







MapReduce/Hadoop
MapReduce是目前云计算中最广泛使用的计算模型,由Google于2004年提出,谷歌关于云计算有三篇著名的论文:
- 《Bigtable_A Distributed Storage System for Structured Data》
- 《MapReduce: Simplied Data Processing on Large Clusters》
- 《The Google File System》
论文下载地址:http://pan.baidu.com/s/1o6G8PGA
Hadoop是MapReduce的一个开源实现,核心框架有2个:HDFS和MapReduce,HDFS为海量数据提供存储,MapReduce为海量数据提供计算。
为什么会有MapReduce?
在MapReduce提出之前,编写并行分布式程序需要下列技术:
- Multi‐threading( 多线程编程)
- Socket programming(socket网络编程)
- Data distribution( 数据分发)
- Job distribution, coordination, load balancing(任务分发、协调、负载平衡)
- Fault tolerance( 容错性能)
- Debugging( 调试)
上面每个方面都需要学习和经验积累,要想编写并行分布式程序并不容易,需要非常有经验的程序员和调试技巧,调试分布式系统很花时间和精力。为了解决这一问题,提出来解决思路:
- 程序员写串行程序,编程序时不需要思考并行的问题,调试时只需要保证串行执行正确。
- 由系统完成并行分布式地执行,负责并行分布执行的正确性和效率
但是这样也带来问题:牺牲了程序的功能。直接进行并行分布式编程,可以完成各种各样丰富的功能,而一个编程模型实际上是限定了程序的功能类型。因此要求系统的编程模型必须有代表性,必须代表一大类重要的应用才有生命力。
MapReduce的核心思想是分而治之,把大的任务分成若干个小任务,并行执行小任务,最后把所有的结果汇总。
MapReduce数据模型
MapReduce的数据模型:
<key, value>- 数据由一条一条的记录组成
- 记录之间是无序的
- 每一条记录有一个key,和一个value
- key: 可以不唯一
- key与value的具体类型和内部结构由程序员决定,系统基
本上把它们看作黑匣
图解:
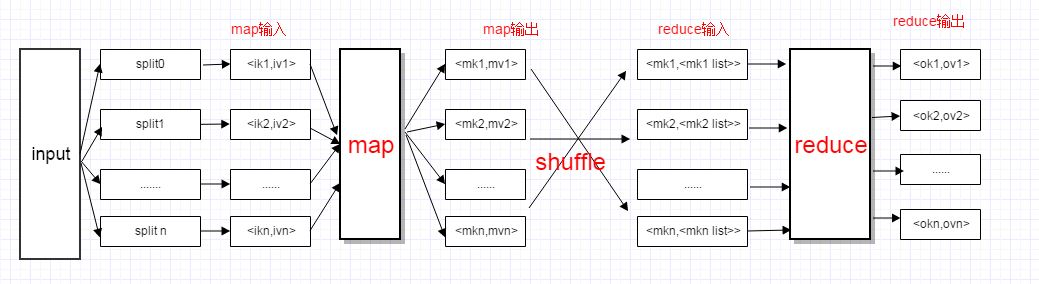
下面以wordcount为例说明MapReduce计算过程:
输入文本:
hello world hadoop hdfs hadoop hello hadoop hdfsmap输出:
<hello,1>
<world,1>
<hadoop,1>
<hdfs,1>
<hadoop,1>
<hello,1>
<hadoop,1>
<hdfs,1>shuffle(洗牌)过程把key值相同的value合并成list作为reduce输入:
<hello,<1,1>>
<world,1>
<hadoop,<1,1,1>>
<hdfs,<1,1>>reduce输出:
<hello,2>
<world,1>
<hadoop,3>
<hdfs,1>关于Wordcount运行例子可以参考hadoop helloworld(wordcount),代码解读博客园上有一篇很详细的文章Hadoop集群(第6期)_WordCount运行详解.
附wordcount源码:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
// This is the Mapper class
// reference: http://hadoop.apache.org/docs/r2.6.0/api/org/apache/hadoop/mapreduce/Mapper.html
//
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumCombiner
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
// This is the Reducer class
// reference http://hadoop.apache.org/docs/r2.6.0/api/org/apache/hadoop/mapreduce/Reducer.html
//
// We want to control the output format to look at the following:
//
// count of word = count
//
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,Text> {
private Text result_key= new Text();
private Text result_value= new Text();
private byte[] prefix;
private byte[] suffix;
protected void setup(Context context) {
try {
prefix= Text.encode("count of ").array();
suffix= Text.encode(" =").array();
} catch (Exception e) {
prefix = suffix = new byte[0];
}
}
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
// generate result key
result_key.set(prefix);
result_key.append(key.getBytes(), 0, key.getLength());
result_key.append(suffix, 0, suffix.length);
// generate result value
result_value.set(Integer.toString(sum));
context.write(result_key, result_value);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumCombiner.class);
job.setReducerClass(IntSumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// add the input paths as given by command line
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// add the output path as given by the command line
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











