






背景
图是一种描述复杂数据的模型(任意的节点数量、复杂的关系)
SNAP数据集:Standord Large Network Dataset Collection 其中包含了许多不同类型的数据集。
图研究涵盖:节点分类(node classification)、边预测(link prediction)、社群检(community detection)、网络营销(viral marketing)、网络相似度(network similarity)
节点分类任务:Macro-F1,Micro-F1
Macro-F1 : 分别计算每个类别的F1,然后做平均
Micro-F1:通过先计算总体的TP,FN和FP的数量,再计算F1
图学习领域:人工特征提取->特征筛选->输入分类器 (基于特征工程)
深度学习领域:特征工程和分类集成于一体(基于神经网络)
图的构建
- The fully connected graph:任意两点之间都有边,可计算欧氏距离来建成一条边,但是算法时间复杂度很高
- The e-neighborhood graph:距离大于e,就不创建边
- k-nearest neighbor graph:对距离最近的k个点再建边,但是存在误差
- 根据实际应用问题建图
- 根据研究问题人工合成图
图的应用
推荐系统:Billion- scale Commodity Embedding for E-commerce Recommendation in Alibaba (KDD 2018)
POG:Personalized Outfit Generation for Fashion Recommendation at Alibaba iFashion(KDD 2019)
…
node2vec算法详解(核心部分)
图的存储:邻接矩阵和邻接表
图学习的目的是希望学到每个节点的表征
优化目标:类似skip-gram
独立性假设:
邻居节点之间互相不影响
负采样
SGD优化方法
论文核心:通过随机游走策略生成
N
s
(
u
)
N_s(u)
Ns(u)
max
f
∑
u
∈
V
log
Pr
(
N
S
(
u
)
∣
f
(
u
)
)
\max _{f} \sum_{u \in V} \log \operatorname{Pr}\left(N_{S}(u) \mid f(u)\right)
maxf∑u∈VlogPr(NS(u)∣f(u))
其中右边就是softmax:
Pr
(
f
(
n
i
)
∣
f
(
u
)
)
=
exp
(
f
(
n
i
)
⋅
f
(
u
)
)
∑
v
∈
V
exp
(
f
(
v
)
⋅
f
(
u
)
)
\operatorname{Pr}\left(f\left(n_{i}\right) \mid f(u)\right)=\frac{\exp \left(f\left(n_{i}\right) \cdot f(u)\right)}{\sum_{v \in V} \exp (f(v) \cdot f(u))}
Pr(f(ni)∣f(u))=∑v∈Vexp(f(v)⋅f(u))exp(f(ni)⋅f(u))
然后再加上外面的log,公式(1)实际上可以写为(左边是分母,右边是分子,左边忽略一个常数系数):
max
f
∑
u
∈
V
[
−
log
Z
u
+
∑
n
i
∈
N
S
(
u
)
f
(
n
i
)
⋅
f
(
u
)
]
\max _{f} \sum_{u \in V}\left[-\log Z_{u}+\sum_{n_{i} \in N_{S}(u)} f\left(n_{i}\right) \cdot f(u)\right]
maxf∑u∈V[−logZu+∑ni∈NS(u)f(ni)⋅f(u)]
其中,
Z
u
=
∑
v
∈
V
exp
(
f
(
v
)
⋅
f
(
u
)
)
Z_{u}=\sum_{v \in V} \exp (f(v) \cdot f(u))
Zu=∑v∈Vexp(f(v)⋅f(u)),要对每个顶点来进行计算,实际上计算复杂度还蛮高,论文借鉴了Word2Vec中的负采样和层次softmax来对这项作了优化。
Word2Vec中的负采样是用词频高的作为负样本,这里是用顶点的度当做词频进行负采样。度越高采样概率越大。
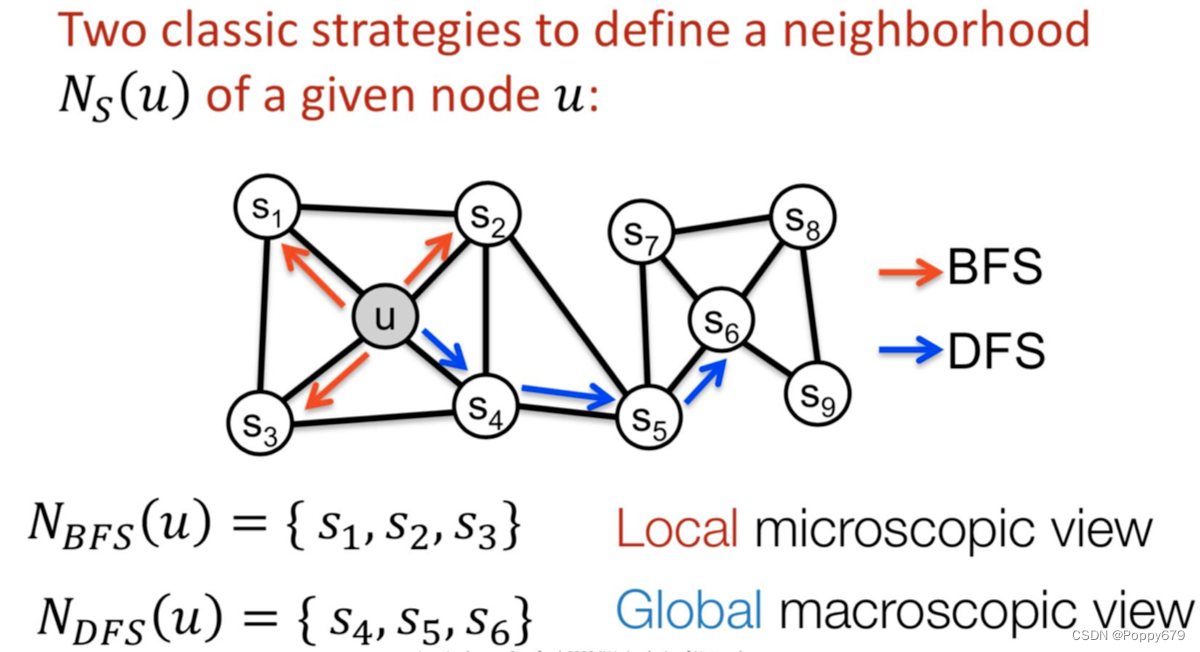
bfs & dfs
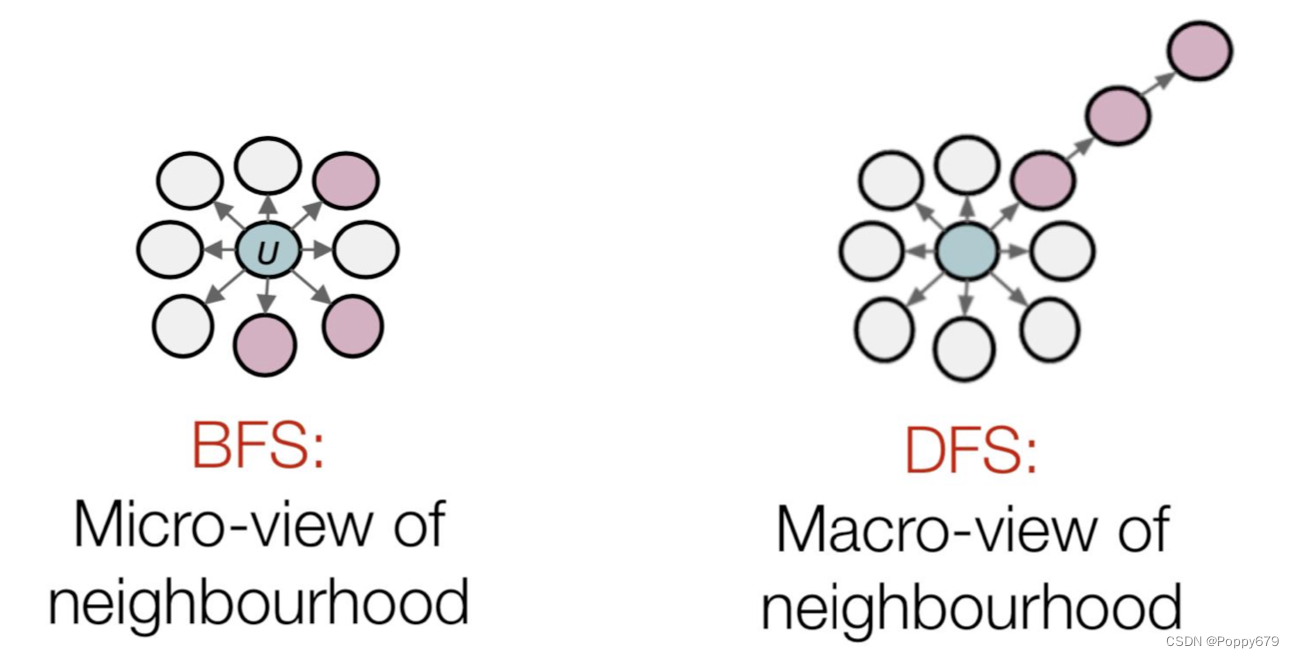
BFS:局部特征(1-hop采样)
DFS:全局特征(k-hop采样)
BFS算法
数据结构:queue(队列);FIFO先进先出
在论文中认为BFS搜索语义-结构相似性(structure equivalence)

DFS算法
数据结构:stack(栈);先出后进
在论文中认为DFS搜索语义-同质/社群相似性(homophily)–DFS往深了搜索,但是无论如何搜索都离不开自己的社群,因此体现同质性。

biased random walk有偏的随机游走算法
传统的random walk算法不具备探索节点不同类型邻域的能力,但是作者认为网络同时具备结构和同质相似性:
P
(
c
i
=
x
∣
c
i
−
1
=
v
)
=
{
π
v
x
Z
if
(
v
,
x
)
∈
E
0
otherwise
P\left(c_{i}=x \mid c_{i-1}=v\right)= \begin{cases}\frac{\pi_{v x}}{Z} & \text { if }(v, x) \in E \\ 0 & \text { otherwise }\end{cases}
P(ci=x∣ci−1=v)={Zπvx0 if (v,x)∈E otherwise
其中
π
v
x
\pi_{v x}
πvx就是vx上的权重
w
v
x
w_vx
wvx, 当
w
v
x
=
1
w_vx=1
wvx=1表示无权图,
Z
Z
Z表示将概率归一化
在有偏随机游走算法中,当前位置v的下一时刻访问节点的是由其上一个节点决定,如图所示v的下一个访问节点由上一个时刻节点t来决定。
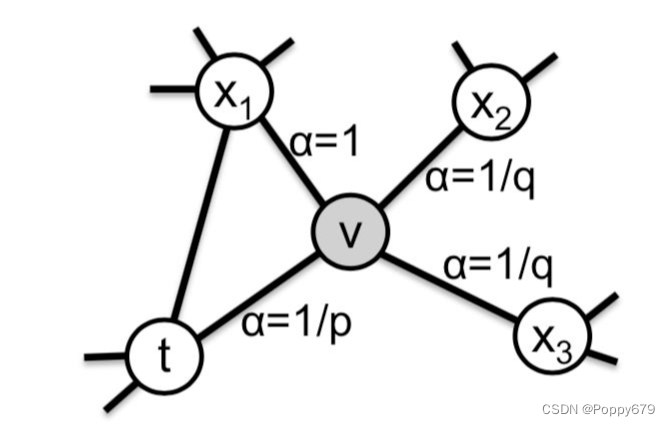
公式:
α
p
q
(
t
,
x
)
=
{
1
p
if
d
t
x
=
0
1
if
d
t
x
=
1
1
q
if
d
t
x
=
2
\alpha_{p q}(t, x)= \begin{cases}\frac{1}{p} & \text { if } d_{t x}=0 \\ 1 & \text { if } d_{t x}=1 \\ \frac{1}{q} & \text { if } d_{t x}=2\end{cases}
αpq(t,x)=⎩⎪⎨⎪⎧p11q1 if dtx=0 if dtx=1 if dtx=2
d
t
x
d_{t x}
dtx: t,x之间的最短路径
d
t
x
d_{t x}
dtx: {0, 1, 2}
p, q控制了从源点(v)离开邻居的快慢
根据参数
α
p
q
(
t
,
x
)
\alpha_{p q}(t, x)
αpq(t,x)来控制随机游走的方向,即在调整q时,节点之间的距离就发生变化,从而改变访问策略(DFS或BFS),调节p的值是回溯的作用,当p越小的时候,就倾向返回t。
π
v
x
=
α
p
q
(
t
,
x
)
⋅
w
v
x
\pi_{v x}=\alpha_{p q}(t, x) \cdot w_{v x}
πvx=αpq(t,x)⋅wvx
对超参数的理解总结:
p值大:倾向不回溯,降低了2-hop的冗余度;p值小,倾向回溯,采样序列集中在起始点的周围
q>1: BFS- behavior,局部特征; q<1: DFS-behavior,往外探索,全局特征
node2vec算法

概率采样alias sampling

论文关键点:
基于word2vec训练框架
基于random walk 产生训练序列
性能通过alias sampling采样进行优化
实验创新点:
讨论了BFS、DFS的语意
设计了有便随机游走biased random network















 1578
1578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









