







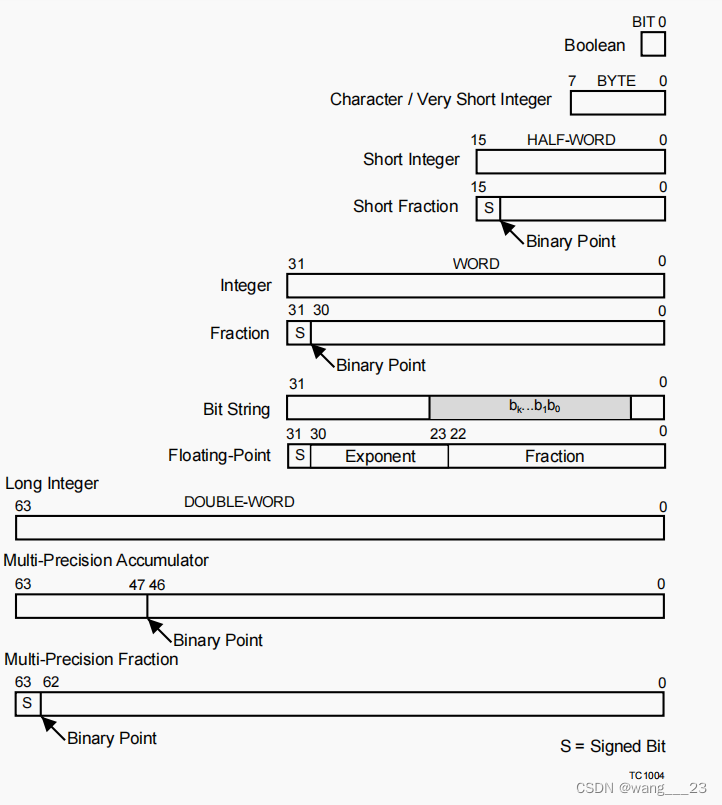
一、数据类型
1 、Boolean
布尔值为TRUE或FALSE:
TRUE是生成时的值1,测试时为非零。
位串是位的填充字段。位串由逻辑、移位和位字段指令产生和使用。FALSE是值0
布尔值作为比较和逻辑指令的结果产生,并在逻辑和条件跳转指令中用作源操作数。
2、 Bit String
位串是位的填充字段。位串由逻辑、移位和位字段指令产生和使用。
3、 Byte
字节是一个8位值,可用于字符或非常短的整数。没有特定的编码假设。
4 、Signed Fraction
该体系结构支持16位、32位和64位符号小数数据用于DSP算法。这种格式的数据值有一个高阶符号位,其中0表示正(+),1表示负(-),后面跟着一个隐含的二进制点和分数。因此,它们的值在[-1,1]的范围内。
5 、Address
地址是一个32位的无符号值。
6 、Signed and Unsigned Integers
有符号整数和无符号整数通常是32位。较短的有符号或无符号整数在从内存加载到寄存器时是符号扩展或零扩展到32位的。
Multi-precision
支持多精度整数,使用进位进行加减。整数被认为是移位和屏蔽操作的位字符串。多精度移位可以使用单精度移位和位域提取的组合来实现。
7 、IEEE-754 Single-Precision Floating-Point Number
根据核心体系结构的具体实现,协处理器硬件指令或对库的软件调用支持IEEE-754浮点数。
二、 数据格式
所有通用寄存器(GPRs)都是32位宽,大多数指令操作字(32位)值。当字节或半字数据元素从内存中加载时,它们会自动进行符号扩展或零扩展以填充寄存器。填充类型在加载指令中是隐式的。例如,LD.B加载带有符号扩展名的字节,或LD.BU加载带有0扩展名的字节。
支持的数据格式有:
位
字节:有符号,无符号
半字:有符号,无符号,分数
字:有符号,无符号,分数,浮点数
48位:有符号,无符号,分数
双字:有符号,无符号,分数
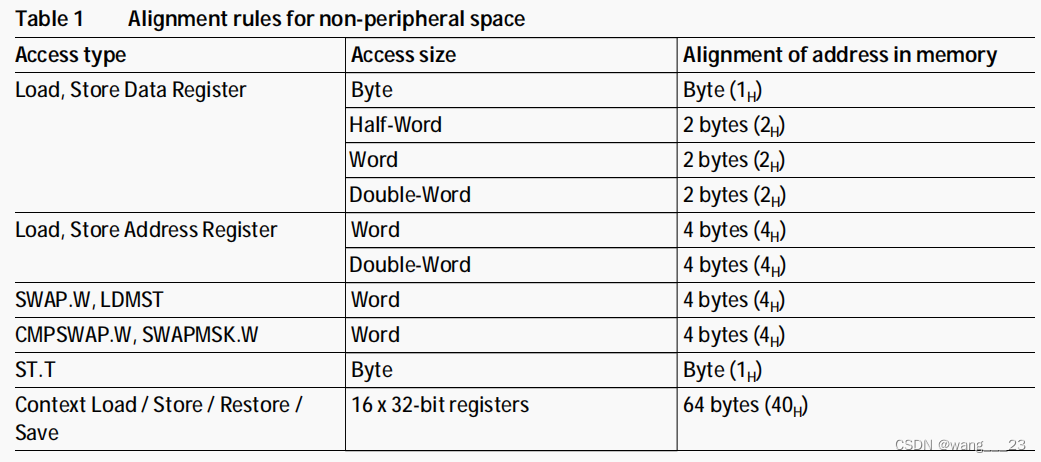
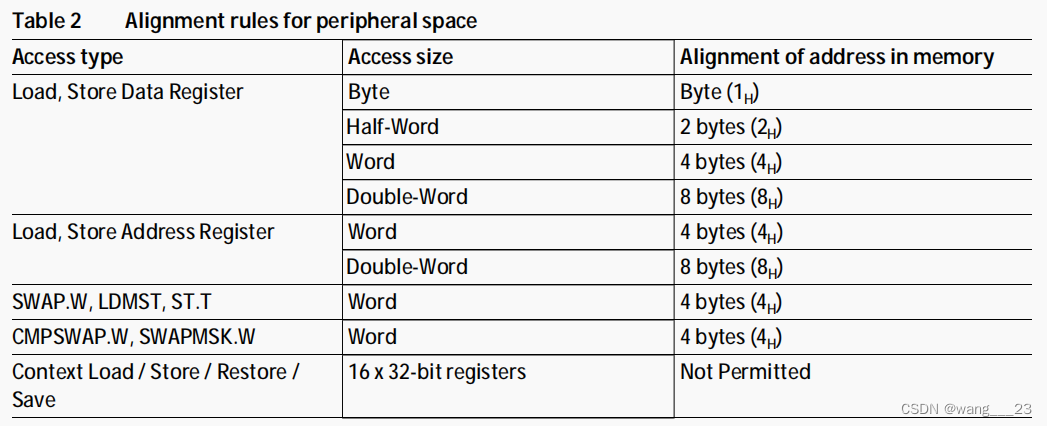
1、对齐要求
地址和数据的对齐要求不同。加载到地址寄存器或从地址寄存器存储的地址变量必须始终是word对齐的。
数据可以在任何半字边界上对齐,无论大小如何,除非下面注明。这便于在DSP应用程序中使用打包算术运算,允许在任何半字边界上加载或存储两个或四个打包的16位数据元素。
编程限制
有一些限制是程序员必须知道的,具体来说:
LDMST, CMPSWAP.W, SWAPMSK.W和SWAP.W指令要求它们的操作数与word对齐。
字节操作LD.B, ST.B, LD.BU, ST.T可以是字节对齐的。
所有进入外设空间的通道必须自然对齐。(双字访问可以是Word对齐)。
对齐规则
2 、Byte Ordering
数据内存和CPU寄存器以小端字节顺序存储数据(最低有效字节位于较低的地址)。下图说明了字节排序。小端内存引用一致地用于数据和指令。

三、内存模型
该架构的地址宽度为32位,可以访问多达4GBytes 的内存。地址空间分为16个区域或段,[0H-FH]。每段256MBytes。地址的上4位选择特定的段。每个段的前16 kb可以使用绝对寻址访问。许多数据访问使用的地址是通过在基址寄存器的值上加一个位移来计算的。使用一个位移来跨越一个段边界是不允许的,如果尝试会导致一个MEM陷阱。这个限制允许从基址直接确定被访问的段。
物理内存属性
段0到7的物理内存属性是依赖于实现的。如果MMU存在并使能,段[0H - 7H]被认为是必须转换的虚拟地址。如果MMU不存在,则访问特性依赖于实现,并且可能导致trap。
物理内存地址
段F(H)中的物理内存地址保证是外设空间,因此所有访问都是非推测性的,并且不能在User-0模式下访问。核心特殊功能寄存器(CSFRs)映射到内存映射中的64kbytes空间。这个64kbytes空间的基本位置与实现有关。段8H到DH在某些实现中有进一步的限制。例如,程序和数据的特定段可以由特定于设备的实现来定义。内存映射的其他细节是具体实现的。

四、 信号量和原子操作
下面的指令以原子方式读取和/或写入内存:
LDMST (Load, Modify, Store)
SWAP.W(内存交换寄存器)
ST.T(存储位)
CMPSWAP.W
SWAPMSK.W
LDMST使用掩码寄存器将源寄存器中的选定位写入存储器字。然而,它不返回值,因此它不能用作二进制信号量的原子“测试和设置”类型操作。SWAP.W是为此目的而提供的。如果启用内存保护,则LDMST的有效地址为CMPSWAP.W, SWAPMSK.W,SWAP.W或ST.T指令必须位于同时启用了读和写权限的范围内。
CMPSWAP.W指令有条件地用内存字交换源寄存器。SWAPMSK.W指令通过掩码将源寄存器的内容与内存字交换。原子指令的执行强制所有数据访问在该指令之前完成。这确保了在原子操作之前将任何缓冲状态写入内存。
五、寻址模式
寻址模式允许加载和存储指令访问简单的数据元素,如记录、随机和顺序访问的数组、堆栈和循环缓冲区。
简单数据元素的宽度为8位、16位、32位或64位。该架构支持七种寻址模式。
寻址模式支持C/ c++的有效编译,方便地访问外设寄存器,并有效地实现典型的DSP数据结构(滤波器的圆形缓冲区和FFTs的位反转索引)。

硬件不直接支持的寻址模式可以通过短指令序列合成。
指令格式
指令格式为绝对寻址提供尽可能多的地址位,为基地址+偏移寻址提供尽可能大的偏移范围。
编程模型
地址寄存器可能既是加载的目标,也是与特定寻址模式相关联的更新的目标。例如,在以下情况下,地址寄存器的内容不是体系结构定义的:
ld.a a0, a0 + 4
类似地,考虑以下情况:
st.a (+ a0) 4、a0
A[0]的原始值或更新值是否存储到内存中,在体系结构上没有定义。这对于所有需要更新地址寄存器的寻址模式都是正确的。
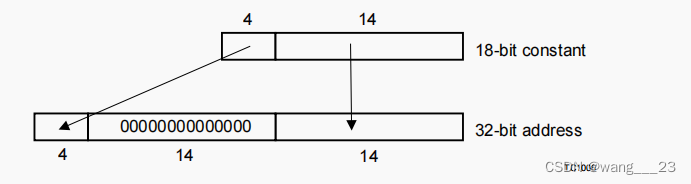
1、 Absolute Addressing
绝对寻址对于引用I/O外设寄存器和全局数据很有用。
绝对寻址使用指令指定的18位常量作为内存地址。完整的32位地址是通过将18位常量中最有效的4位移动到32位地址的最有效位而得到的。其他位是零填充的。
2 、Base + Offset Addressing
基地址+偏移寻址对于引用记录元素、局部变量(使用堆栈指针(SP)作为基数)和静态数据(使用指向静态数据区域的地址寄存器)非常有用。完整有效地址是地址寄存器和符号扩展的10位偏移量的总和。
内存操作的一个子集提供了基地址+长偏移寻址模式。在这种模式下,偏移量是一个16位的符号扩展值。这允许使用两条指令序列对内存中的任何位置进行寻址。
3 、Pre-Increment and Pre-Decrement Addressing
预递增和预递减寻址(其中预递减寻址是通过使用负偏移量),可分别用于推入向上或向下增长的堆栈。预增量寻址模式使用地址寄存器和偏移量的总和作为有效地址和写入地址寄存器的值。
4 、Post-Increment and Post-Decrement Addressing
后增量寻址和后递减寻址(通过使用负偏移量获得后递减寻址)可分别用于向前或向后顺序访问数组。此外,该模式的两个版本可分别用于从向下增长或向上增长的堆栈弹出。后增量寻址模式使用地址寄存器的值作为有效地址,然后通过将符号扩展的10位偏移量添加到之前的值来更新该寄存器。
5、 Circular Addressing
循环寻址的主要用途是在执行过滤器计算时访问循环缓冲区中的数据值。

循环寻址模式使用一个地址寄存器对来保持它所需的状态:
偶数寄存器总是基址(B)。
奇数寄存器的最重要的一半是缓冲区大小(L)。
最低有效的那一半将索引保存到缓冲区(1)中。
有效地址为(B+l)。
缓冲区占用地址B到地址B+L-1之间的内存。
使用以下算法对索引进行后加:

10位偏移量是在指令字中指定的,它是一个字节偏移量,可以是正的,也可以是负的。请注意,只要偏移量的大小小于缓冲区的大小,就保证正确的“绕行”行为。
为了说明循环寻址的使用,考虑一个由25,16位值组成的循环缓冲区。如果当前索引为48,则使用两个偏移量(每个值2字节)获得下一项。索引的新值“环绕”为零。如果索引为48,并且使用偏移量为4,则索引的新值为2。如果当前索引为4,并且我们使用偏移量为8,则新索引为46(4-8+50)。
在结束的情况下,内存访问在循环缓冲区的末尾运行,数据访问也绕到缓冲区的开头。例如,考虑一个包含n+1个元素的循环缓冲区,其中每个元素是一个16位的值。如果使用循环寻址模式执行加载字,并且操作的有效地址指向元素n,则32位的结果在底部16位中包含元素n,在顶部16位中包含元素0。
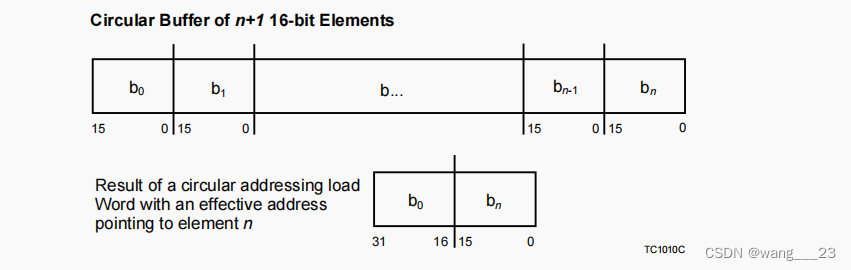
循环缓冲区的大小和长度有以下限制:
缓冲区的开始必须与64位边界对齐。实现可以自由地建议用户对圆形缓冲区等进行最佳对齐,但必须支持对64位边界的对齐。
缓冲区的长度必须是数据大小的倍数,其中数据大小由用于访问缓冲区的指令决定。例如,使用加载字指令访问的缓冲区的长度必须是4字节的倍数,使用加载双字指令访问的缓冲区的长度必须是8字节的倍数。
如果不满足这些限制,则实现会出现对齐陷阱(ALN)。如果索引(I) >=长度(L),也会产生对齐陷阱。
不允许使用循环寻址访问外围空间。这样的访问将导致一个MEM陷阱。
6 、Bit-Reverse Addressing
位反向寻址用于访问FFT算法中使用的数组。最常见的FFT实现以比特反向顺序存储结果结束
位反向寻址使用一个地址寄存器对来保持所需的状态

偶数寄存器是数组(B)的基址。
奇数寄存器的最低有效部分是数组(1)的索引。
最重要的一半是修饰符(M),用于在每次访问后更新I。
有效地址为B+l。
索引I是后加的,它的新值是反向的[反向(I) +反向(M)]。逆(I)函数将位n与位(15-n)交换为n=0,…7。
为了说明使用16位值的1024点真实FFT,缓冲区大小为2048字节。使用位反向索引遍历该数组将得到字节索引的序列:0、1024、512、1536,等等。这个序列可以通过初始化I为0,M为0400H得到。


M的所需值由;缓冲区大小/2表示,其中缓冲区大小以字节数给出。
7 、Synthesized Addressing Modes
本节描述如何通过短指令序列合成硬件寻址模式中不直接支持的寻址。
索引寻址
索引寻址模式可以使用ADDSC进行合成。一条指令(向地址添加缩放索引),它将一个缩放数据寄存器添加到地址寄存器中。对于寻址由字节、半字、字或双字组成的索引数组,比例因子可以是1、2、4或8。
位索引寻址
为了支持索引位数组的寻址,ADDSC.AT指令将索引值缩放1/8(右移3位),并将其添加到地址寄存器中。结果字节地址的两个低阶位被清除,以给出包含索引位的字的地址。
为了提取比特,需要加载包含比特的字。然后在EXTR.U指令中使用位索引。从索引位位置开始的位域也可以被提取。在索引位位置存储位或位字段。AT与LDMST(加载/修改/存储)指令一起使用。
PC-Relative寻址
PC-Relative寻址与pc相关的寻址是分支和调用的正常模式。然而,该体系结构不支持直接与pc相关的数据寻址。这是因为单独的片上指令和数据存储器使得对程序存储器的数据访问非常昂贵。
当需要对数据进行pc相对寻址时,将附近代码标签的地址放入地址寄存器中,并以基+偏移模式用作基寄存器来访问数据。一旦基本寄存器被加载,它就可以用来寻址附近其他与pc相关的数据项。
代码地址可以用多种方式载入地址寄存器。如果代码是静态链接的(嵌入式系统几乎总是这样),那么代码标签的绝对地址是已知的,可以使用LEA指令(加载有效地址)加载,或者使用一个序列加载扩展的绝对地址。PC相对数据的绝对地址也是已知的,不需要合成PC相对寻址。
对于动态加载的代码,或者在没有重定位链接器的情况下从位置无关的片段组装成二进制映像的代码,加载用于pc相关数据寻址的代码地址的适当方法是使用JL(跳转和链接)指令。执行跳转并链接到下一条指令,将该指令的地址放入返回地址(RA)寄存器A[11]。在此之前,有必要将当前函数的实际返回地址复制到另一个寄存器中。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









