率采样方法,具体见作者提到的https://hips.seas.harvard.edu/blog/2013/03/03/the-alias-method-efficient-sampling-with-many-discrete-outcomes/
'''
else:
prev = walk[-2]
next = cur_nbrs[alias_draw(alias_edges[(prev, cur)][0],
alias_edges[(prev, cur)][1])]
walk.append(next)
else:
break
return walkP(ci=x|ci−1=v) 的生成函数
def get_alias_edge(self, src, dst):#src是随机游走序列中的上一个节点,dst是当前节点
'''
Get the alias edge setup lists for a given edge.
'''
G = self.G
p = self.p
q = self.q
unnormalized_probs = []
for dst_nbr in sorted(G.neighbors(dst)):
if dst_nbr == src:
unnormalized_probs.append(G[dst][dst_nbr]['weight']/p)#加权后的转移概率
elif G.has_edge(dst_nbr, src):
unnormalized_probs.append(G[dst][dst_nbr]['weight'])#同上
else:
unnormalized_probs.append(G[dst][dst_nbr]['weight']/q)#同上
norm_const = sum(unnormalized_probs)
normalized_probs = [float(u_prob)/norm_const for u_prob in unnormalized_probs]
return alias_setup(normalized_probs)#alias_setup用来依据已有的概率来生成抽样函数,抽样函数被alias_draw用来选择下一个节点
def preprocess_transition_probs(self):
'''
Preprocessing of transition probabilities for guiding the random walks.
'''
G = self.G
is_directed = self.is_directed
alias_nodes = {}
for node in G.nodes():
unnormalized_probs = [G[node][nbr]['weight'] for nbr in sorted(G.neighbors(node))]#获取边的weight
norm_const = sum(unnormalized_probs)
normalized_probs = [float(u_prob)/norm_const for u_prob in unnormalized_probs]#正则化权重weight
alias_nodes[node] = alias_setup(normalized_probs)
alias_edges = {}
triads = {}
if is_directed:
for edge in G.edges():
alias_edges[edge] = self.get_alias_edge(edge[0], edge[1])
else:
for edge in G.edges():
alias_edges[edge] = self.get_alias_edge(edge[0], edge[1])
alias_edges[(edge[1], edge[0])] = self.get_alias_edge(edge[1], edge[0])
self.alias_nodes = alias_nodes
self.alias_edges = alias_edges
return
其中self.alias_nodes仅仅用在序列中的start node选择下一个节点的时候,因为此时 αpq(t,x) 都是1, self.alias_edges 用于其他节点来选择下一个节点的时候,self.get_alias_edge(edge[0], edge[1])中edge[0]是前一个节点,edge[1]是当前节点。
node2vec相关文献:
[1]Perozzi B, Alrfou R, Skiena S. DeepWalk: online learning of social representations[J]. 2014:701-710.
[2]Zitnik M, Leskovec J. Predicting multicellular function through multi-layer tissue networks.[J]. 2017.
[3]Hamilton W L, Ying R, Leskovec J. Inductive Representation Learning on Large Graphs[J]. 2017.
[4]Hamilton W L, Ying R, Leskovec J. Representation Learning on Graphs: Methods and Applications[J]. 2017.
文献[4]是篇综述
Graph Presentation相关文献:
[1]Cao S, Lu W, Xu Q. Deep neural networks for learning graph representations[C]// Thirtieth AAAI Conference on Artificial Intelligence. AAAI Press, 2016:1145-1152.
[2]Niepert M, Ahmed M, Kutzkov K. Learning convolutional neural networks for graphs[J]. 2016:2014-2023.
[3]Kipf T N, Welling M. Semi-Supervised Classification with Graph Convolutional Networks[J]. 2016.
本文完














 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









